過去的二篇文章,我們探討了將機器學習的方法應用於房仲業的出租網,引起了許多讀者的回應。本篇文章,作者們很努力的繼續研究,深入探討如何提高預測的準確度。
在開始之前,我們一起來回顧一下”有一點久”之前寫的文章。這樣讀者會比較快進入本篇預測準確度的分析內容。
回顧文章_基本資料處理 :如何使用機器學習提高房仲業潛在成交率?資料處理面基本心法(附Python程式碼)
回顧文章_進階資料處理 :如何使用機器學習提高房仲業潛在成交率_系列 2_進階資料處理與基礎建模(附Python程式碼)
情境
在系列2中我們使用了進階資料處理方法並透過不同的機器學習方法建立模型,但在預測成果中發現普遍預測分類均為「Low」的狀況,故合理懷疑資料發生「資料不平衡」的問題,經過查證後,亦證實了確實有這種狀況產生。因此我們將在本篇帶給大家如何處理資料不平衡的方法並重新建立模型,比較處理資料不平衡前後是否能有效提升本次預測的準確度,整體流程如圖1所示。
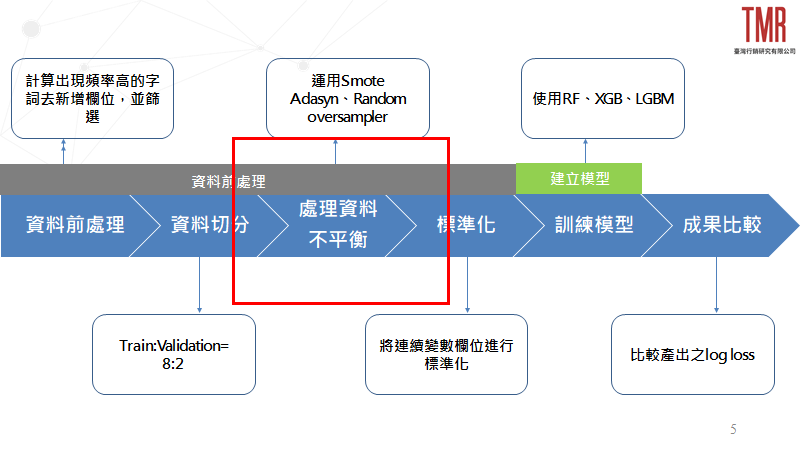
本篇亦將下列操作整理成Python程式碼,放入底下連結提供給大家參考
程式碼:臺灣行銷研究Github
解決資料不平衡方法
這邊將分別介紹RandomOverSampler、Smote、Adasyn三種處理資料不平衡的方法。
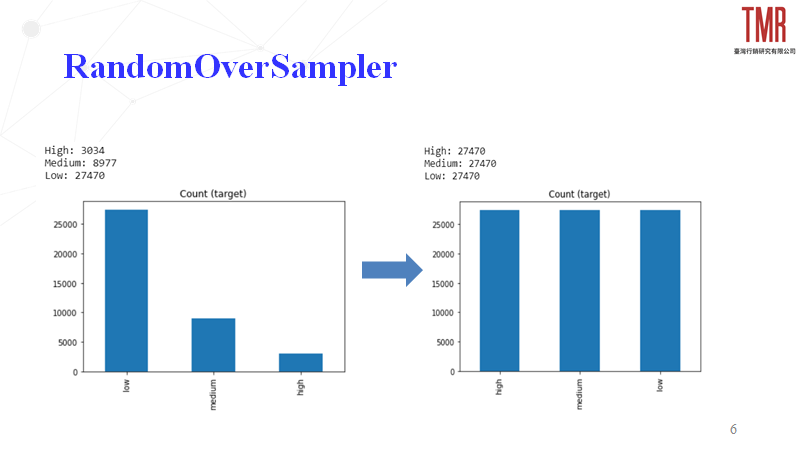
1.RandomOverSampler
依照指定的比例去複製生成其他欄位的資料,並洗亂整體順序,以保持模型的訓練效果,我們以「Low」的比例去複製生成同樣數量的「Medium」、「High」達成資料平衡,如圖2所示。
