在系列三(連結請點此),筆者帶領讀者解決了第二個問題-「如何用高層、中階主管、執行夥伴聽得懂的話,來實踐精準行銷?」,透過資料&管理金字塔,協助 Jasper 更加確認本案目的是否有與各階層主管、夥伴對齊。本系列將帶領讀者解決第三個問題-「到底哪些才是高購買率的消費者? 又如何建構「接地氣」的方案?」 。
沒錯!完成了資料蒐集及組織溝通的任務後,就可開始資料分析的任務啦!從本節開始,讀者可從下述QR code或從下述github repository鏈接中找到topic01_ai_marketing資料夾,將topic01_ai_marketing複製(clone)下來,一起隨筆者實作程式碼。

在topic01_ai_marketing資料集中會發現有5個檔案,如圖1所示:
- Results:包含了本章節的所有產出,有興趣的讀者可以先以裡面的檔案配合文章一同查看。
- topic01_ai_marketing.py:為主要的Python執行檔案,請讀者可以直接打開這個檔案跟筆者一起操作與執行。
- ai_marketing_lib.py:為本案主要自製的Python套件檔案(library)。
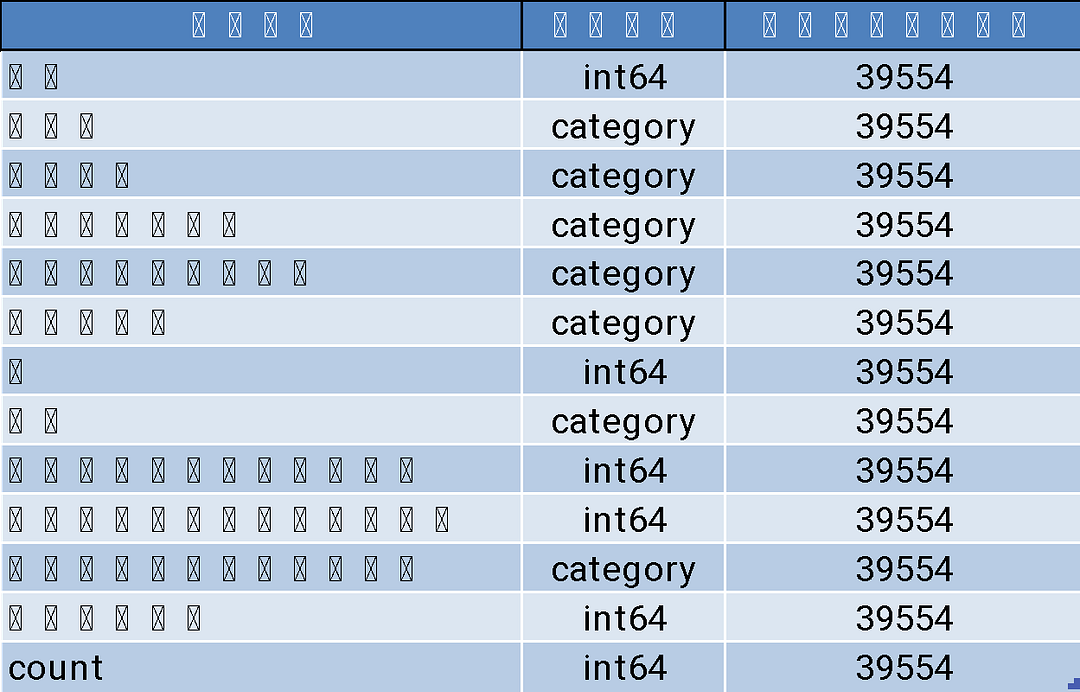
- marketing_ec_data_train.csv:為Jasper蒐集到的39,554筆原始顧客的CRM模擬資料。
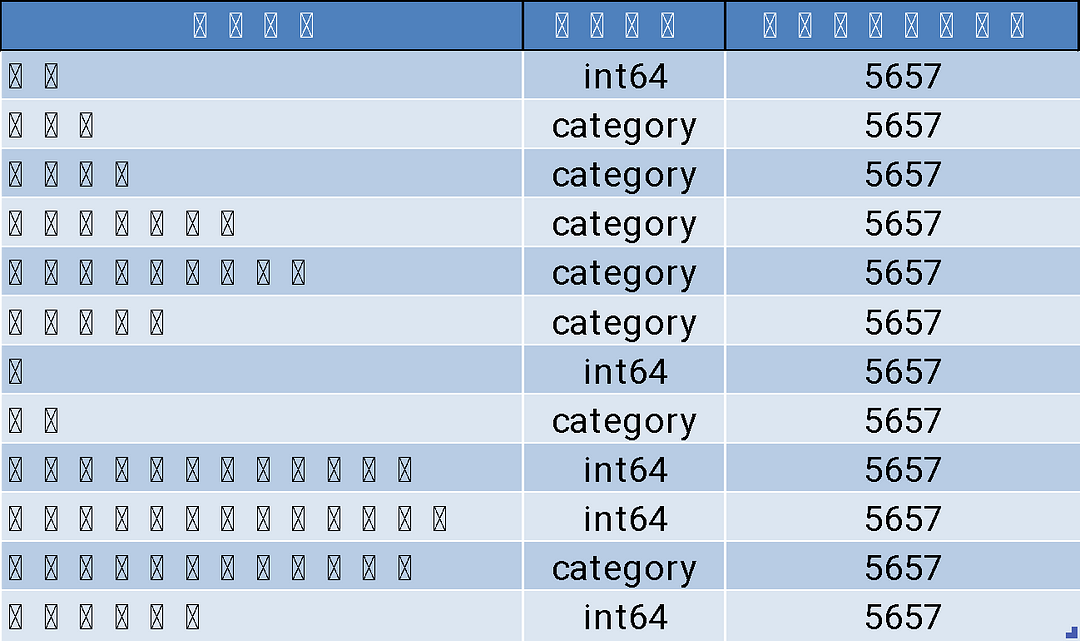
- marketing_ec_data_testing.csv:為Jasper主要用來測試精準行銷準確度用的CRM模擬資料,其含有5,657筆資料。

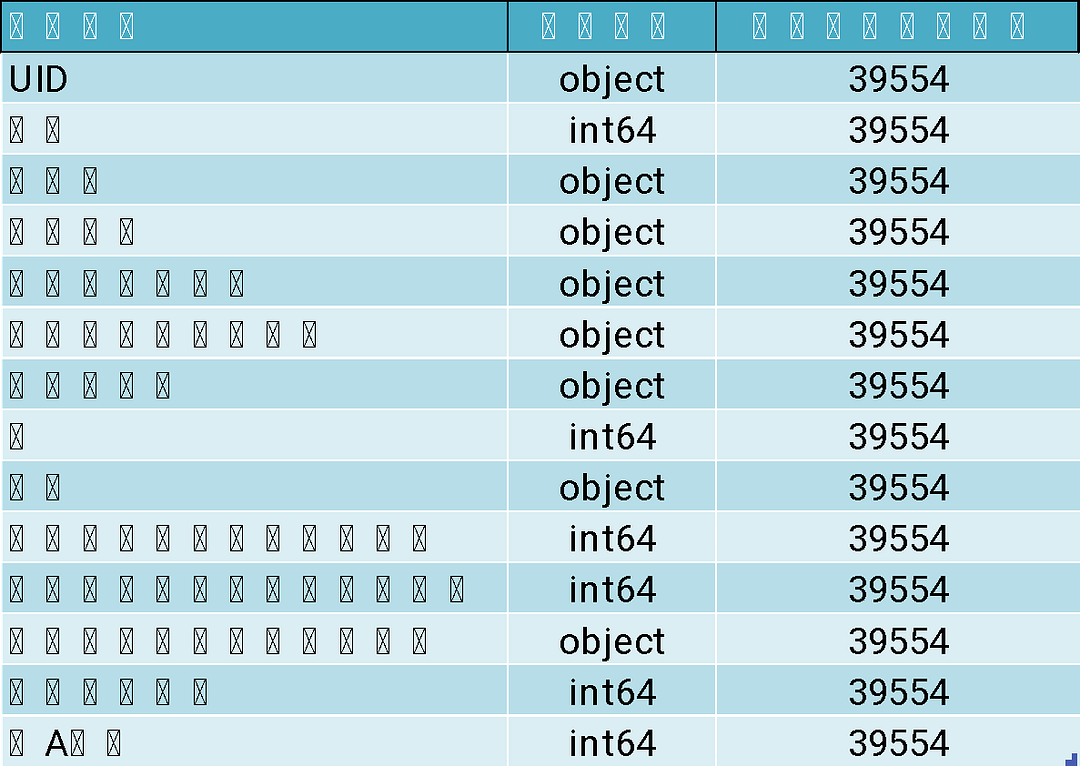
有了上述資料後,首要解決的問題為找出「高購買率的消費者」。請讀者先開啟topic01_ai_marketing.py,並讀入程式碼1,並產出其資料形態Excel表格,如程式碼1的產出所示。
