情境
根據全球知名的數據行銷公司Epsilon在2018年研究,發現市場上近八成左右的客戶傾向選擇具備個人化服務的商品[1]。在現今新興的生活形態下,如何同時兼備「即時性」與「個人化」的服務,已是企業追求的目標及顧客習慣的被服務的方式。
本情境是以Santander Bank為例,Santander Group的目標是希望搶先在顧客欲進行財務規劃前發覺潛在需求。透過各項顧客特徵變數預測出該顧客潛在的需求並提供對應的金融服務,達到超前部屬的效果。這也代表著該企業將以提供個人化服務方針為目標,預測每位客戶的潛在需求,進一步提供其更多金融服務選擇,提升潛在服務成交率。
目標:預測每一個顧客潛在交易價值,並期望大規模提供個人化服務

解決方法
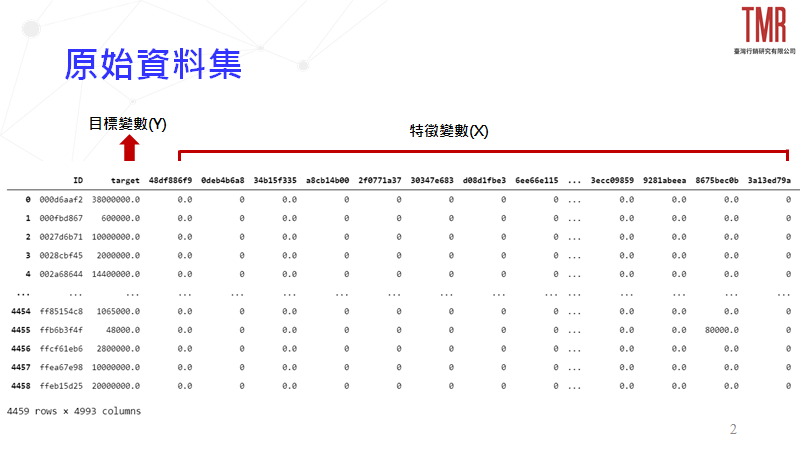
首先,我們可以先來查看使用訓練資料集的樣態,每一欄位都經過了去識別化的處理,總共有4,993個欄位,其中包含了1個客戶ID、1個目標變數(顧客潛在交易價值)及4,991個顧客資訊相關的特徵變數欄位,如圖1所示。
此外,我們發現特徵變數欄位大於訓練資料集的資料筆數,因此在後續資料處理部分,會建議謹慎的使用特徵選擇(Feature Selection)方式,降低資料維度,以及降低Overfitting的可能性,以建立較準確的模型。
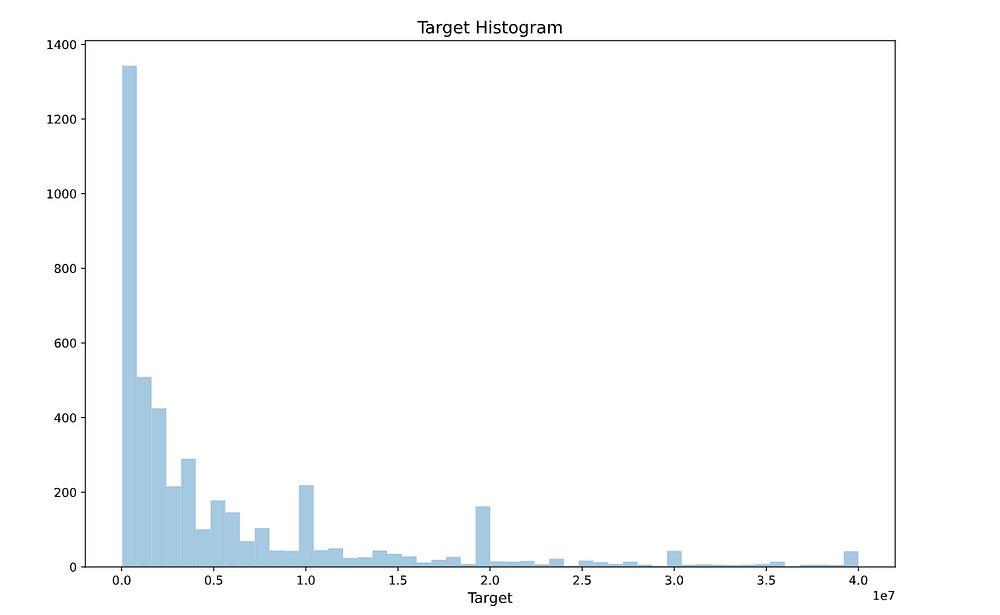
在此,我們透過直方圖的形式來查看目標變數(顧客潛在交易價值)的分布狀況,如圖2所示。圖中資料樣態呈現右偏,可以發現多數客戶的潛在交易價值都偏低。同時有些客戶的潛在交易價值卻高得嚇人,若以80/20法則來看,或許這些少數客戶的潛在交際價便占了總交易價值的八成,後續可將此群客戶列為首要目標。
由於上述狀況,故後面選擇損失函數時將使用RMSLE(均方根對數誤差),可以透過取Log這種遞減式遞增的特性以及開根號的方式,降低差距過大的問題。
對資料結構建立基礎認知後,這邊將在底下帶給大家資料處理的手法。
- 排除異常特徵變數欄位
由圖1可見大多數欄位都是0,若該特徵變數欄位中均為常數(全部的數值均為同一定值),則對分析上的貢獻將會相對較低,故在此將其排除。 - 找出與目標變數較為相關的特徵
透過Spearman Correlation找出相關係數大於0.1的特徵變數,進一步降低整體維度,藉由挑出與目標變數具備一定程度相關的組合,試著增加模型後續的預測準確度(在此為未使用Pearson的原因有二,第一為Pearson主要衡量線性相關,第二則是此資料在未符合常態分佈下Spearman相較比較合適) - 特徵選用(Feature Selection)
根據所挑選的模型進行訓練(在此使用Extra Trees Model),再透過特徵選用的方式評估欄位重要性。
最後,我們便可以針對此資料集進行建模的動作,步驟如以下呈現
