系列 1與2 文章回顧
讓我們首先重點回顧上一篇系列1與2的文章 —
我們提到了:
- 案例介紹:
林曉美的A品牌「專業運動內衣」想要從市場突圍,因此找到臺灣行銷研究有限公司(就是我們TMR)的行銷資料科學團隊,欲從市場中找到藍海或差異化關鍵突破點。 - 市場區隔(Segmenting):
選定目標TA所在的蝦皮市場後,發現商城都會顯示「銷售數量」與「商品單價」,將便於我們計算運動內衣整體市場的總值,同時當消費者購買了該項商品,也就等同該商品「自動」幫消費者貼上了商品Tags,做為市場區隔的依據,進而為選擇目標市場打下良好的基礎。 - 目標市場(Targeting):
為了確保資訊正確性,我們還多從使用者的年齡層大約在25~45歲的PTT論壇中抓取相關的輿情文章。為這次蝦皮爬文下來的Tag進行交叉驗證,當做我們後續目標市場進入的考量關鍵,進而最終選定目標市場。 - 市場定位(Positioning):
決定目標市場後,透過不同動態定位圖的協助,找出可以進攻的藍海市場,真正找出商品的A品牌的市場定位。
系列1與2文章中還有提到使用的Python相關技術與管理意涵,歡迎讀者們可以先行參考看看系列1與2的文章哦:
【資料蒐集】Python網路爬蟲專案導向教學
工欲善其事,必先有「資料」!
在分析STP行銷策略前,我們必先取得「資料」方可開始分析,所以本章節會獨特的以「專案導向」的方式橫入Python網路爬蟲,再輔以本文的Jupyter notebook(嵌入連接)程式教學,希望讓讀者不僅能從文章中瞭解爬蟲基本概念,亦從Python程式實戰中實際體驗爬蟲的「快感」~!
