如何評估不同產品適合的廣告方式?! 資料前處理_雙樣本t檢定技法(附Python程式碼)
此篇將講述何謂雙樣本t檢定,並使用該方法判斷不同產品系列適用的廣告為何與背後管理意涵!!

這次將使用一組銷售資料並針對名為”廣告代號all”的欄位篩選三種不同行銷模式所帶來的利潤並將其設為母體,再隨機抽樣分別產生三個獨立樣本集,做兩組情況不同的雙樣本t檢定。
資料建置
首先,一如往常地匯入所需套件及資料集(圖一)

建置好後,選取欲留下的欄位,創立名為data_p的新資料,再透過欄位”單價”扣除欄位”成本”去新增名為”利潤”的欄位。(圖二)(圖三)

設立母體
完成後便可以正式開始篩選本檢定所要求的母體,目標為產品”系列2”下,且廣告代號分別為”廣告_自然流量”、”廣告_edmP”、”廣告_KDP_D”,三者的產品利潤,同時把他們命名為「GL1」、「GL2」、「GL3」,並假設三個彼此為互相獨立的母體。(圖四)(圖五)
此外,可以藉由找出母體平均數及母體數,了解相關特性,以利後續執行雙樣本t檢定的判斷。(圖六)(圖七)
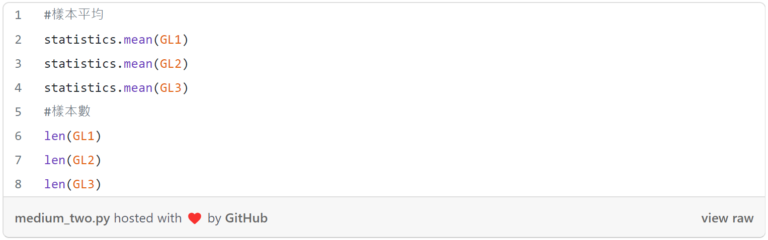
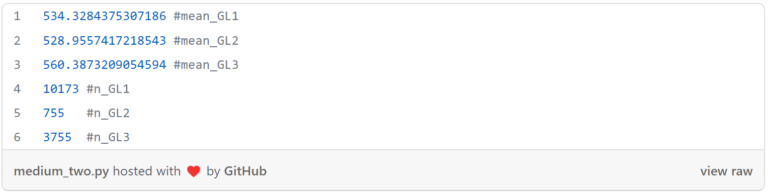
從(圖七)可以看出,「GL3」所帶來的平均利潤是最好的,「GL2」的平均利潤則是三者最低,母體數方面,三者的數量都足夠大,故這邊可應用中央極限定理,判斷其符合常態分佈,這個條件與接下來將要進行的隨機抽樣即符合使用雙樣本t檢定的先決條件。
隨機抽樣
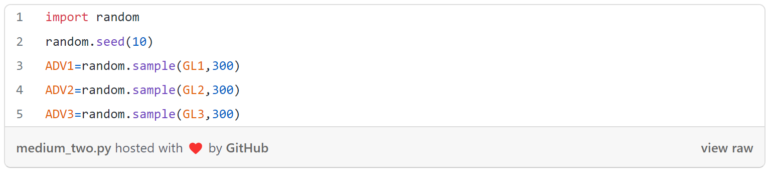
有了母體後,接著就是執行隨機抽樣,在此,我們將原本三個母體「GL1」、「GL2」、「GL3」,運用隨機抽樣的方法抽出300個,並設為「ADV1」、「ADV2」及「ADV3」,但為了避免每次結果有差異,我們透過設定種子(seed)的方式達成控制效果。(圖八)
抽樣完成後,可透過查找平均數的方式,檢查抽樣平均與原本母體平均是否具太大差異。(圖九)(圖十)

534.1095666666666 #ADV1 521.6404666666666 #ADV2 564.1692 #ADV3
我們可從上方結果看出在抽樣樣本數足夠下,平均數上沒有太大的差異(正負3左右),同時抽出的樣本數量亦可套用中央極限定理,故與母體同樣符合常態分配,這邊舉「ADV1」為例,觀察300個樣本的分布狀況如(圖十)及(圖十一)所示。
資料分布
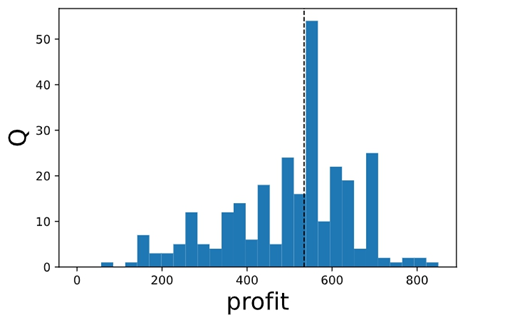
能看出大致上的分布與常態分配的形狀些許類似,所以能更加相信本次運用中央極限定理判斷母體和樣本符合常態分配的結果。
以上為執行雙樣本t檢定前的資料建置與抽樣操作
喜歡的話不妨幫忙打個蚊子吧!
下一篇我們將進一步介紹雙樣本t檢定的實際操作與相關假設,且除了解讀結果之外,結合商業思維,更進一步探究藏在背後的利益考量及決策制定
謝謝觀看,我們下次見~
作者:陳政廷(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究有限公司創辦人)
更多實戰案例及情境好文推薦
購物籃分析 - Python實戰:如何找出商品搭配的總體策略?(附Python程式碼)
購物籃分析 - Python實戰:如何找出商品搭配的總體策略?(附Python程式碼) 本次的文章我們將實際應用購物籃分析,帶您瞭解各項產品
購物籃分析 — Python實戰:商務資料結構整理(附Python程式碼)
購物籃分析 - Python實戰:商務資料結構整理 (附 Python 程式碼) 在不久之前我們曾撰寫過關於購物籃分析的文章,透過分析消
如何使用機器學習提高房仲業潛在成交率?進階資料處理面與基礎建模(附Python程式碼)
如何使用機器學習提高房仲業潛在成交率? 進階資料處理面與基礎建模(附Python程式碼) 先回顧上一篇文章吧~ 如何使用機器學習提高房仲業潛
