情境
目前美國知名房屋出租網「RentHop」於租客端已做出差異化,租客在網站上不僅可以選擇價格與房間個數…等相關條件外,還可以透過房屋質量(是否於網站上附圖、房東回覆即時率)去做排序,讓租客端擁有另外一種層面去選擇,如圖1所示。
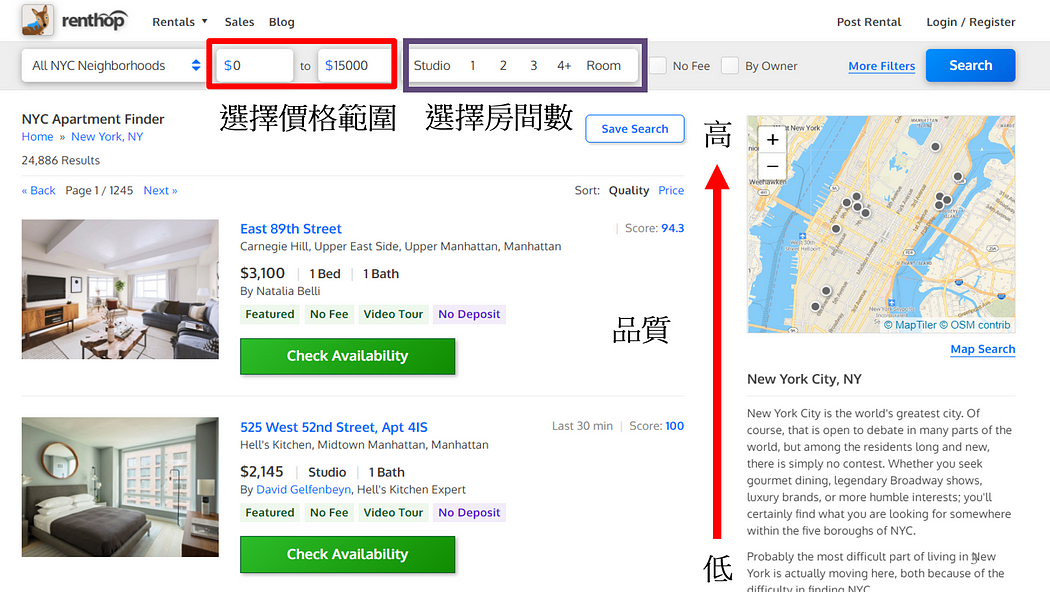
未來RentHop希望能預測每筆新建立的房屋清單究竟可獲得多少查詢量,並提升潛在成交率進而帶來利潤。
任務
將運用交付資料集中的14個特徵變數,預測房屋的查詢量
預期成效
使屋主和仲介能更好地了解租客的需求和偏好
資料前處理
首先,在我們建立任何模型之前都應該先進行資料前處理,以奠定後續良好的分析基礎

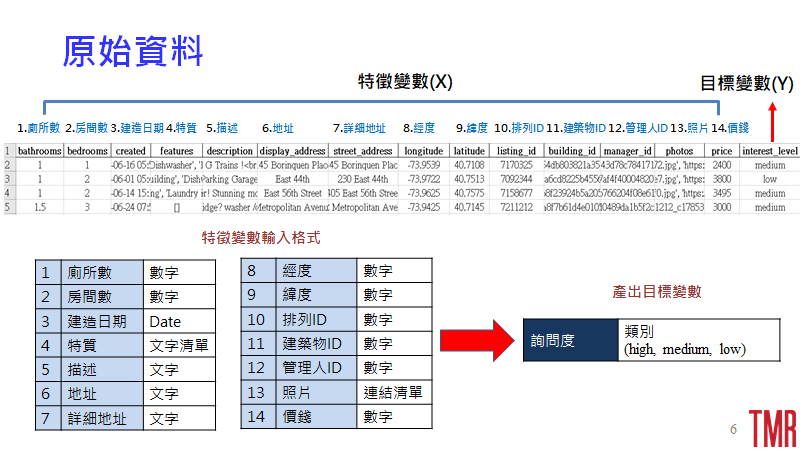
在原始資料集的部分,主要是由14個與房屋相關的特徵變數,舉例來說:廁所數量、房屋建造日期、地址…等等,與1個目標變數:詢問度(interest_level),也就是消費者對於該房屋感興趣的程度,分為高(high)、中(medium)、低(low)所構成,通常興趣程度越高,代表詢問程度越高,如圖3所示。
在了解資料大致型態後,我們便開始資料前處理,同時,這邊也附上Python的程式碼供大家參考,連結將放置於底下。
程式碼來源:臺灣行銷研究Github
在此我們以圖示的方式呈現需要轉換的變數以及手法,如圖4所示。
1. 將較無法提供分析意義的欄位刪除
2. 將建造日期(created)以「年」、「月」、「日」分成三個欄位
3.針對房屋特質(features)、描述(description)、照片(photos)等欄位計算字詞數量

資料前處理後的成果檢視
