行銷活動利潤模型與最佳決策點分析【管理意涵篇】
(附 Python 程式)
在系列四(連結請點此),筆者帶領讀者解決了第三個問題-「到底哪些才是高購買率的消費者? 又如何建構「接地氣」的方案?」,我們產出了顧客精準行銷清單,但到此專案即完成了嗎?本系列將帶領讀者解決第四個問題-「如何自動評估精準行銷帶來的潛在財務效果? 同時讓主管們也都聽得懂?」 。
讀者可從下述QR code或從github repository鏈接中找topic01_ai_marketing資料夾,將topic01_ai_marketing複製(clone)下來,一起隨筆者實作程式碼。

筆者將分別從資料科學與業界的角度來闡述「模型表現」。先從資料科學的角度來看,透過程式碼7的評估,筆者很容易就可以得知本模型在準確度上表現達近83%,即有83%的比例模型成功預測不購買與購買的顧客。
Jasper回應:「哦哦!這樣的命中率看起來不錯哦!但是請問有沒有更直觀一點的表示方式呢?怕老闆與同仁他們還是聽不懂啊!」
程式碼7
# %% # SECTION - 程式碼7 # 資料科學角度評估模型表現
# 準確度
print(accuracy_score(y_test, y_pred))
# !SECTION – 程式碼7
程式碼7的產出
0.8278239349478522
還記得筆者之前在程式碼4有算過訓練資料集中,行銷所有顧客後,大約僅有10%的顧客會購買筆者的A商品嗎?這次一樣計算一下行銷測試資料集所有人後,會有多少人有意願購買A商品,從程式碼8的產出得知為17.78%。
程式碼8
# %%
# SECTION - 程式碼8
# 混淆矩陣評估模型表現
# 首先評估測試資料集真正購買A商品顧客佔所有資料的比例
marketing_all_consumer = round(y_test.value_counts()[1]/len(y_test), 4)
print('真正購買A商品顧客佔所有資料的比例', marketing_all_consumer * 100, '%')
# !SECTION - 程式碼8程式碼8的產出
真正購買A商品顧客佔所有資料的比例 17.78 %
筆者採用了機器學習模型後,即對有高機率購買者行銷,相較原先海撒全部顧客行銷方法來說,模型行銷成功的比例可以達到52.27%,增加了近2.94倍的提升成效(lift),如程式碼9的產出所示。
這代表從資料科學的角度來看,本機器學習模型確實有提升原有行銷方法的成效,並且提高近3倍的成效。
程式碼9
# %%
# SECTION - 程式碼9
# 先做出混淆矩陣
model_conf = confusion_matrix(y_test, y_pred)
plot_confusion_matrix(model_conf,
classes=['No', 'Buy'],
title='Confusion matrix',
cmap=plt.cm.Reds
)
# 行銷成功的比例可以達到多少呢?
ps = precision_score(y_test, y_pred)
print('行銷成功的比例', round(ps, 4) * 100, '%')