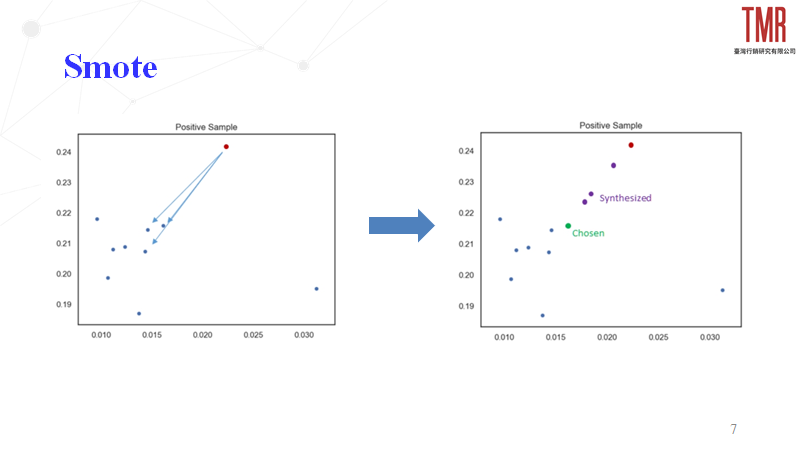
2.Smote
- 設定採樣倍率N,選定樣本需要生成N個合成樣本
- 設定一個近鄰值K,針對該樣本找出K個近鄰樣本並從中隨機挑選一個
- 公式:X_new=X_chosen+(X_nearest-X_chosen )∗δ; δ∈[0,1]
以圖3為例,假設紅點為選定樣本,設定為合成樣本(N=3)和近鄰值(K=3)後,便根據位置挑出近鄰樣本(左下圖三個藍點),隨機挑選的點為綠色並以此去擬合其他三個新樣本,其結果與RandomOverSampler相同。
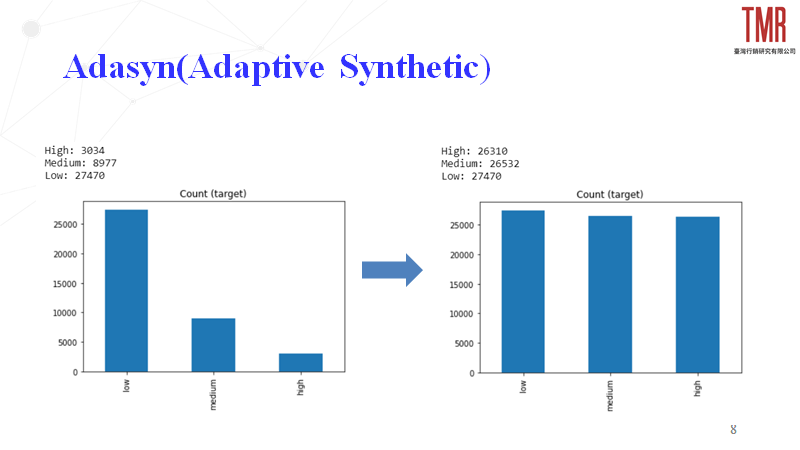
3.Adasyn
與Smote原理類似,但額外考量了原始資料分布情況,替不同少數類樣本依照其比例去增添新樣本,成果如圖4所示。
無論操作何種方式解決資料不平衡,請務必先進行資料分割,將訓練以及測試資料集分開,避免產生污染測試資料集的問題,這邊只需在訓練資料集上達成資料平衡,並將測試資料集放入訓練好的模型即可。
模型建立與比較
處理完資料不平衡後,接續可按照系列2所述方法,對各資料集分別建立不同的機器學習模型並比較各自成效,而在這之前,我們將先行介紹「Log Loss」,在分類的機器學習模型當中常見的損失函數。
Log Loss
目的:用來量化在分類問題中預測不準確所付出的代價。
公式(以二元為例):如圖5所示,其中y為輸入實例,p為預測正確與否的概率
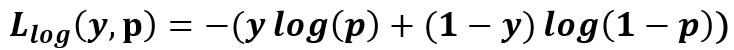
看起來有些複雜,為什麼不使用Accuracy就好了呢?