接下來,讓我們用「批踢踢PTT」(台灣最大的BBS網站)爬蟲專案直搗Python爬蟲的概念!
Python爬蟲基礎架構圖
正式進入爬蟲專案前,我們要先簡要的理解「Python爬蟲基礎架構圖」(如圖1所示)。
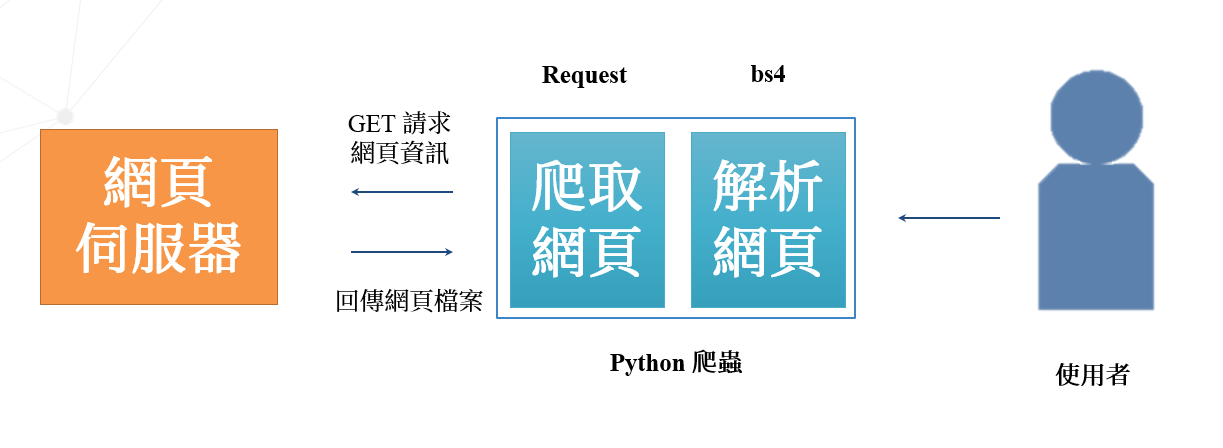
網頁伺服器
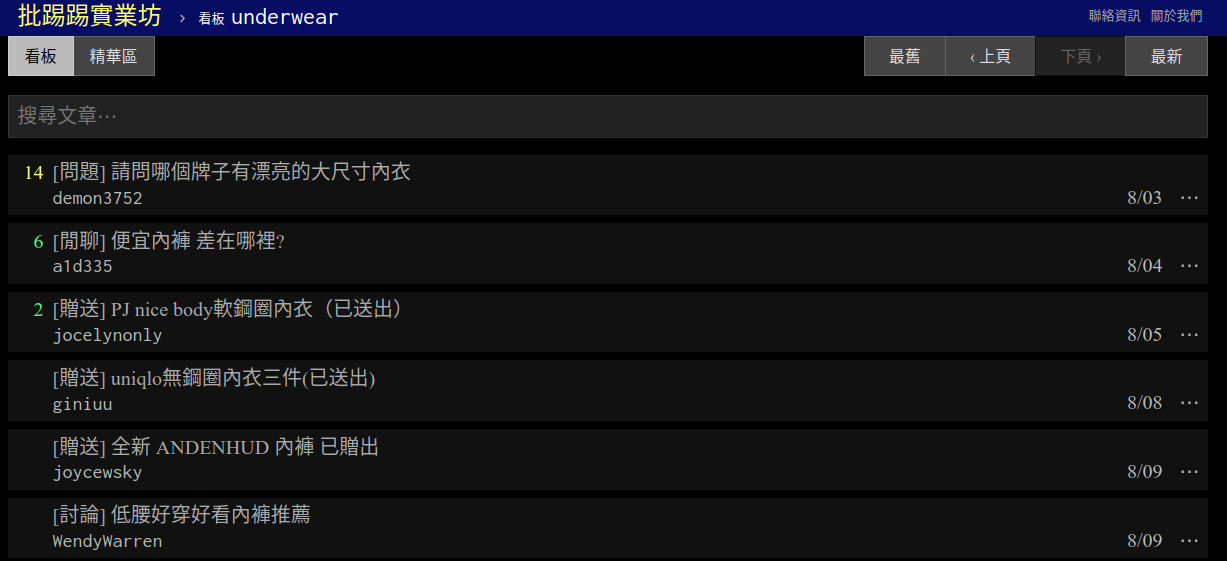
一般我們上網所查詢到的網頁,都會有一個伺服器在背後發送網頁資訊給使用者,讓我們能從網頁中取得我們想要的資訊,其實它的功能說白了就是「上網查資料時,伺服器會顯示網頁的內容」,如圖2所示。讀者也可以藉由本段網址進入我們即將要爬取的網頁:
PTT內衣版: https://www.ptt.cc/bbs/underwear/index.html
爬取網頁
有了網頁伺服器的概念後,我們開始用來理解並執行網路爬蟲啦! 簡單來說,即是「使用Python程式,解決我們人類在網頁上複製並貼上到資料表的工作」,舉例而言,如果我要抓取圖2的所有標題,就要手動一個個的複製下來,但若使用Python,則可以迅速且無誤的爬取所有標題,甚至是所有推文內容等我們肉眼在網頁上看到的任何資訊。
在商業論點上,若我們在無內部資料的狀況下,則有很大的潛在機會要使用「外部資料」,若我們具有有爬蟲相關技術,不但可以在短時間內大量爬取外部資料、節省人工抓取資料的成本,更可以爬取到「消費者爲中心」的重要輿情資料,以作後續的分析(哈哈~讀者閱覽到此,是不是資料還沒有爬取下來,就等不及想要知道後續怎麼分析呢? 放心後續的系列章節會詳細說明哦 XDDD!)