# 相較原先海撒全部顧客行銷方法來說,用了模型之後,提升了多少成交比呢?
lift = round(ps / marketing_all_consumer, 2)
print('提升了', lift, '倍')
# !SECTION - 程式碼9程式碼9的產出
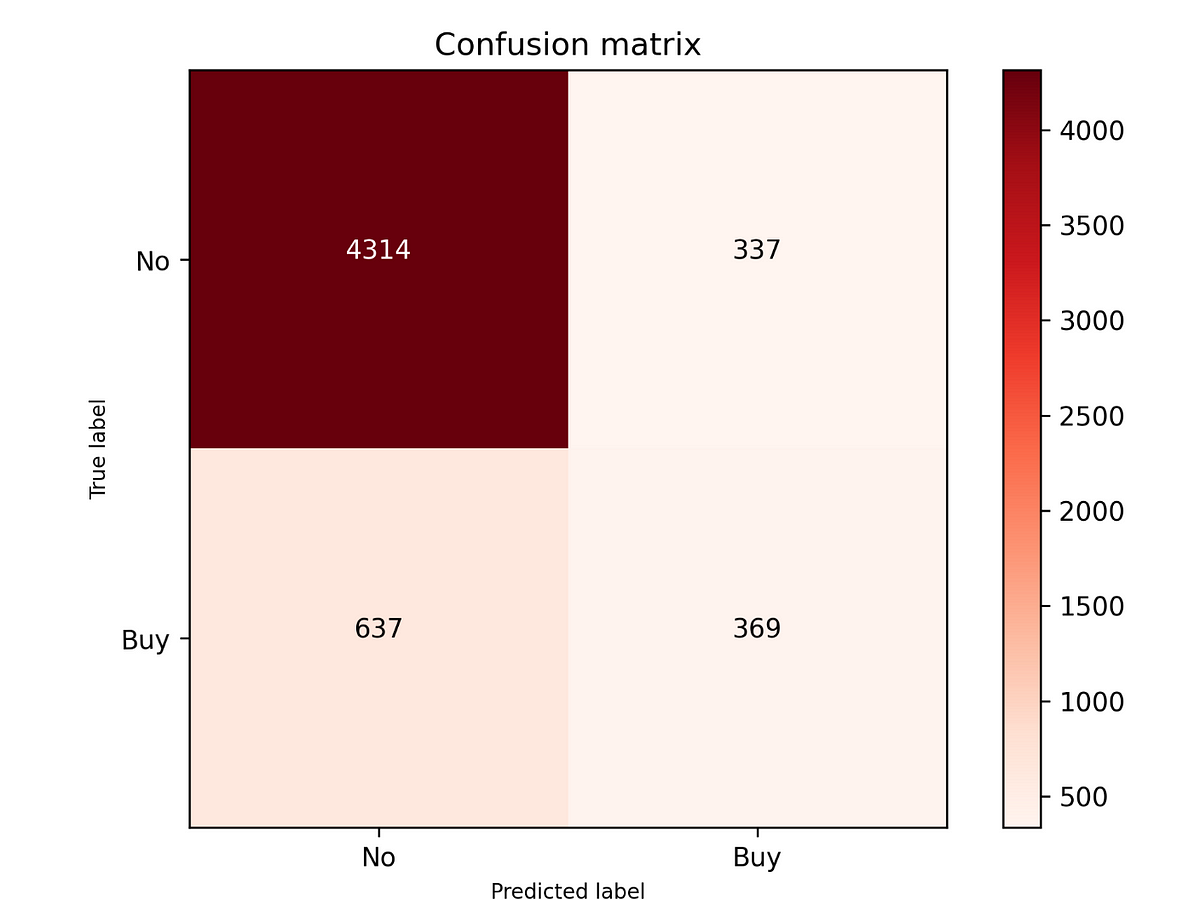
行銷成功的比例 52.27 %
提升了 2.94 倍
至於模型行銷成功的比例如何計算呢?在程式碼9的產出成果中,有一張名為confusion matrix的圖,橫軸的predicted label分為預測會購買的顧客(Buy)與不會購買的顧客(No),圖中顯示模型預判共706人(369+337)會至少有50%的購買意願(購買機率)來購買A商品,故請行銷人員對其706人開始行銷。最後在706人中,僅有369人真正買單,其比例為52.27%,意味每行銷2人就有1人會買單,這相較原本僅17.78%,即行銷6人才約1人買單來說,高出近2.94倍,而這也是資料科學界與零售界中鼎鼎大名的提升度(Lift)(Brin et al., 1997)算法。
Jasper繼續回饋:「看起來我知道使用機器學習來做精準行銷的方法比原本的方法還要好約3倍!但有沒有更能讓老闆與同仁都更了解的方法呢?」
接著就來到業界的角度來評估模型表現的環節了!讀者還記得筆者在前面有提及「分析的情境個案」資訊嗎? 其中包含了A商品的財務架構,諸如:價格、成本與行銷費用。使用程式碼10即可將本次專案的A商品財務架構考量進機器學習模型中並產出「行銷全部顧客的利潤結果」(XGB全市場行銷利潤矩陣.csv)與「善用模型執行精準行銷的利潤結果」(XGB模型行銷利潤矩陣.csv)。