# %%
# SECTION - 程式碼1
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, roc_curve, auc, confusion_matrix, r2_score
from ai_marketing_lib import model_profit_fun, profit_linechart
import matplotlib.pyplot as plt
from ai_marketing_lib import plot_confusion_matrix
import plotly.express as px
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
import pandas as pd
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
import numpy as np
from ai_marketing_lib import detect_str_columns, transform_to_category# 讀取marketing資料
data = pd.read_csv(‘marketing_ec_data_train.csv’)
data.info()
# 輸出data.info() –> 將data.dtypes 與 data.count() 合併
data_type = pd.concat(
[pd.DataFrame(data.dtypes), data.count()], axis=1).reset_index()
data_type.columns = [‘欄位名稱’, ‘資料型態’, ‘非空值的資料筆數’]
data_type.to_excel(’01_資料形態.xlsx’, index=False)
#!SECTION – 程式碼1
程式碼1的產出
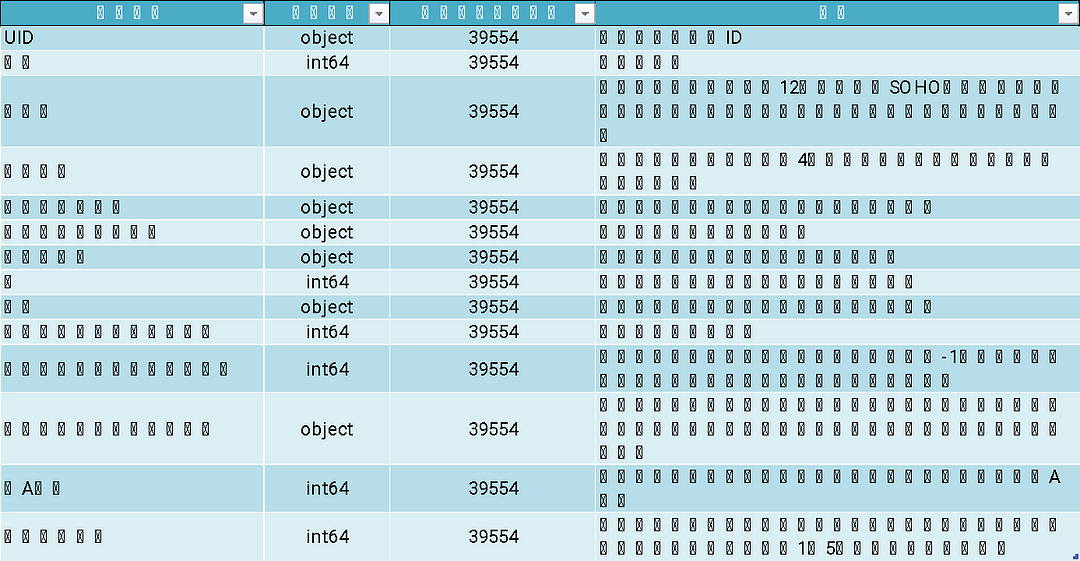
此時,可以依照需求在Excel表格中多新增一欄「說明」,讓所有為本專案執行資料科學任務的夥伴更加清楚其相關含義,如表1所示。
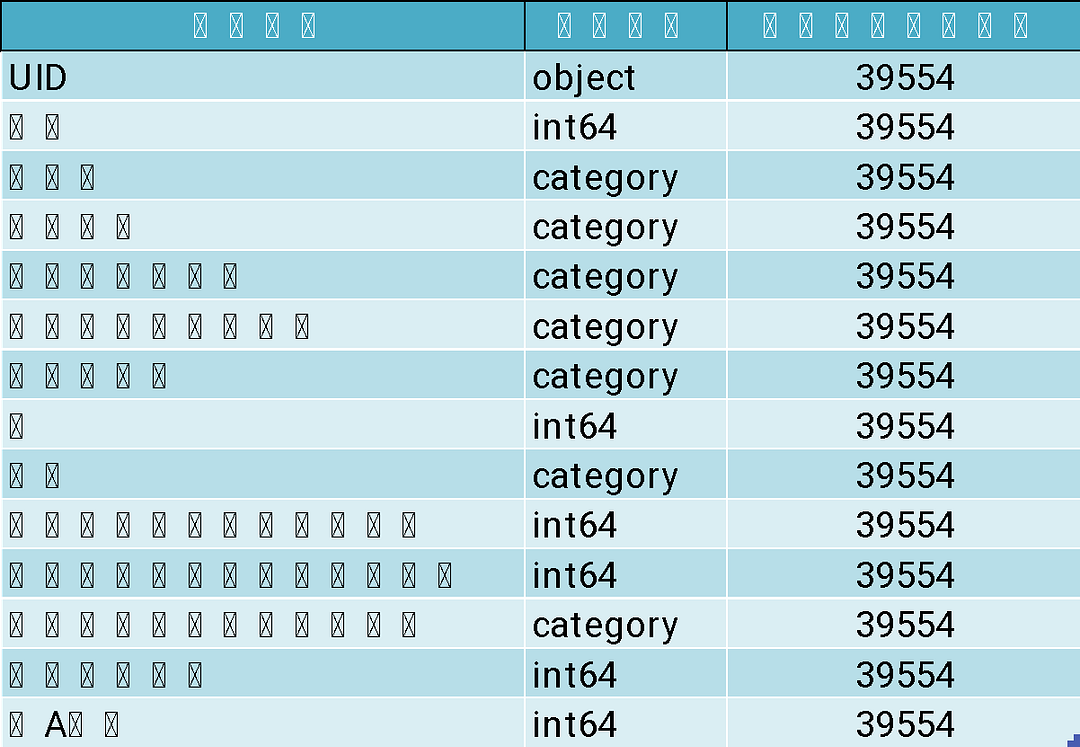
為了要讓資料能適當的放入機器學習演算法,筆者會適時的將字串欄位或稱字串變數,諸如:行業別、教育程度等表2資料形態為 object 的欄位轉換成數值形態(numerical data type)或類別形態(categorical data type),以利機器學習模型更好利用這些字串欄位。
本次教學主要將字串欄位轉換成類別形態,如程式碼2所示。接著,筆者再次查看程式碼2的產出成果,除了每位顧客獨有的 UID 外,其他字串變數均已轉換成類別變數,如此即可執行後續機器學習的分析。
# %%
# SECTION - 程式碼2
# 偵測有字串的欄位
str_columns = detect_str_columns(data.drop(columns='UID'))
dataset = transform_to_category(str_columns, data)# 確認全部都是數字 float, int, uint –> ML
dataset.info()
# 輸出【轉換後】data.info() –> 將data.dtypes 與 data.count() 合併
data_type = pd.concat([pd.DataFrame(dataset.dtypes),
dataset.count()], axis=1).reset_index()
data_type.columns = [‘欄位名稱’, ‘資料型態’, ‘非空值的資料筆數’]
data_type.to_excel(’02_【轉換後】資料形態.xlsx’, index=False)
#!SECTION – 程式碼2
程式碼2的產出
接下來,請讀者也將測試資料集的檔案同程式碼3的操作一般,也讀取並轉換其資料集。