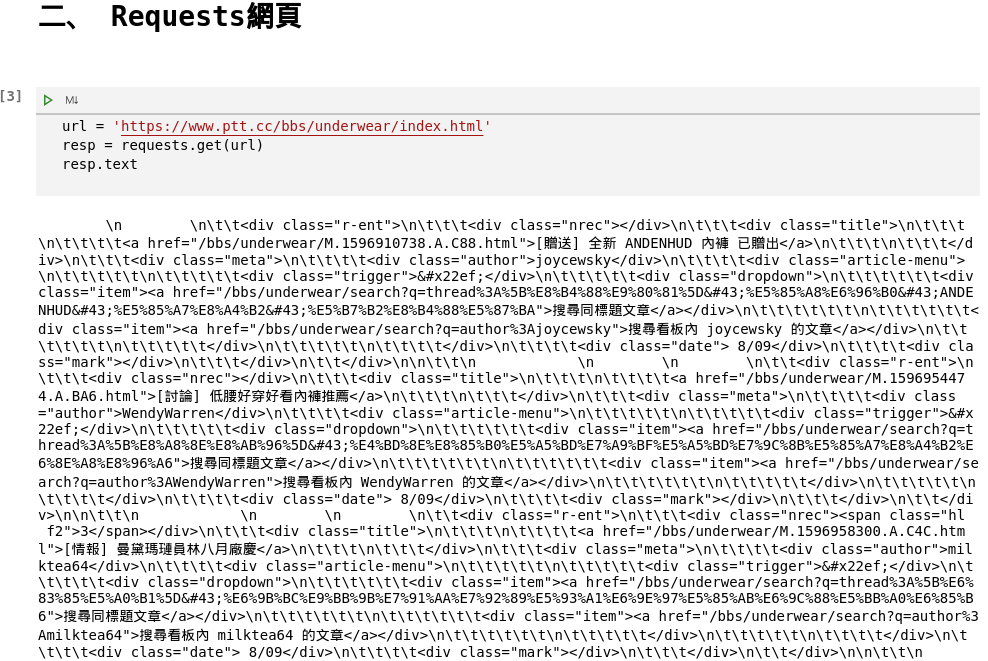
在技術實作上,我們會使用Python語言的request套件裏面的get功能來抓取我們要的網址(如圖3所示),接着可以使用text的方式呈現結果(如圖4所示)。

解析網頁
讀者們會發現圖4呈現的結果非常凌亂,導致我們很難從這麼如此凌亂的字串中找出我們要的資料,如標題等,所以這時候我們就會使用到bs4來爲我們解析網頁架構,從網頁中的蛛絲馬跡找出我們想要的資料!
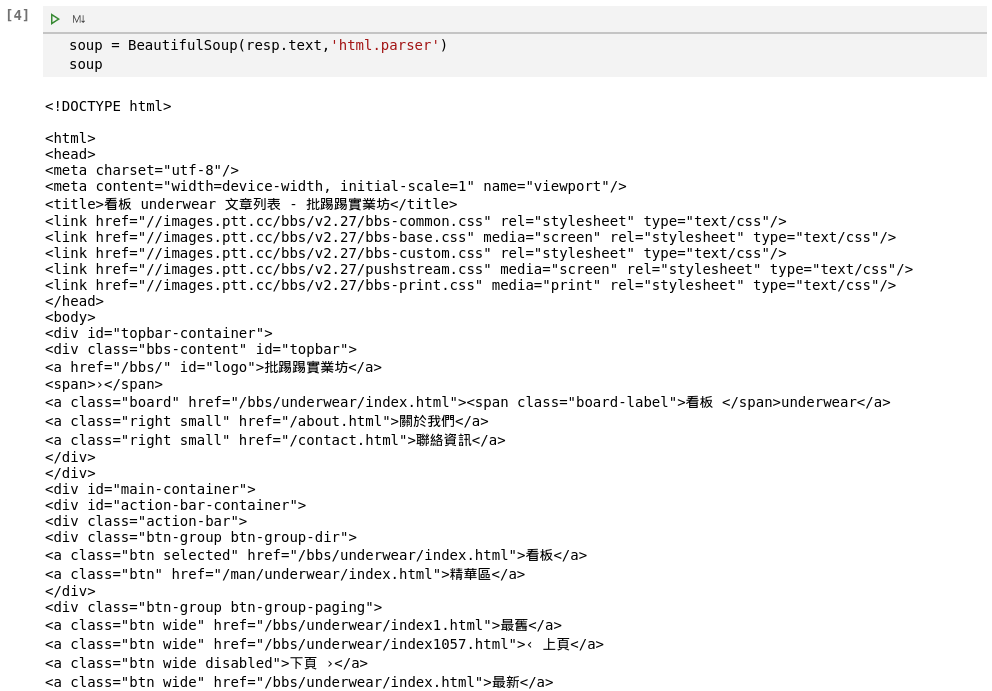
在技術實作上,我們會使用Python語言的bs4套件裏面的BeautifulSoup功能來解析我們爬下來的網頁(如圖5所示),並呈現令人感到較舒適的網頁架構(如圖6所示)。

接下來,我們就開始以「專案導向」的方式執行爬蟲吧!