使用「準確度」(Accuracy)作為衡量指標便有可能會遇到「準確度悖論」的問題。舉例來說:警察在偵辦電話詐欺案時會去查看電話詐欺占總詐欺數的比例,假設電話詐欺佔總詐欺數的5%,非電話詐欺則佔95%,此時警察若下「所有詐欺案都不是電話詐欺」的判斷,便可得到準確度高達95%的模型。雖然這個模型準確度十分高,但實際上完全沒有真正的電話詐欺案,此問題即為「準確度悖論(Accuracy Paradox)」,故單純考慮準確度似乎並非那麼合理。
Log Loss透過懲罰錯誤的分類(考慮分類錯誤值與實際值關係的狀況與概率),達成了對於準確度的量化,便可得此結論:「最小化Log Loss即等價於最大化classifier的準確度」,因此在進行分類模型上使用Log Loss相較合適。
緊接著我們便透過系列2所提的機器學習模型(RF、XGB、LGBM),針對上述處理資料不平衡方式之產出進行建模與比較,成果如圖6、圖7和圖8所示。
此外,本篇也將附上與前一篇在測試資料集上的比較,加以探討對於該資料進行資料不平衡處理是有其必要性,如圖9、圖10所示。
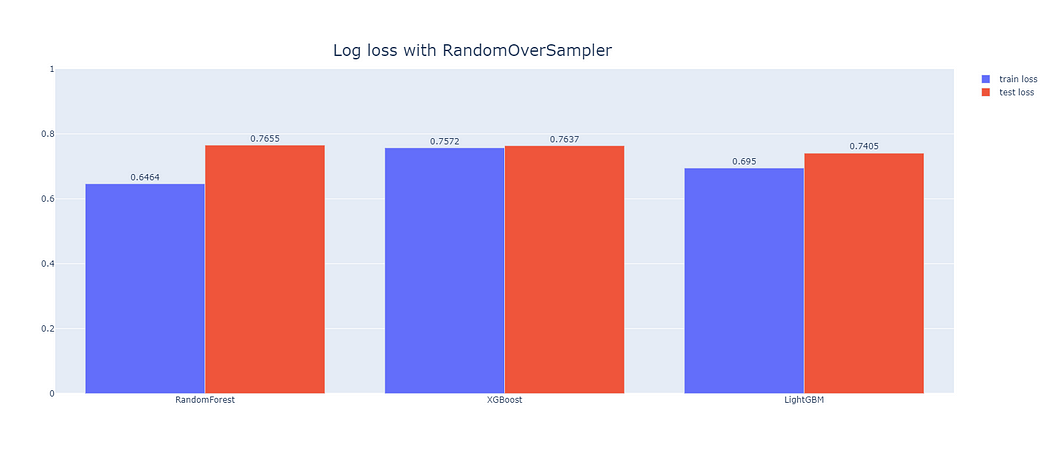
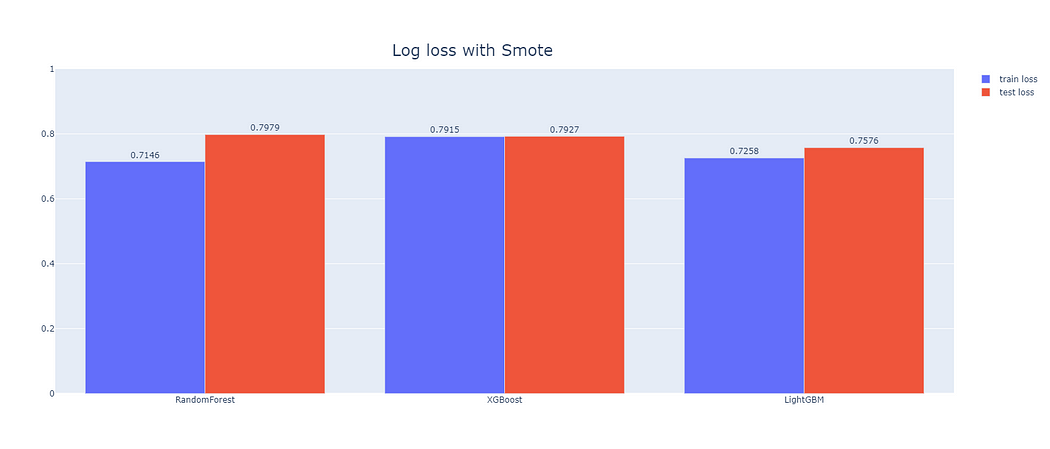
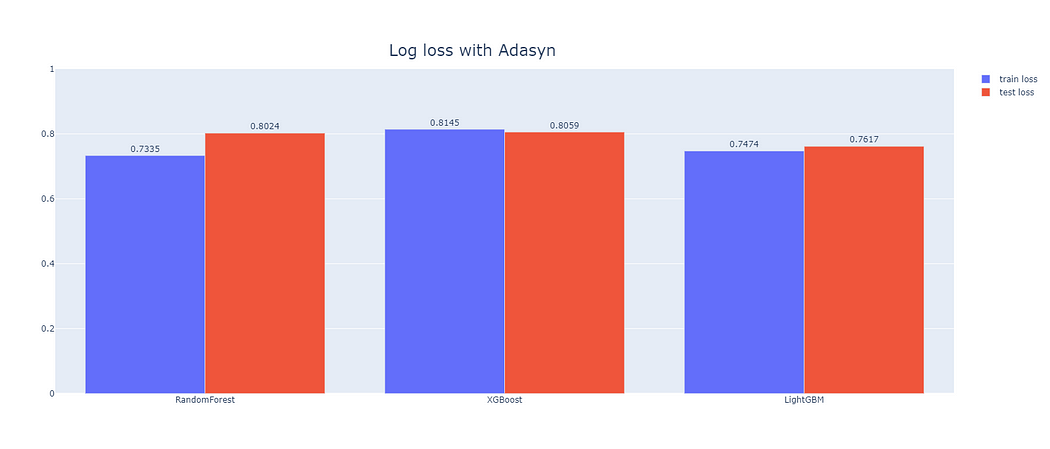

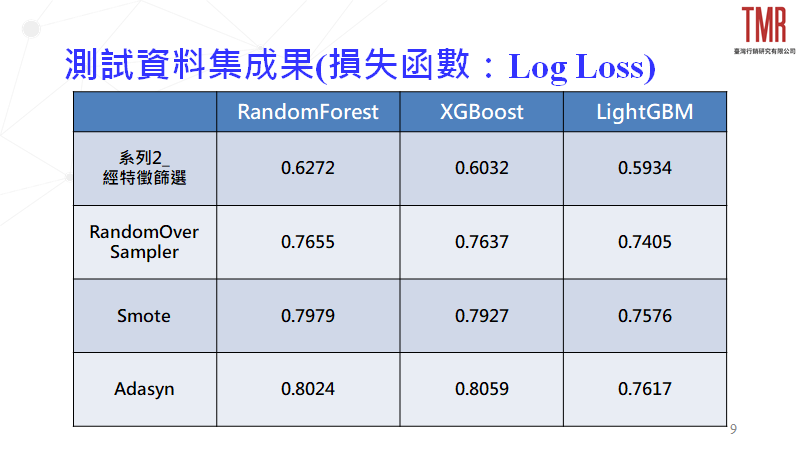
從圖6~8看到在該資料不平衡處理下,各模型的訓練資料集和測試資料集間的表現,於圖9與10能進一步了解處理資料不平衡是否能有效提高模型預測力,綜合以上4張圖,我們可以得出以下結論。