# %%
# SECTION - 程式碼3
# 將測試資料也同樣讀取進來並執行資料轉換
# 讀取marketing資料
data_test = pd.read_csv('marketing_ec_data_testing.csv')
data_test.info()# 偵測有字串的欄位
str_columns = detect_str_columns(data_test.drop(columns=‘UID’))
dataset_test = transform_to_category(str_columns, data_test)
# 確認全部都是數字 float, int, uint –> ML
dataset_test.info()
#!SECTION – 程式碼3
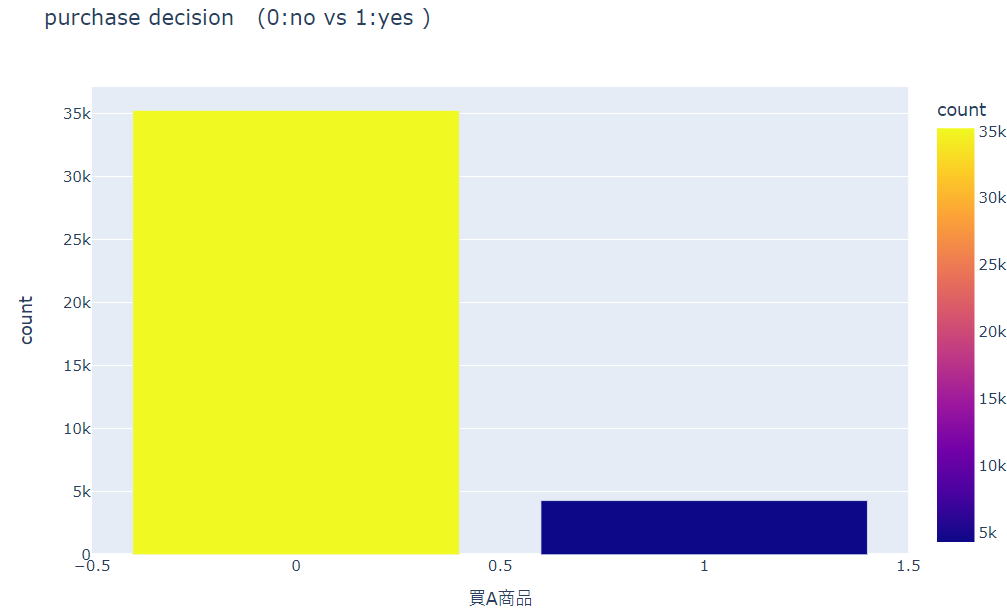
再來可以探查 Jasper 團隊行銷了39,554位顧客後,買單的比例究竟有多少。透過程式碼4,可在「買A商品」欄位中統計「購買」與「不購買」的佔比分別為多少,從程式碼4的產出結果可知僅有10%的顧客真正會買單A商品,讀者可以試著思考,行銷人需要行銷10位顧客,才有機會換得1位顧客的購買,簡言之,行銷人要判讀這10%真正會消費A商品的顧客是多麼的難,不過在後續卻可透過機器輔助的方式來協助人類判別高意願購買的顧客。
# %%
# SECTION - 程式碼4
# 繪圖:查看y變數的分佈圖
# Buy 比例
print('行銷顧客後卻不購買的比例', round(dataset['買A商品'].value_counts()
[0]/len(data) * 100, 2), '%')
print('行銷顧客成功而購買的比例', round(dataset['買A商品'].value_counts()[
1]/len(data) * 100, 2), '%')# 看看 y變數的分佈圖
dataset[‘count’] = 1