1.透過LightGBM建立Baseline
到此或許會對兩件事情感到好奇
- 為什麼做機器學習一定要建立Baseline呢?
以考試及格分數60為例,目的就在於驗收學生學習成效,機器學習也不例外。而Baseline顧名思義,是在進行機器學習時心目中認定的底線,使用必要的資料前處理並套用相對簡易的方法產出。後續經過改良或套用不同的機器學習方法所產出模型,均會與其比較來查看是否有達成改善的效果,以及是否有Underfitting的問題存在。 - 為什麼在此選用LightGBM作為Baseline?
LightGBM兼具XGBoost的優點且在時間上又不會像XGBoost因預排序造成時間花費過長,而且在操作上也十分簡便,因此是個適合成為Baseline的方法之一,若想知道更多方法上介紹也可以參考此連結(將為各位簡單介紹Random Forest、XGBoost、LightGBM三個機器學習模組並附上進一步的paper供大家查看。
2.使用KFold Cross Validation,得到更好的成效
當我們重複寫同一種類似考卷時,通常成績也會逐漸上升。在機器學習也是同樣的道理,可以將整個資料分成五等份,分別訓練五次。每一次訓練均取不同等份作為驗證資料集,其餘四份作為訓練資料集,藉由這種重複訓練的概念使模型具備更好的預測效果。
成果與應用
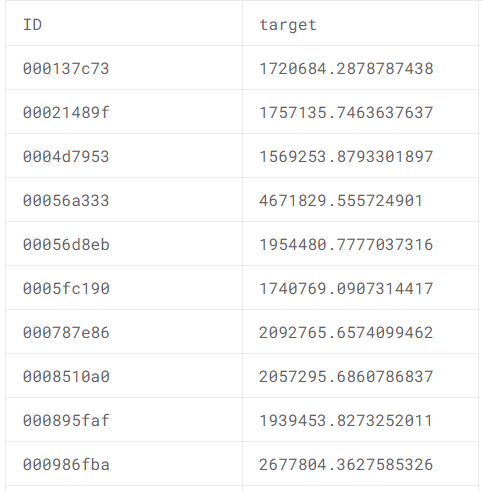
藉由相對節省時間的LightGBM作為模型Baseline,若想進一步增加模型成效則可執行K-fold。而重複訓練會使模型的預測效果更佳,下表一為「預測客戶潛在交易價值表」,其則是透過重複訓練的方式產出。藉此協助企業可以針對不同客戶,建立個人專屬金融服務,吸引顧客簽約,提高服務成交率。同時也能利用機器學習,有效提高金融業客戶體驗為公司創造更多價值。
本篇就到此結束囉
看完後,如果覺得喜歡,不妨幫忙拍個手 !
我們下次見~
參考資料
[1] New Epsilon research indicates 80% of consumers are more likely to make a purchase when brands offer personalized experiences
Simple Exploration + Baseline — Santander Value:
https://www.kaggle.com/sudalairajkumar/simple-exploration-baseline-santander-value/output
如何使用機器學習提高房仲業潛在成交率?進階資料處理面與基礎建模(附Python程式碼):
https://bit.ly/3hEte7b
作者:陳政廷(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究有限公司創辦人)