首先,我們要先要到我們要爬取的網址
再點擊「F12」出現如圖7右邊的視窗,進而點擊中間出現的箭頭符號,然後選取我們想要爬取的相關文字(如圖7所示)。
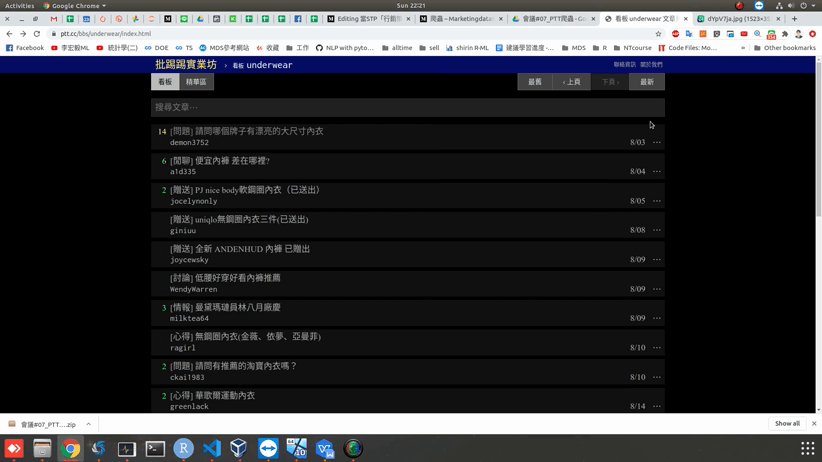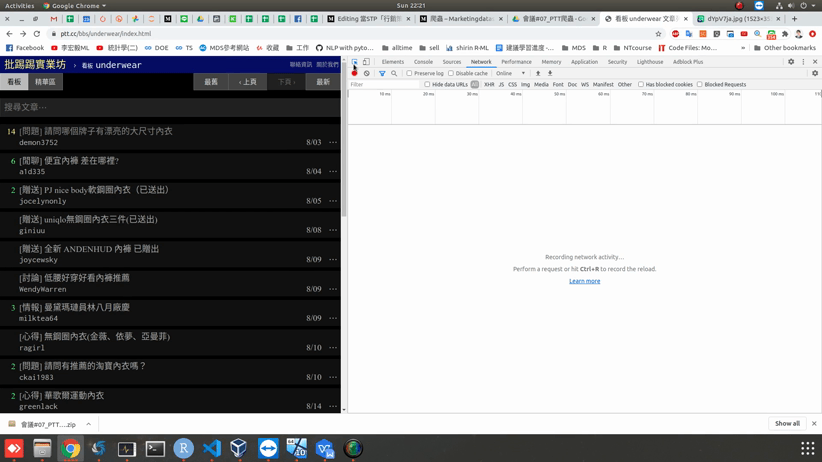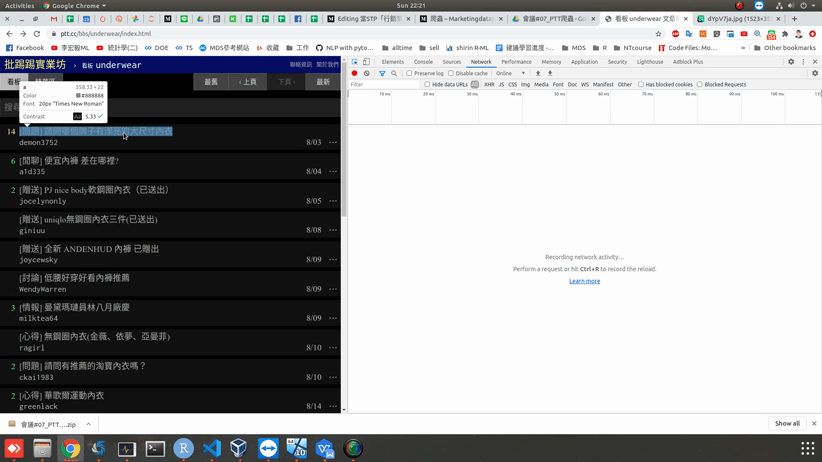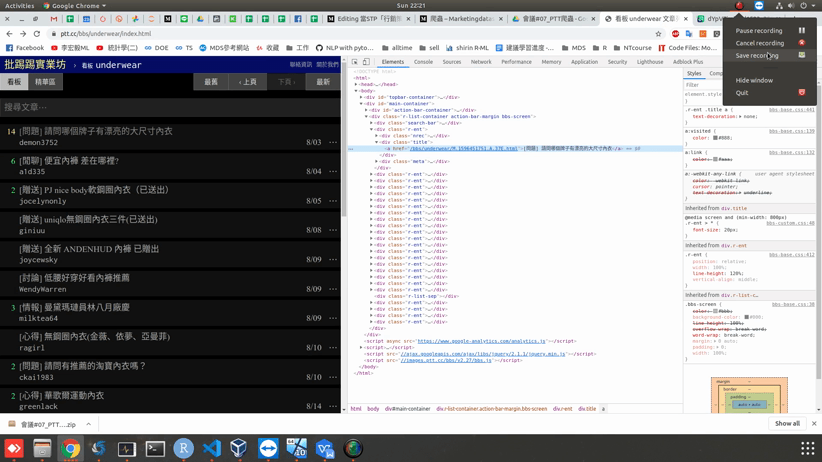
最後就會顯示如圖8的畫面啦!
接下來該如何截取網頁資料呢? 首先,讓我們開始小小入門一下html網頁語法,我們看到圖10的html語法中:
- 標籤:時常會出現div、span等字樣,我們將此稱爲「標籤」,其目的在告訴我們標籤範圍內的所代表的資訊
- 屬性:屬性裏面有包含屬性名稱與其所代表的值,在此目的爲在這麼多的標籤下,可以快速歸類並找到對應的屬性值,如同如10裏面的屬性爲class,其值爲 ”I-love-TMR” ,程式設計師可以將”I-love-TMR”當做敘述「行銷資料科學」敘事內容專門使用的屬性值,讓協作者或自己可以快速理解其代表意涵哦~!