data_count = dataset.groupby(‘買A商品’, as_index=False)[‘count’].sum()
fig = px.bar(data_count, x=“買A商品”, y=“count”,
color=‘count’,
title=‘purchase decision \n (0:no vs 1:yes )’,
)
plot(fig, filename=‘purchase_decision.html’, auto_open=False)
#!SECTION – 程式碼4

在進入機器學習模型訓練前的資料前處理部分,筆者必須要先將目標變數「買A商品」或稱y變數與其他特徵變數或稱x變數分割開來,如程式碼5所示,以便筆者後續機器學習時,可使用x變數來對y變數執行訓練,找出高意願購買A商品的顧客。
從程式碼5產出成果來看,得知之前在程式碼4所使用到的count過渡變數不應該要考量進本資料集中,所以即在程式碼5中刪除count變數,由此可知在資料處理完的每一步都建議讀者可以仔細檢閱是否有需要清理的資料。
# %%
# SECTION - 程式碼5
# 區分訓練資料集的X與y
X_train = dataset.drop(columns=['買A商品'])
y_train = dataset['買A商品']X_test = dataset_test.drop(columns=[‘買A商品’])
y_test = dataset_test[‘買A商品’]
# 保留UID
train_uid = X_train[‘UID’]
test_uid = X_test[‘UID’]
# 刪除UID
del X_train[‘UID’]
del X_test[‘UID’]
# 再次檢查X_train與X_test的資料型態
data_train_type = pd.concat(
[pd.DataFrame(X_train.dtypes), X_train.count()], axis=1).reset_index()