- 只使用特徵篩選做為資料前處理(未使用資料不平衡處理)的情況下,LightGBM能得出相對最低的損失函數,也就代表著使用此模型會得到相對較高的準確度,故我們將推薦業主以此模型去建立房屋詢問度之預測,以提升潛在成交率。
- 若單純為了降低損失函數或提高模型預測的準確程度,無須處理資料不平衡便可得到相對精準的成果。
- 就資料不平衡處理方式來看,RandomOverSampler表現最佳,代表該資料集若要處理資料不平衡的問題應以RandomOverSampler為主,能得到較為準確的預測,且其中表現最好的亦是LightGBM。
- 處理資料不平衡的同時,多數模型訓練資料集與測試資料集間的損失函數相差不大,代表沒有overfitting的情形產生。
到目前為止,這邊均以資料科學的角度判斷模型優劣。但大家別忘了!進行分析主要的目的還是希望能有效應用在現實中。因此,在未來系列4中,我們將以業界的角度來評估使用機器學習的成效,在商業考量下是否能更有效的協助業主提升潛在效益呢?不僅為大家帶來如何使用機器學習提高房仲業潛在成交率,更試著從業界觀點分析,結合兩種觀點達到最佳綜效!
參考資料:
Smote:https://bit.ly/3bqj3QB
Adasyn:https://bit.ly/3q4Iuez
Log Loss:https://bit.ly/33lpIpK、https://bit.ly/3esHs9j
以上就是如何使用機器學習提高房仲業潛在成交率_系列3_提升機器學習準確度的方法的完整內容囉
接下來我們將結合業界角度帶大家用另一層觀點作分析
讓大家收穫滿滿!
看完後,如果覺得喜歡,不妨幫忙拍個手吧!我會有動大的動力繼續寫…
下次見~
作者:陳政廷、王裕萍、謝豐檍(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究有限公司創辦人)