程式碼10
# %% # SECTION - 程式碼10 # 行銷活動利潤評估 XGB_all_df, XGB_model_profit_df, XGB_y_test_df = model_profit_fun( clf=XGBClassifier(n_estimators=500, tree_method="hist", enable_categorical=True, random_state=0, nthread=8, learning_rate=0.05, ), # sklearn的模型 X_train=X_train, # 訓練資料集 X:training set (x) y_train=y_train, # 訓練資料集 Y:training set (buy) X_test=X_test, # 測試資料集 X : testing set (x) y_test=y_test, # 測試資料集 Y : testing set (buy) test_uid = test_uid, # 測試資料集 UID sales_price=2500, # 價格 marketing_expense=185.32, # 行銷費用或銷貨成本 product_cost=1215.2, # 產品成本 plot_name='XGB_A商品_') # 產出結果的名稱,會存到資料夾 # !SECTION - 程式碼10
程式碼10的產出
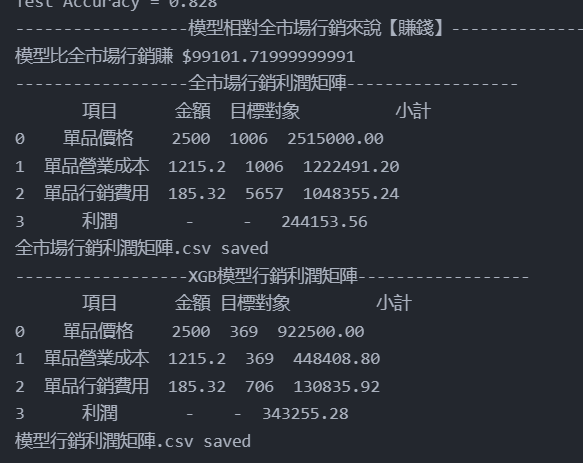
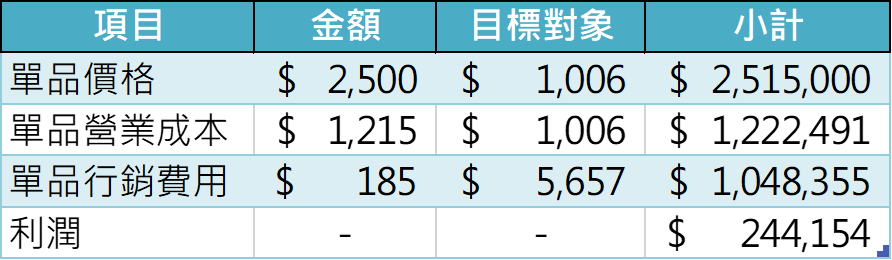
