歡迎來到Selenium facebook爬蟲系列的第一篇文章!
Facebook已經是一個幾乎每個人都會使用的社群平台,現代人在茶餘飯後無聊時都會使用社群平台,因此我們每個人都不知不覺在FB及IG留下許多資料。不管是按讚或分享喜歡的文章,或是在文章下留言表達自己對這件事的看法等等,社群平台都有留下記錄,長期來看就形成所謂的「大數據」。
本系列文章將和大家分享動態網頁爬蟲技巧selenium在FB的一系列應用~
利用Selenium自動登入FB有什麼好處!?
在開始之前先來告訴大家利用Selenium自動登入有什麼好處呢? 我們在爬取資料時如果每次都要自己填寫帳號密碼,應該會覺得很麻煩吧! 而且在展示給其他人看自己爬蟲成果時,採用自動登入除了節省時間,看起來也比較酷炫!
因此這篇會教大家利用Selenium爬取Facebook的第一個步驟! 也就是如何自動登入臉書並前往要爬取的粉絲專頁,如下影(一)所示!!!!
是不是覺得很神奇呢!
接下來我們就來學習如何達到上面自動登入的成果吧~
我們將分成兩個步驟說明:
1.自動填入帳號及密碼,並登入facebook
2.前往要爬取的粉絲專頁
1.自動填入帳號及密碼,並登入facebook
透過Chromedriver,並前往facebook 登入頁面。可設定要前往的網址,並利用driver.get(url)自動前往該畫面,如下程式碼。
