資料科學人員需要進行資料呈現時,比起直接提供平均數、中位數、最大最小值等敘述性指標,透過盒鬚圖來進行呈現也是良好的選擇,不但能將資料的分佈一目了然地呈現出來,快速掌握狀況外;也能讓我們在進行統計檢定及迴歸預測前,能使用成果產生初步的決策參考。
本次使用的資料與前CH3–2的折線圖章節同為「電商交易資料.csv」,透過該資料繪製盒鬚圖,了解產品系列在不同月份的廣告效益。

一、引入套件包與原始資料
首先,將本次會使用到的套件包以及分析資料引入,如程式碼1所示:
程式碼1:
# 引入套件包import pandas as pdimport osfrom collections import Counterimport heapqimport plotly.offline as pyimport plotly.graph_objects as go# 引入電商資料data = pd.read_csv(“電商交易資料.csv”, encoding=’utf-8-sig’)data.head()產出:
二、資料處理
在基礎資料處理的部分,我們主要會針對兩項重點進行處理,分別為:
(一) 欄位與產品系列篩選
由於該電商資料共有近百種的產品系列,每種系列常用的廣告宣傳方式以及廣告可以帶來的效益都有所不同。因此本章節會先以「系列4」的資料用來製圖和分析,透過下方程式可透過「系列」欄位,將「系列4」以外的資料給篩選掉,並將本次製圖不需使用到的資料欄位移除,如顏色、性別、年齡等。
程式碼2:
data = data[[‘單價’, ‘成本’, ‘系列’, ‘訂單時間’, ‘廣告代號all’]]data = data[data[‘系列’] == ‘系列4’]data.head()產出:
篩選完之後可透過變數檢視器看到,資料集「data」的資料成功從35萬筆左右篩選到剩下11059筆了。
(二) 篩選廣告系列名稱
資料集中的「廣告代號all」欄位內的編號依序為「廣告系列」(如YND、KDPOD2等)與「廣告細項」(如pid)。
展開資料集「data」可以發現,該資料集在廣告方面的記載十分詳盡,舉例來說:光是廣告系列「KDPOD」就有「qrtist」、「chiciMT」、「select」、「chicihey」…等細項分枝。若要考慮到如此大量的廣告種類,除了資料集被大量廣告平分下來會有個別資料過少問題,龐大的類別也會使資料處理及呈現變得雜亂,因此在進行資料呈現時只考慮廣告「系列」,而忽略廣告「細項」。
透過程式碼3,依照廣告資料格式使用「split」功能將廣告名稱依照「_」切分開來,如下所示。
程式碼3:
ad_split = data['廣告代號all'].str.split('_', expand=True)ad_split產出:

我們可以從上方圖3. 得知,若只想取得廣告系列名稱的話,則需取出編號1的欄位。
透過程式碼4,我們將編號1的欄位取出後存成串列「ad_series」,並透過程式碼5將「ad_series」放入資料集「data」中,形成新欄位「廣告代號」。
程式碼4:
ad_series = data['廣告代號all'].str.split('_', expand=True)[1].tolist()print(ad_series[:10])產出:
['YND', 'YND', 'YND', 'YND', 'YND', 'YND', 'YND', '自然流量', '自然流量', '自然流量']程式碼5:
data['廣告代號'] = ad_seriesdata.head()產出:
三、進階資料處理-挑選主力廣告
即使已經忽略廣告的細部分枝,展開資料集仍可發現一些問題:
1. 廣告種類依舊五花八門,可能導致資料展示及分析困難
2. 資料集中少數的廣告系列佔據了大部分的資料筆數
透過程式碼6,可幫助掌握系列4總共使用了幾種系列的廣告:
程式碼6:
len(data['廣告代號all'].unique())產出:
36從產出可看到,系列4在行銷廣宣上一共使用了36系列的廣告。接著使用「Counter」功能,可協助我們計算不同廣告總共出現的頻率分別為多少,如程式碼7所示,製作出頻率清單「count_list」:
程式碼7:
count_list = Counter(data['廣告代號'])count_list產出:

緊接著,透過程式碼8,將「count_list」整理成DataFrame格式,以利閱讀,如下所示:
程式碼8:
count_frame = pd.DataFrame.from_dict(count_list,orient='index').reset_index() # 轉換為DataFrame形式count_frame.columns = ['廣告名稱', '樣本數'] # 重新命名欄位名稱count_frame.head()產出:
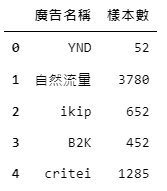
透過「count_frame」可以看到,除了少數幾款廣告系列有800筆以上的出現頻率以外,大部分的廣告系列皆只有個位數或是十位數的使用頻率,不適合用來做資料分析,除此之外,「自然流量」而產生的廣告系列並非我們能實際加強之廣告,需進行排除。
透過程式碼9,除了將自然流量從「count_frame」內進行排除外,也根據每個廣告系列的樣本數進行排序,方便我們挑選主力廣告,如下所示。
程式碼9:
count_frame = count_frame[count_frame['廣告名稱']!='自然流量']count_frame = count_frame.sort_values(by='樣本數', ascending=False)count_frame.head()產出:
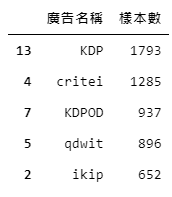
根據圖7. 我們便可有效地掌握哪些廣告系列成功促成的交易筆數最多,並針對這些廣告進一步進行效益分析,在本章節我們將先以促成交易筆數最多的「KDP」與「critei」做為主力廣告,如下程式碼10,我們創建名為「chosen_ad」的串列,用以存放主力廣告名稱。
程式碼10:
chosen_ad = count_frame['廣告名稱'].tolist()[:2]chosen_ad產出:
['KDP', 'critei']找到主力廣告後,接下來要將資料集「data」進行篩選,只留下主力廣告所促成的交易資料即可。
對於搜尋符合廣告的情況下,可以使用pandas套件包內的附屬功能isin()取得,省下使用迴圈逐一尋找的苦工,如下程式碼11便透過該功能,判斷每筆交易是否透過主力廣告促成。
程式碼11:
# 判斷是否符合條件data['廣告代號'].isin(chosen_ad)產出:
掌握isin()的操作方法及產出後,便可透過此技巧進行資料篩選,如下所示。
程式碼12:
# 篩選data = data[data['廣告代號'].isin(chosen_ad)]data產出:
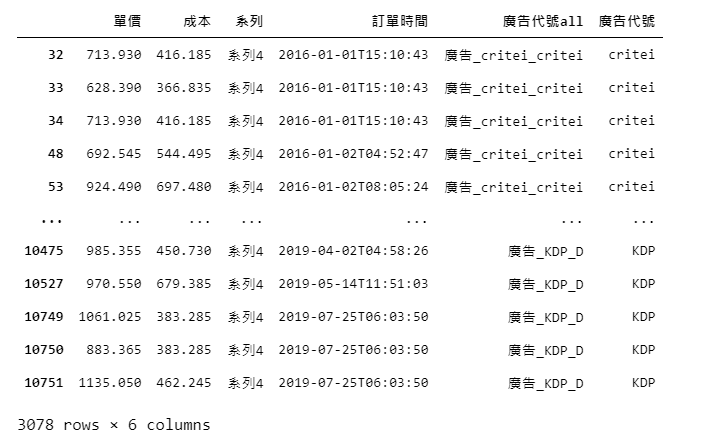
四、進階資料處理-不同廣告每期帶來的淨利
到目前為止,資料處理差不多完成7成了,要將資料用來繪圖之前,還得計算出資料集的「淨利」,並加以統整出不同廣告在每一期(月份)所為系列4帶來利潤為多少。
首先透過程式碼13,將資料集「訂單時間」的月份取出,建立新欄位,如下。
程式碼13:
data['月份'] = pd.DatetimeIndex(data['訂單時間']).monthdata.head()產出:

「月份」將會用來在製圖時,做為X座標。
接著我們透過to_period()這項功能,取出資料的年月並新增欄位,我們後續在進行資料群組加總時便會根據「年月」這欄進行操作。
程式碼14:
data['年月'] = pd.to_datetime(data['訂單時間']).dt.to_period('M')data.head()產出:
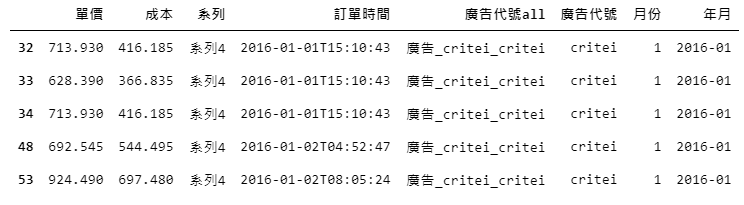
當我們在to_period的括號內輸入「M」時,時間資料會一路取到最小為月的單位,括號內的英文字母也可以從以下幾種中去做替換:
1. Y:時間資料會一路取到最小為年的單位
2. D:時間資料會一路取到最小為日的單位
3. H:時間資料會一路取到最小為小時的單位
4. T:時間資料會一路取到最小為分鐘的單位
5. S:時間資料會一路取到最小為秒的單位
接著,透過程式碼15,利用產品的「單價」減掉產品的「成本」,取得「淨利」,並回存至資料集「data」中。
程式碼15:
data['淨利'] = data['單價'] - data['成本']data.head()產出:
最後,透過程式碼16,將資料集「data」的多餘欄位去除,便完成資料群組加總前的資料處理了。
程式碼16:
data = data[['廣告代號', '月份', '年月', '淨利']]data.head()產出:
現在我們的資料集中剩餘四個欄位,分別為用來區分主力廣告種類的「廣告代號」、做為盒鬚圖資料分佈參考的「月份」、用以群組加總的「年月」,以及「淨利」。
接下來透過程式碼17,使用「pandas」中的群組功能「groupby」,將資料集「data」內的資料根據「廣告」、「月份」以及「年月」進行群組,並計算出淨利總和,如下:
程式碼17:
data = data.groupby(['廣告代號', '月份', '年月'])['淨利'].sum()data = data.to_frame().reset_index()data.head()產出:
最後,在進行繪圖之前,將已經不需再使用的「年月」欄位移除,並新增「count」欄位,每筆資料的「count」欄位皆為1。
由於不同的產品系列有不同的銷售期間,因此有可能會有些期數沒有任何該產品系列的交易數據。舉例來說:產品系列X於2017年上市,並於2018年底停售,若我們想了解該產品在1月的平均利潤,應該要除以兩年而非四年(本原始資料時間範圍為2016~2019年)。透過count的加總,我們可以很清楚不同年度的同一個月份共有幾筆資料,並做為計算平均時的分母。如下:
程式碼18:
data = data.drop(['年月'], axis=1)data['count'] = 1data.head()產出:
五、繪圖
經過了一大番努力過後,終於可以將處理完後的資料繪圖產出拉!透過程式碼19可先設置空白畫布,並透過for迴圈,根據廣告種類逐一繪製每月的利潤盒鬚圖:
程式碼19:
fig = go.Figure() # 設定空白畫布colors_box = ['#3366CC', '#DC3912'] # 設定盒子顏色color_num = 0# 繪製盒鬚圖for i in data['廣告代號'].unique():fig.add_trace(go.Box(y = data[data['廣告代號'] == i]['淨利'],x = data[data['廣告代號'] == i]['月份'],name = i,marker_color= colors_box[color_num]))color_num = color_num + 1盒鬚圖內的設定如下:
l y:盒鬚圖的y軸,在這邊指的是「平均淨利」
l x:盒鬚圖的x軸,在這邊指的是「月份」
l name:類別名稱,在這邊是依據「廣告類別」區分
l marker_color:盒子的顏色,如串列「colors_box」所示
設定完了盒鬚圖之後,接著會透過程式碼20繪製平均線,如下所示:
程式碼20:
adlist = list(data['廣告代號'].unique()) # 廣告名稱清單color_line = ["royalblue" , "firebrick"] # 設定線條顏色colour = 0 # 取用的顏色順序# 畫平均線for i in adlist:ad = i # 選用廣告meanlist = [] # 平均axislist = [] # 月分for ii in range(1,13):axislist.append(ii)total = data[data['廣告代號'] == ad][data['月份'] == ii]['淨利'].sum() # 總利潤counts = data[data['廣告代號'] == ad][data['月份'] == ii]['count'].sum() # 資料筆數aver = total/counts # 平均利潤 = 總利潤/資料筆數meanlist.append(aver)# 如果1~12月都已經計算完畢,就繪圖if ii == 12:# 繪圖fig.add_trace(go.Scatter(x= axislist,y= meanlist,mode="lines+markers",textfont=dict(family="sans serif",size=16,color="royalblue"),line=dict(color=color_line[colour], width=2),))# 即將更換廣告,挑選另一種顏色colour = colour + 1在上方的迴圈中,我們先透過for迴圈依序挑選不同主力廣告,並再透過第二層for迴圈逐月計算平均淨利,儲存至串列「mean_list」中,直到該廣告計算到12月為止,便針對該廣告繪製平均線。
資料都輸入完之後,便可設定佈景主題並且產出了,如下:
程式碼21:
# 設定佈景主題(字體、大小、背景等)fig.update_layout(title={'text': "<b>BoxPlot-廣告效益分析</b>",'y':0.95,'x':0.5,'xanchor': 'center',},yaxis_title='Profit',xaxis={'title': 'Month','tickmode': 'linear'},width=1800,height=960,boxmode='group',font=dict(family="Courier New, monospace",size=20,color="lightslategrey"))fig.show()程式碼22:
# 另存html檔py.plot(fig, filename='CH3-8產出成果_廣告效益分析', auto_open=True)# 另存圖檔fig.write_image("CH3-8產出成果_廣告效益分析.png")產出:
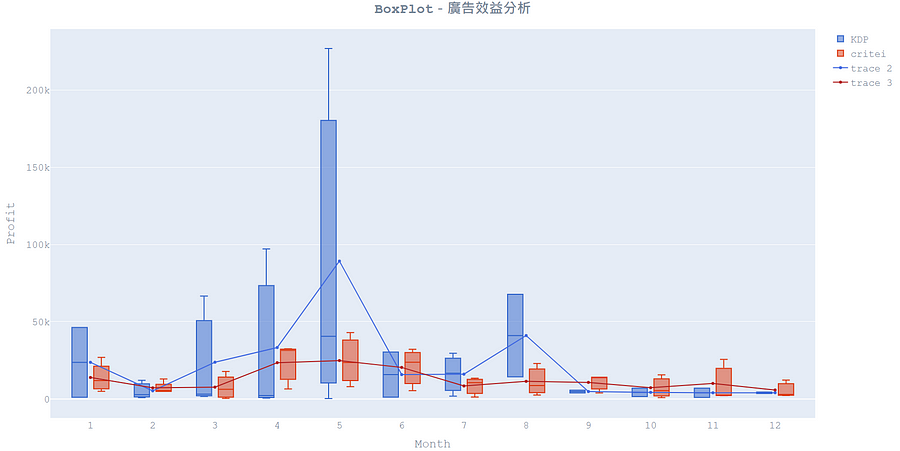
我們可針對產出的圖片做初步的熱門廣告效益分析,舉例來說「critei」在九月時,相較於「KDP」可讓「系列4」有較好的淨利效果,因此在九月時對「系列4」加強「critei」廣告應該可以產生更好的獲利效果。而有些月分則較難去目測比較廣告的好壞,如以5月的資料來說,雖然「KDP」的淨利涵蓋範圍遠高於「critei」的淨利涵蓋範圍,應該會有比較好的效果,但使用「critei」時的淨利範圍比較集中,可以得到較好的控制效果,因此難以推論誰好誰壞。
有沒有發現上面的結論不斷出現「應該」呢?那是因為在進行決策參考時,若沒有一個公允的指標或檢定來進行判斷的話,資料科學人員所能歸納出的結果往往會偏於主觀想法。
因此在下一單元中,將會開始為您介紹不同的統計檢定,並將這些檢定應用至商務個案中,創造出準確且值得信賴的決策指標。
作者:徐子皓(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究有限公司創辦人)