進行資料分析前,越是了解資料的架構就越能奠基資料分析的品質,因此,在完成資料處理後,不妨再次對資料進行查看,了解新增的變數欄位以及資料格式上是否有有所不同,結果如圖5所示。
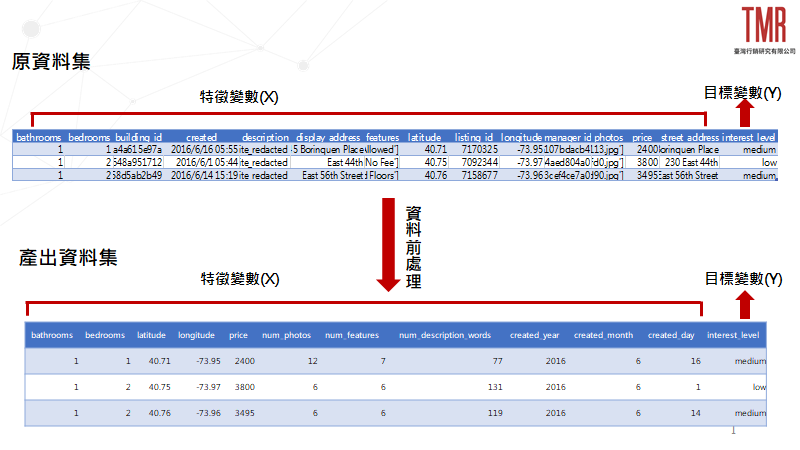
然而,接下來我們就可以進行後續分析了嗎? 這麼快就已經完成所有資料前處理的工作了嗎?
其實我們還有一些因素沒有考慮進去,舉例來說,可以從這次產出裡看到「num_description_words」及「num_features」兩欄隱藏了兩個問題。若圖4的結果放將要建構的模型中:
- 上述兩欄位僅呈現字詞個數的多寡,未考量到文意本身對目標變數(詢問度)的影響,所以很有可能無法對模型在詢問度的預判上有所貢獻。
- 若模型判斷出上述兩欄位所呈現的字詞個數多寡對我們要分析的目標變數(詢問度)呈現正向影響,如此將導致房東端只需在兩欄位的敘述部分打更多字,便能得到詢問度「高」的假象。
因此筆者在系列2與3的文章中,將運用進一步的資料處理方式以及分別介紹並且建構不同的機器學習模型,為大家帶來如何使用機器學習提高房仲業潛在成交率!
以上就是系列1_資料處理基本心法的全部囉
如果看完覺得喜歡,不妨幫忙拍個手 !
我們下次見~
參考資料
Renthop: https://www.renthop.com/
Kaggle-Random Forest Starter with numerical features: https://www.kaggle.com/aikinogard/random-forest-starter-with-numerical-features/notebook
作者:陳政廷、王裕萍、謝豐檍(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究有限公司創辦人)