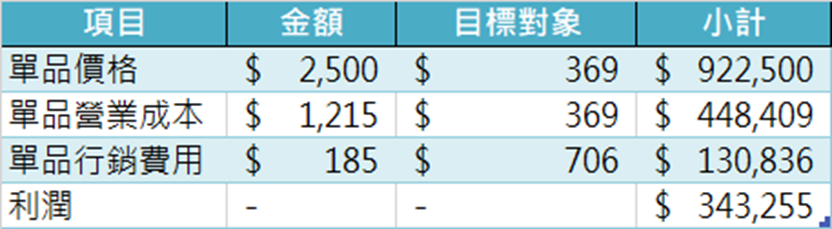
從圖1中,筆者可以更清楚知曉在執行5657人的行銷活動下,左圖行銷全顧客的營收達到250萬左右,但其行銷費用卻來到了100萬,雖然廣告投報率(ROAS)達到2.5倍左右,即投入約100萬的行銷費用,創造約250萬的營收,但是總體的利潤率僅有約10%;反觀右圖以模型執行精準行銷的營收雖為92萬左右,但其行銷費用僅約13萬,其ROAS可達到7左右,且總體的利潤率竟有37%。這代表精準行銷方法不但能降低人員行銷費用,同時增加利潤,達到開源賺錢與節流省錢之效果。
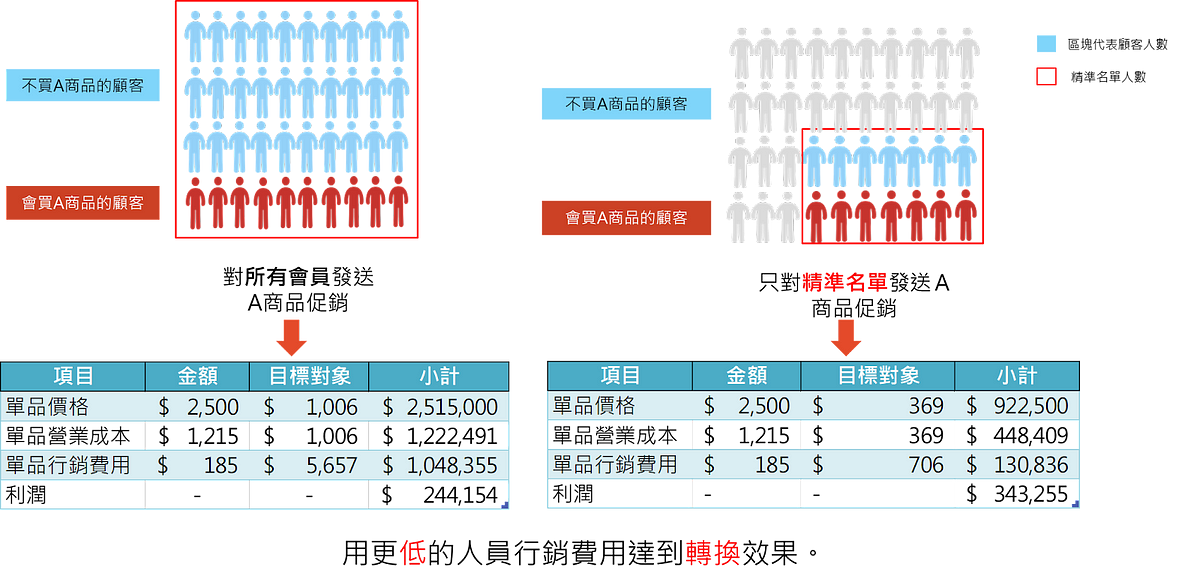
Jasper接著回饋:「哇!太棒了!這樣才對!老闆最愛錢了!這樣說明老闆才聽得懂筆者做了些什麼嘛!」
Jasper立刻又問到:「這706人挑選出來是很好,不過我怎麼記得您是根據至少有50%的購買A商品意願(機率)的顧客來挑選的? 現在既然已經有A商品的單一財務架構,有沒有機會找到一個特定的顧客購買機率,讓利潤最大化呢?」
此時筆者可以根據程式碼6的「顧客精準行銷清單」來比對在哪一顧客對A商品預測購買機率下,實際成交的利潤額最高。接著透過程式碼11窮舉所有利潤最大化的可能性。最後得知在本案中,凡顧客的預測購買機率大於或等於19%,則建議行銷人員要對該顧客行銷,則可獲$549,314之利潤成效,相較圖1中的右圖僅向50%以上購買機率的顧客行銷來說,其利潤高出了$206,059($549,314-$343,255),即1.6倍,如程式碼11的產出所示。
程式碼11
