先回顧上一篇文章吧~
如何使用機器學習提高房仲業潛在成交率?資料處理面基本心法(附Python程式碼)
情境
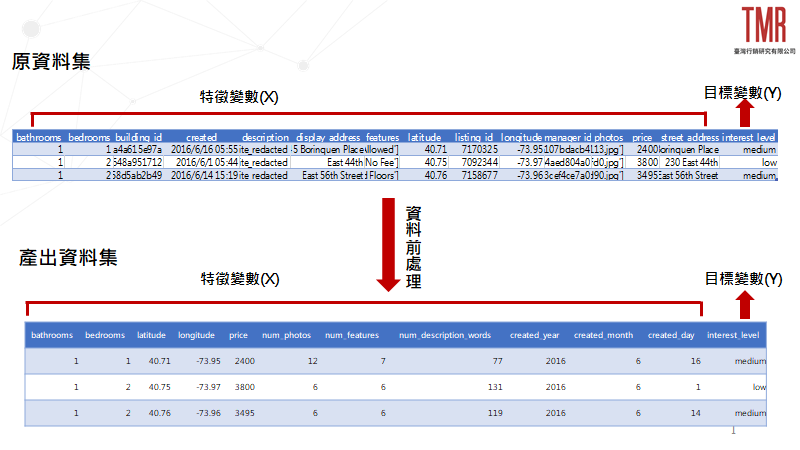
針對前一篇的資料前處理,我們共可以得到11個特徵變數(bathroom~price)和1個目標變數(interest_level),如圖1所示。
進階資料處理
接下來,我們將運用進一步的資料處理技巧並建構不同的的機器學習模型,流程如圖2所示。

其中,我們把資料前處理分為特徵處理、資料切分、標準化三步驟,同時也會把操作方法及成果呈現於下列內容。
在進入到下一階段前,這邊附上了python程式碼供大家參考,連結如下。
程式碼來源:臺灣行銷研究Github
特徵處理
主要針對「features」欄位裡的所有資料,這邊可以想像為hashtag的概念,內容多為描述房屋特徵的字詞,這種形式可以讓消費者快速了解到房東對該房屋所欲呈現的重點,但此種資料通常會產生兩個小問題
1. 每筆資料裡可能會具有不同的hashtag
2. 不同筆資料中可能會含有相同的hashtag
因此,為了挑選出相對重要的值,我們分別計算每個字詞出現的頻率,並把”頻率大於100的字詞”當作篩選條件產出數組字詞,最後將符合篩選條件的字詞轉換為二元變數(dummy variable)的形式(共69個)。舉例來說,若有一欄位為Elevator,則在「features」的每筆資料中只要出現Elevator,那麼在Elevator的欄位處就填上1,反之填上0,前後比較如圖3所示。

操作至此,便又產生了新的問題,由於擁有過多的欄位,容易讓整體變異過大導致模型過度擬合(overfitting),故借助了特徵篩選的套件(SelectFromModel),來幫助我們解決這個問題,介紹如圖4所示(其中estimator需填入的內容,將留至底下基礎建模部分再進行介紹)。

有興趣的讀者可以參考此連結,將有更詳細的原文介紹。
資料切分
為後續建立機器學習模型的交叉驗證(Cross Validation),以便判別該模型有無overfitting和比較不同模型間了解何種模型underfitting,在此將整個資料切分成8:2的形式。
標準化
確保建立模型時較不受原始資料單位上的影響,將資料中的數值欄位進行標準化(每筆資料先扣除該欄位平均再除以該欄位之標準差),使最後各欄位約99%的資料均落在-3到3之間,進行到此步驟時需非常小心,不可將前面特徵處理之二元變數欄位進行標準化,否則,將會導致模型產生偏誤。
此外,標準化模型中只有 fit 訓練資料集(training set)而非連同測試資料集(testing set)一同進行的原因為確保兩者平均數和標準差相同,若 fit 測試資料集將會產生不同的平均數以及較大的標準差導致模型結果偏誤。
進階資料處理後的成果檢視
以訓練資料集為例,如圖5所示。(底下為後續建立Random Forest的資料集,從原本75個變數中篩選出6個連續變數和12個類別變數)