- 網頁顯示的文字內容:又稱作Text,這即是我們常在網頁中一般會看到的內容

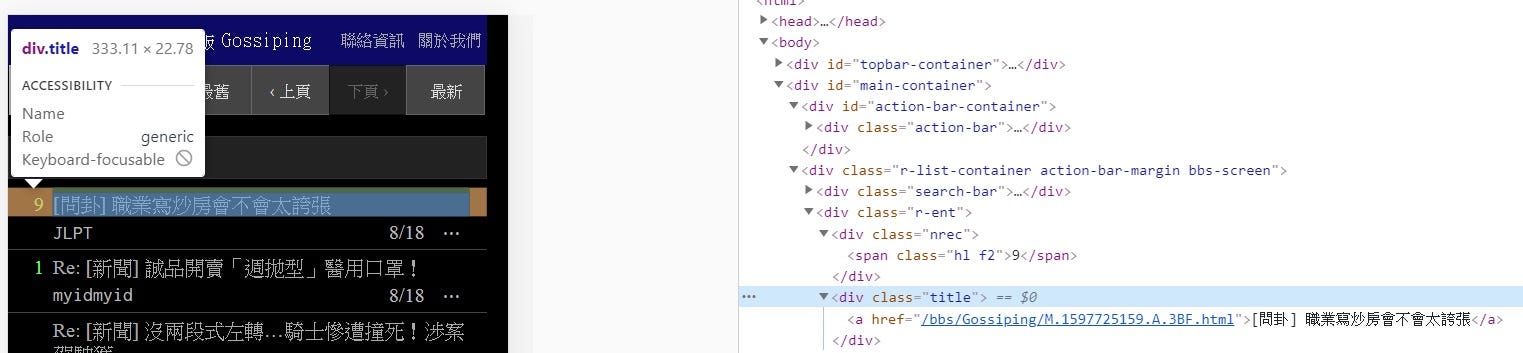
所以讓我們開始對照到我們本次要爬的PTT網頁來重新檢視圖10,我們就可以歸納出本段html語法:
- 「屬性值」:爲div標籤下的Class屬性的title屬性值,程式設計師應該想要標明這是「標題」的意思
- 「網頁顯示的文字內容」:爲圖10左邊顯示的標題名稱,果然在一般的網頁上顯示他的文字內容
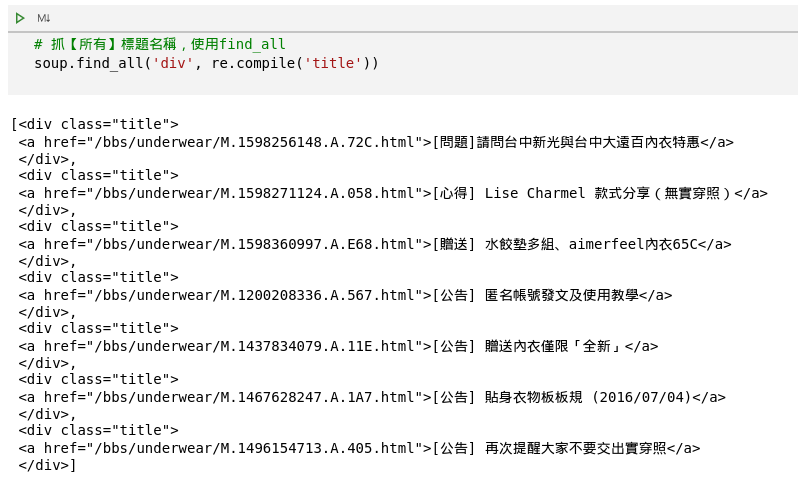
開始具有了html與爬蟲的概念後,我們就可以實戰bs4程式語法來抓取相關資料。從圖11中,我們可以使用bs4的find_all功能來抓取div標籤下的title

讓我們來看看圖12成果,我們果真抓下了div標籤下有關於title的屬性值的相關資料!