data_train_type.columns = [‘欄位名稱’, ‘資料型態’, ‘非空值的資料筆數’]
data_train_type.to_excel(’03_【訓練資料集_特徵變數】資料形態.xlsx’, index=False)
data_test_type = pd.concat(
[pd.DataFrame(X_test.dtypes), X_test.count()], axis=1).reset_index()
data_test_type.columns = [‘欄位名稱’, ‘資料型態’, ‘非空值的資料筆數’]
data_test_type.to_excel(’04_【測試資料集_特徵變數】資料形態.xlsx’, index=False)
# 刪除不需要的變數
if X_train.filter(regex=‘count’).shape[1] > 0:
X_train.drop(columns=X_train.filter(regex=‘count’), inplace=True)
print(X_train.columns)
# !SECTION – 程式碼5
程式碼5的產出
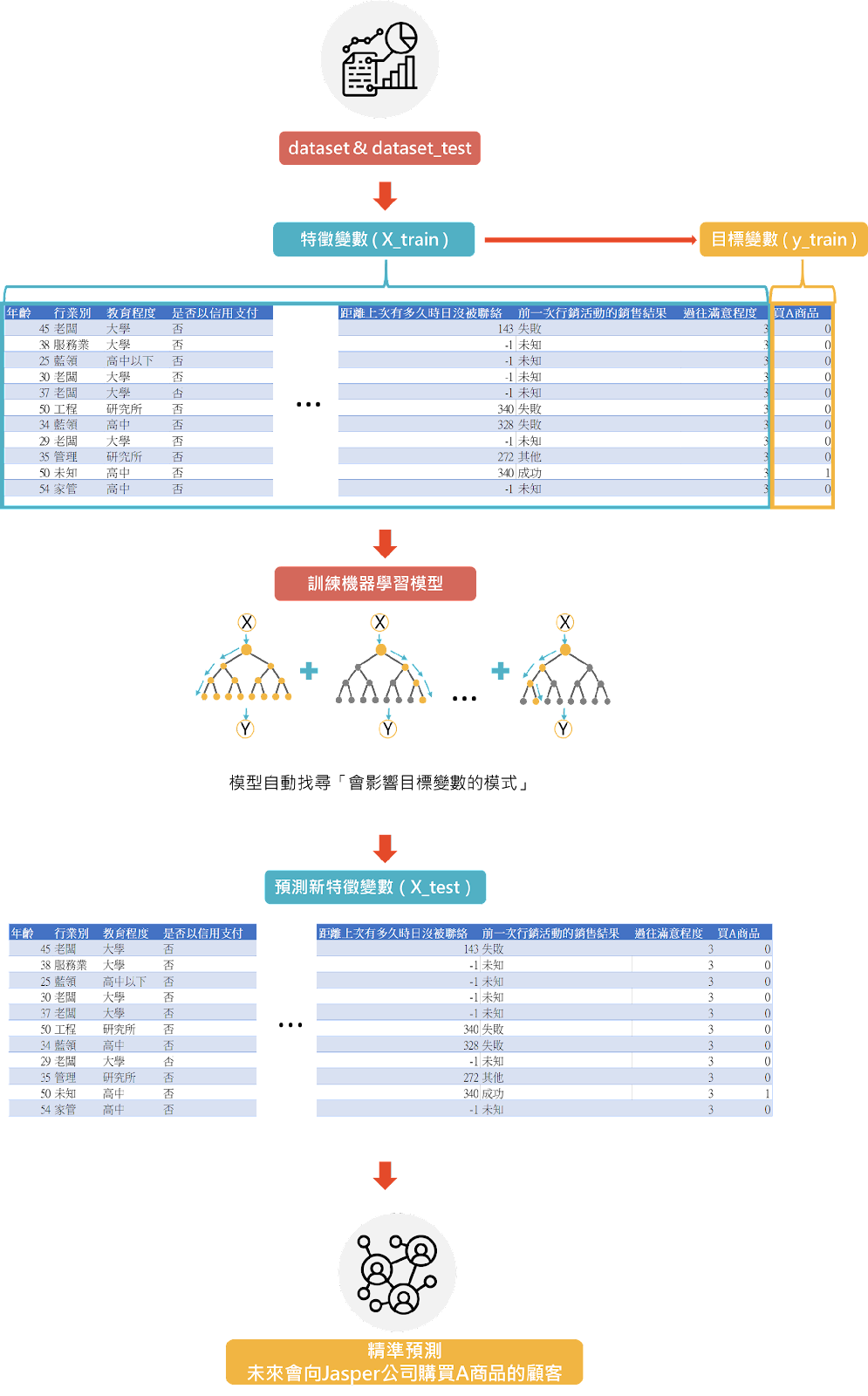
為了讓讀者更加瞭解機器學習模型與資料的關係,在此佐以圖26來解釋其關係。讀者可見除了「買A商品」為目標變數外,其餘變數均代表為可能會造成顧客購買A商品的「特徵變數」,故機器學習即是要從茫茫的特徵變數大海中找尋「會影響目標變數的模式」,以更好的精準預測未來會向 Jasper 公司購買A商品的顧客。
最後,善用程式碼6導入商務分析上經典的XGBoost機器學習模型,輕輕鬆鬆完成程式碼6的產出成果,即顧客精準行銷清單!
# %%
# SECTION - 程式碼6
# 訓練機器學習模型# 命名模型物件
clf = XGBClassifier(n_estimators=500,
tree_method=“hist”,