基礎建模
完成進階資料處理後,便可以開始進行建構各個機器學習模型來做預測,而此篇即將操作並介紹Random Forest、XGBoost、LightGBM 三個機器學習模型。
首先,這邊先針對上述三個機器學習模型,做一個簡單的模型選用比較供大家參考。
1. Random Forest
目前十分廣為人知且入門容易的模型之一,透過隨機重複取樣的方式產生樣本集(bootstrap),同時隨機從總特徵數中選擇一定數量的特徵進行分裂,再重複多次產生許多顆決策樹組合在一起,由他們這些多數獨立投票決定預測方向,得出一個平均的結果,若想更深入了解,可參考此連結。
優點:
(1)能處理多特徵的資料
(2)由於進行決策的方法是彼此獨立投票,較好做成並行方法(操作多個處理器去解決同一個問題)
(3)可以透過建立多顆樹運用大數法則的方式避免overfitting
(4)內建功能可以篩選出特徵的重要程度
缺點:
(1)較不推薦使用於迴歸問題,本身演算法就不是給出一個連續的輸出,較容易overfitting
(2)處理噪音較大的問題時容易overfitting
2. XGBoost(Extreme Gradient Boosting )
相信大家對於這個都不陌生,活用於各大競賽中,在缺失值得處理及整體準確度上都非常優異,這邊就直接介紹使用的優缺點,簡單來說,每次添加一棵樹就是增加學習一個新函數,透過擬合上次的錯誤經驗,去提高整體的準確度,若想進一步了解,可參考此連結。
優點:
(1)加入regularization避免overfitting
(2)透過稀疏感知演算法處理缺失值,遇到缺失值時自動歸類到預設方向
(3)效率較佳
缺點:
(1)預排序容易花費過多時間:雖然可以透過前述降低尋找最佳分裂點的計算量,但過程中仍需要遍歷所有資料集
3. LightGBM(Light Gradient Boosting Machine)
最廣為人知的地方就是他的速度及不占用過多記憶體等優勢,在兼具XGBoost的準確度下加快整體model的訓練速度。與其在新增其他樹葉時確定所有分支,只確定其中某部分在時間上較為節省,每次分裂時均會以能夠提供最大差異(分裂效益最大)的點出發,若大家想繼續往下深入,可參考此連結。
優點:
(1)速度更快
(2)內存更小
缺點:
(1)有可能會導致overfitting:分裂方式與前述的XGBoost跟Random Forest不同(level-wise),採用leaf-wise的方式但有可能導致整個樹長得過深,故需要設定max_depth去控制。
以上不同模型的優缺點整理比較如下,如圖6所示。

介紹完模型選用後,便可分別將各模型代入特徵篩選套件(SelectFromModel)中的estimator進行篩選,如圖7,並完成基礎建模,訓練成果如圖8所示。


以圖8訓練成果而言,我們使用分類常用的Log Loss來評判成效,Log Loss的計算公式為物理學常提及的熵(Entropy)或稱「亂度」。若亂度越低,則表示分類越趨於精準,所以我們可以得知若圖8的數值越低,則代表分類越精準。至於為何使用Log Loss,將會保留至下一篇詳細介紹。
從結果發現,Random Forest模型在「經過特徵篩選測試資料集(僅調整重要特徵值)」的Log Loss較「未經過特徵篩選測試資料集(原資料)」還要小,意味亂度較小,代表「特徵篩選」在本模型是有一定的效果。
不過在XGBoost及LightGBM模型則是使用「未經過特徵篩選測試資料集(原資料)」的亂度來得更小,而且效果比Random Forest模型還要來得更佳,所以依資料科學模型評估指標來說,建議我們可以選擇LightGBM模型來進行後續目標變數(詢問度)的預測。
接下來便可以查看目標變數(詢問度)的分類情形,這邊將會以LightGBM為例,預測成果如圖9所示。
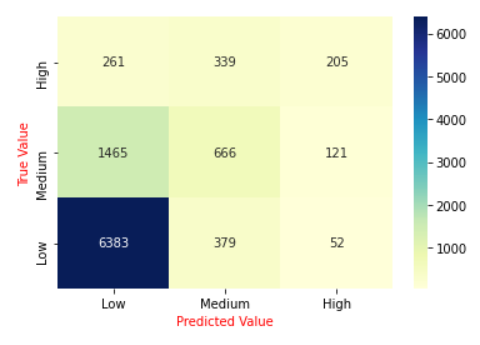
從圖9可以看出普遍預測的結果均為「Low」,雖然實際值「Low」也是佔居多數,但這邊我們可以合理懷疑此資料是否發生了「資料不平衡」的狀況,如圖10所示。

從圖10發現整體資料於起始狀態便具有分布不平均的情形產生,因此我們將在下一篇系列3_提升機器學習準確度的方法中,使用處理資料不平衡的方法並進一步介紹及如何使用Log Loss比較方法間的成效,為大家帶來不同的想法並使用機器學習提高房仲業的潛在成交率!
以上就是系列2_進階資料處理與基礎建模的全部囉
看完後,如果覺得喜歡,不妨幫忙拍個手 !
我們下次見~
參考資料:
- 特徵選用參考資料:https://bit.ly/39ce0jR
- Random Forest參考資料:https://www.stat.berkeley.edu/~breiman/randomforest2001.pdf
- XGBoost參考資料:https://arxiv.org/pdf/1603.02754.pdf
- LightGBM參考資料:https://papers.nips.cc/paper/2017/file/6449f44a102fde848669bdd9eb6b76fa-Paper.pdf
- 如何使用機器學習提高房仲業潛在成交率_系列1_資料處理基本心法
作者:陳政廷、王裕萍、謝豐檍(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究有限公司創辦人)