若要將我們真正想要的「文字內容」給抓出來,我們會使用「text」的函數功能,將其確實顯示出來,如圖12所示,我們就如實透過爬蟲抓下來我們想要的標題資料啦!

如果要將所有的標題內容全數抓取,就會使用到我們的for迴圈技術,將圖12的ppt_title_text裏面所有的標題給抓出來

若後續要抓取「貼文連結」、「貼文內容」甚至是「貼文留言」等ptt相關文字內容,都是可以使用類似方法抓取的哦!也歡迎讀者點解下述Jupyter notebook鏈接,更深入的瞭解PTT其他內容如何抓取。當讀者慢慢熟悉了本文分享的爬蟲訣竅,我們有信心讀者可以用此方法開始爬取大約90%以上自己想要抓取資料的網頁!
至於剩下的10%則是比較難爬取的網頁,如:蝦皮、FB、IG等。在後續的文章中,我們會選擇蝦皮當做進階爬蟲的教學,其同時也是我們後續要分析的資料來源。
敬請期待!
當STP「行銷策略」遇到資料科學 — 系列4 — 【資料蒐集】PTT貼文抓取模組教學
作者:鍾皓軒(臺灣行銷研究有限公司創辦人)
Python jupyter notebook整理作者:陳俊凱(臺灣行銷研究特邀整理作者)、孔慶媛(臺灣行銷研究特邀整理作者)