enable_categorical=True,
random_state=0, nthread=8,
learning_rate=0.05,
)
# 進行訓練
model_xgb = clf.fit(X_train, y_train, verbose=True,
eval_metric=‘aucpr’, eval_set=[(X_test, y_test)])
# 預測測試資料集的顧客購買與否
y_pred = model_xgb.predict(X_test)
# 預測測試資料集的顧客購買機率
y_pred_prob = model_xgb.predict_proba(X_test)[:, 1]
# 建構精準顧客名單
consumer_acc_list = pd.DataFrame(y_test.values, columns=[‘顧客對A商品【實際】購買狀態’])
consumer_acc_list[‘顧客對A商品【預測】購買機率’] = y_pred_prob
# 6. 將UID加回去顧客精準行銷名單
test_uid = test_uid.reset_index().drop(columns=[‘index’])
consumer_acc_list = pd.concat([test_uid, consumer_acc_list], axis=1)
# 7. 將精準顧客名單購買機率由大到小排序
consumer_acc_list = consumer_acc_list.sort_values(
by=‘顧客對A商品【預測】購買機率’, ascending=False)
consumer_acc_list = consumer_acc_list[[
‘UID’, ‘顧客對A商品【預測】購買機率’, ‘顧客對A商品【實際】購買狀態’,]]
consumer_acc_list[‘顧客對A商品【預測】購買機率’] = round(
consumer_acc_list[‘顧客對A商品【預測】購買機率’], 3)