# %% # SECTION - 程式碼11 # 畫出XGB利潤折線圖 profit_linechart( y_test_df=XGB_y_test_df, # 顧客精準行銷清單 sales_price=2500, # 價格 marketing_expense=185.32, # 行銷費用 product_cost=1215.2, plot_name='XGB_product A_') # !SECTION - 程式碼11
程式碼11的產出
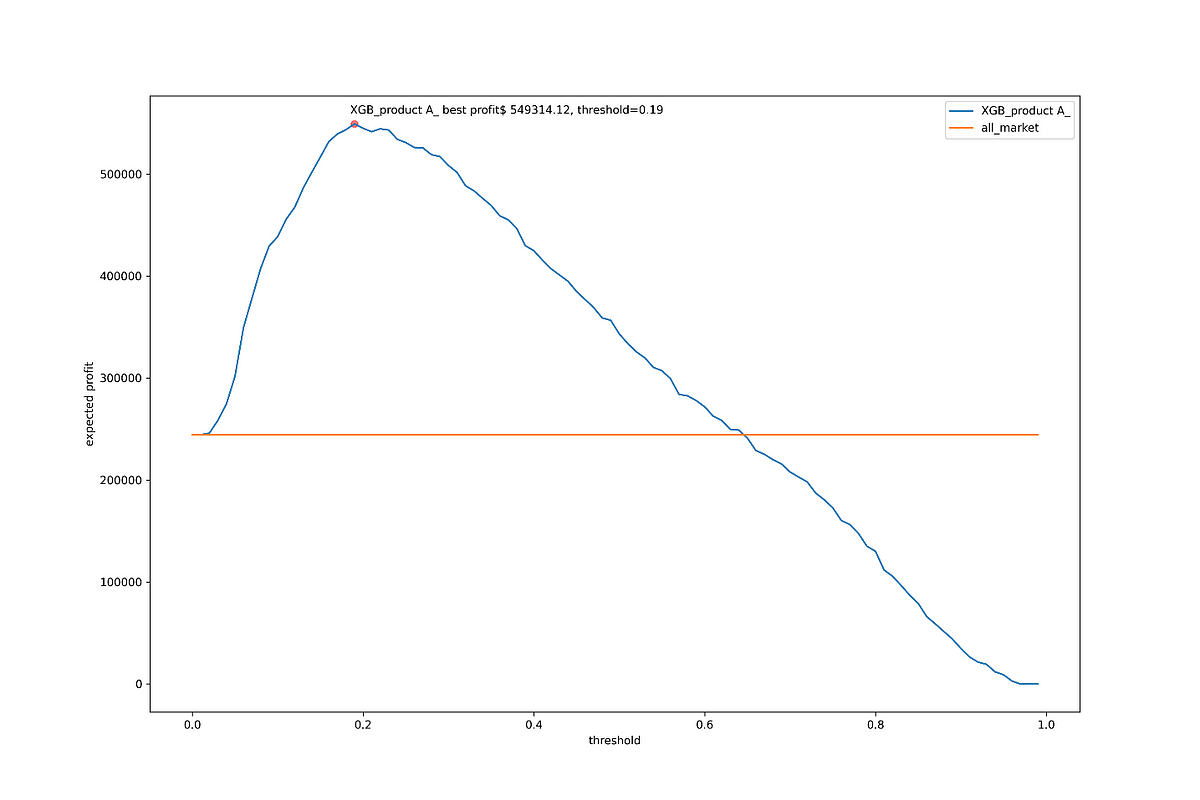
Jasper回饋:「原來如此!這樣不但可向主管說明具體成效且又協助公司開源節流,一舉多得!」
下個系列即來到本主題的最後一個系列,筆者將從不同角度,例如:高階管理者、第一線人員等來綜整本案結論,請讀者敬請期待!
以下筆者綜整了本主題各系列的連結以及主題總頁的連結,歡迎讀者取用!
系列六:行銷活動利潤模型與最佳決策點分析【總結篇】
系列七:行銷活動利潤模型與最佳決策點分析【後記】
主題總頁:AI行銷學實作篇故事情境介紹 & AI行銷學分析工具應用實戰
References
Akerkar, R. (2019). Artificial intelligence for business. Springer.
Brin, S., Motwani, R., Ullman, J. D., & Tsur, S. (1997). Dynamic itemset counting and implication rules for market basket data. ACM SIGMOD Record, 26(2), 255–264. https://doi.org/10.1145/253262.253325