# 8. 將精準顧客名單存成excel檔
consumer_acc_list.to_excel(’05_顧客精準行銷清單.xlsx’, index=False)
# !SECTION – 程式碼6
程式碼6的產出
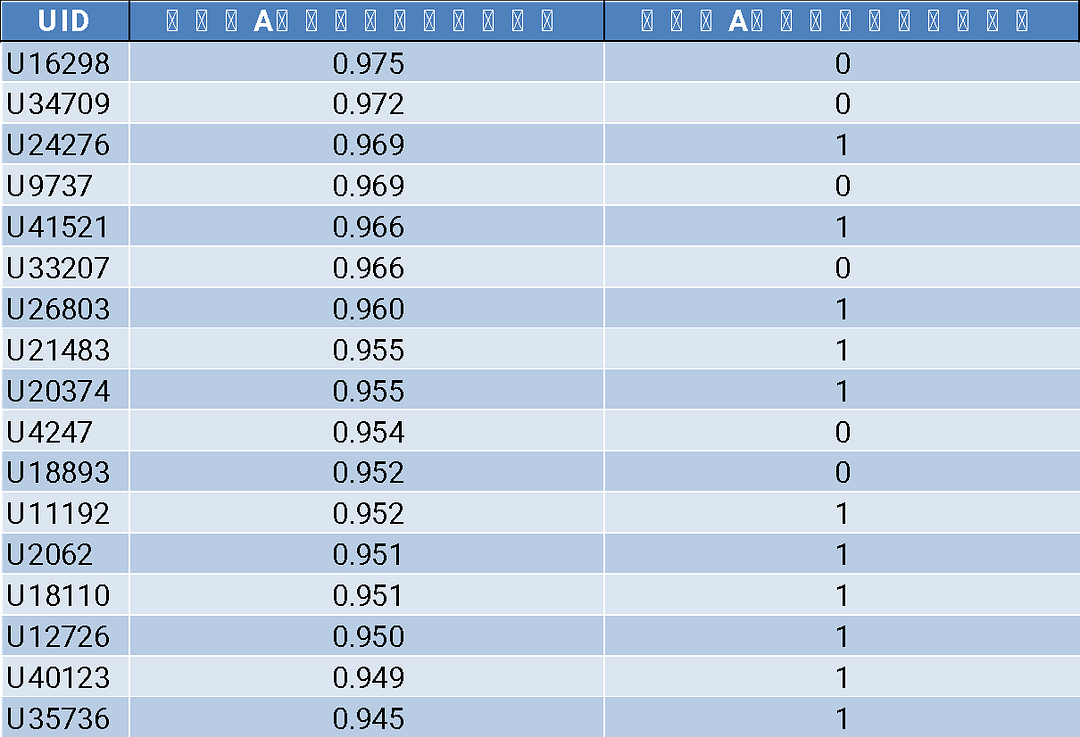
從顧客精準行銷清單裡,首先可從測試資料集的5,657名顧客中,得知每一位顧客對A商品【預測】購買機率,進而請第一線行銷人員對高意願購買A商品的顧客先行銷售A商品,以求用最低的行銷費用,達到精準行銷之成效,舉例而言:在程式碼6的產出清單中,行銷人員可對U16298、U34709與U24276三位顧客先行行銷,因為三位對A商品的購買機率分別為97.5%、96.2%與96.9%,當行銷人員完成對三者完成行銷後,會將最後顧客「最終」是否成交A商品的狀況記錄在「顧客對A商品【實際】購買狀態」的欄位中,從表中可見在人機輔助的努力下,其中一者最後果然成交。
Jasper 這時問:「經過這一輪的努力後,看起來不一定高機率的顧客最後都有成交耶?」
模型產出的購買機率即是「顧客購買的不確定性」,所以哪怕U16298這位顧客有接近97.5%的購買機率,仍有2.5%的可能性不會購買A商品。此外,模型的表現也是在精準行銷預測上很重要的考量因素。
Jasper 繼續追問:「原來如此!但是我還有幾個問題,雖然我現在有看似很強大的精準行銷武器(模型)了,但是我又該如何評估您所說的模型表現,同時讓主管買單呢?」
以下筆者綜整了本主題各系列的連結以及主題總頁的連結,歡迎讀者取用!
系列五:行銷活動利潤模型與最佳決策點分析【管理意涵篇】(附 Python 程式)
系列六:行銷活動利潤模型與最佳決策點分析【總結篇】
系列七:行銷活動利潤模型與最佳決策點分析【後記】
主題總頁:AI行銷學實作篇故事情境介紹 & AI行銷學分析工具應用實戰
作者:鍾皓軒(臺灣行銷研究有限公司 創辦人)、蔡尚宏(臺灣行銷研究 資料科學家)
繪圖者:黃亭維