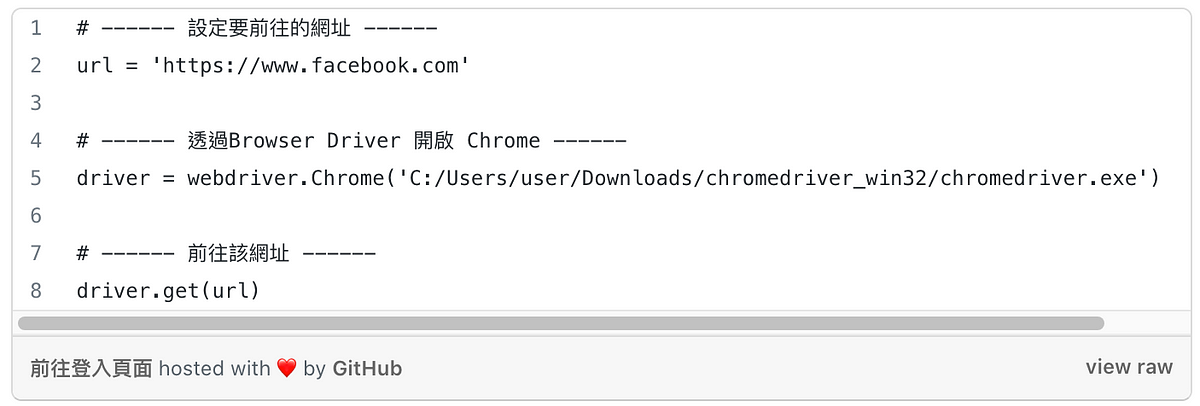
若想知道Chromedriver 是如何運作的朋友們,請點選:動態網頁爬蟲第一道鎖 — Selenium教學:如何使用Webdriver、send_keys(附Python 程式碼)
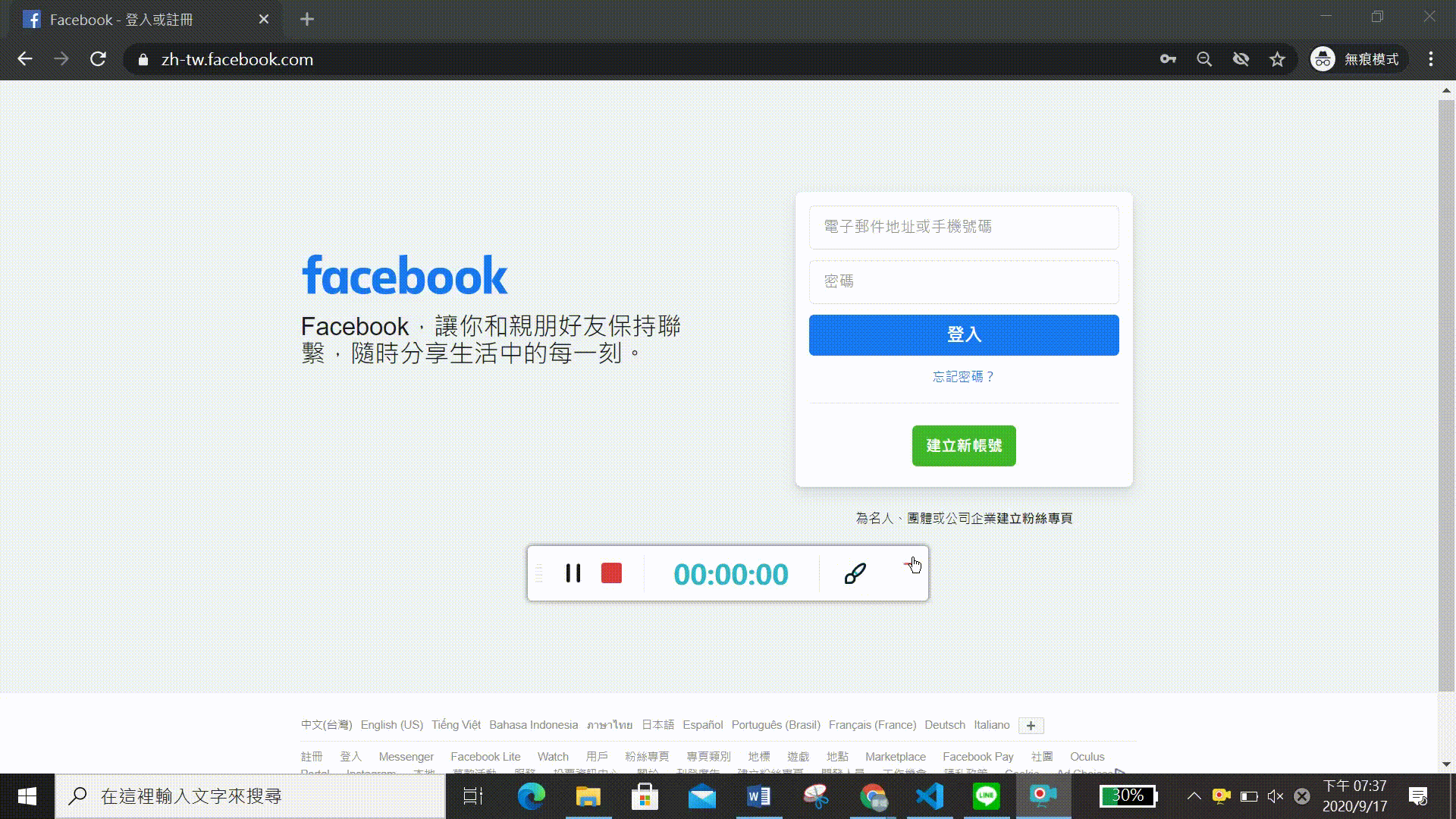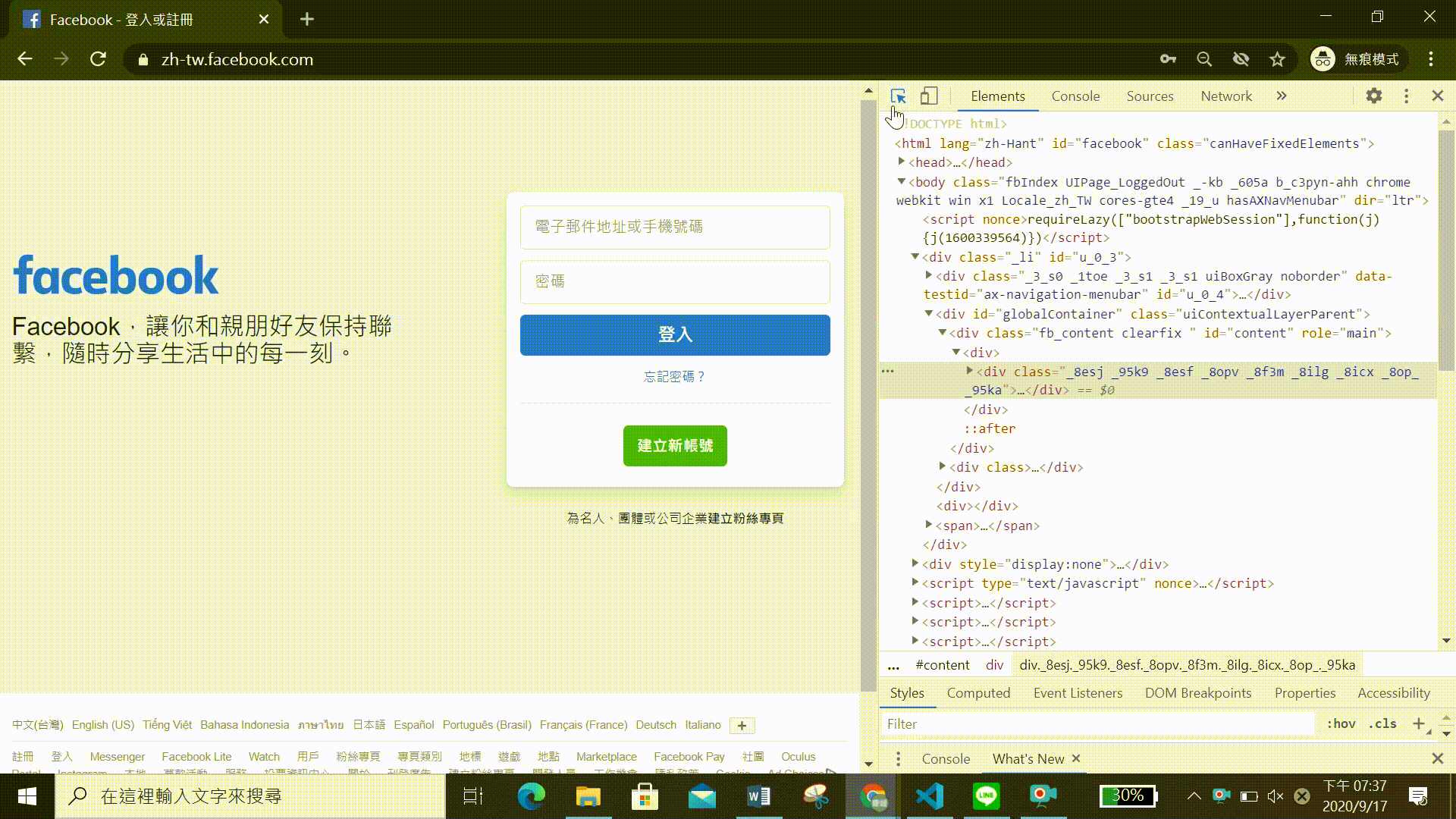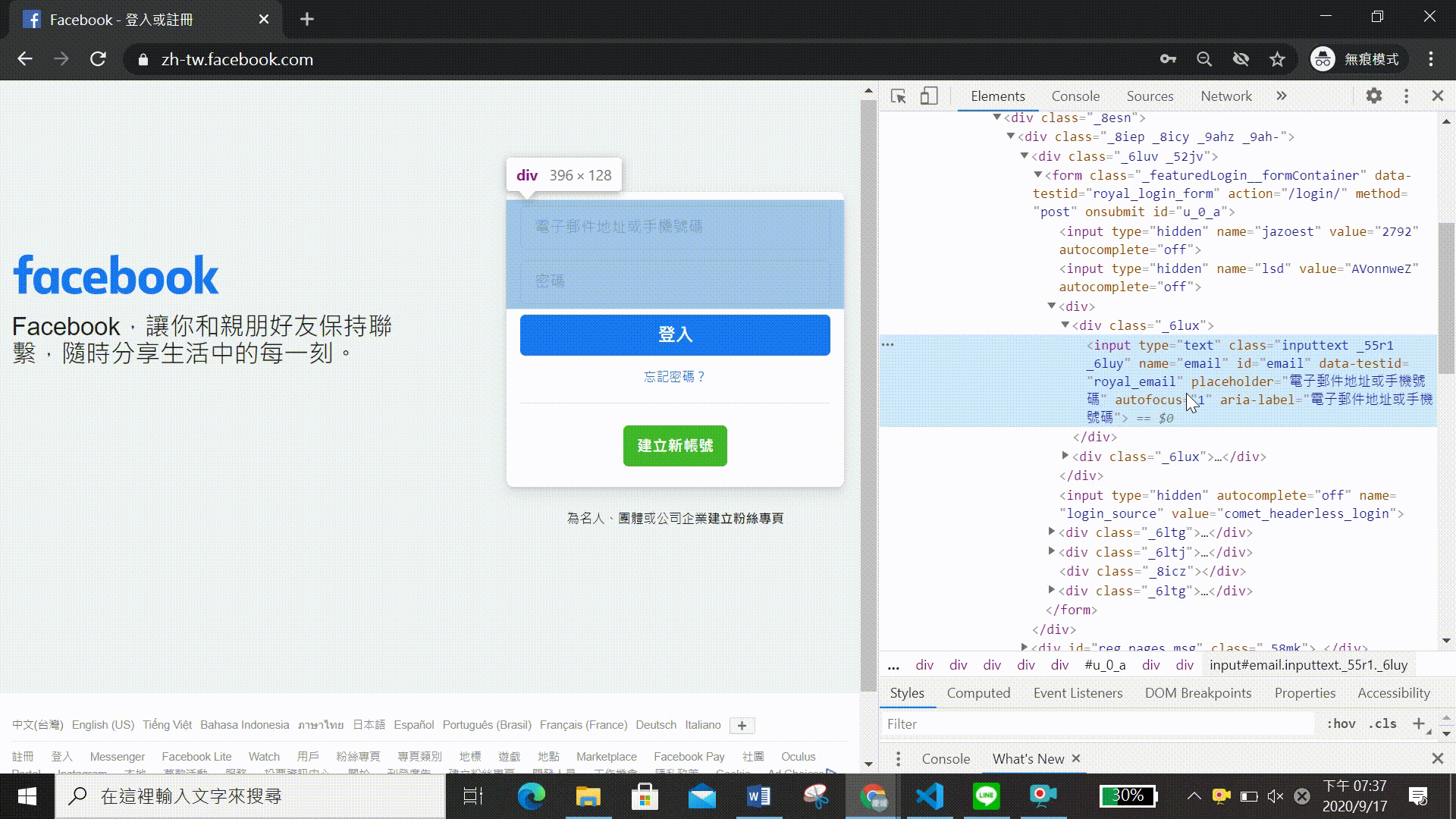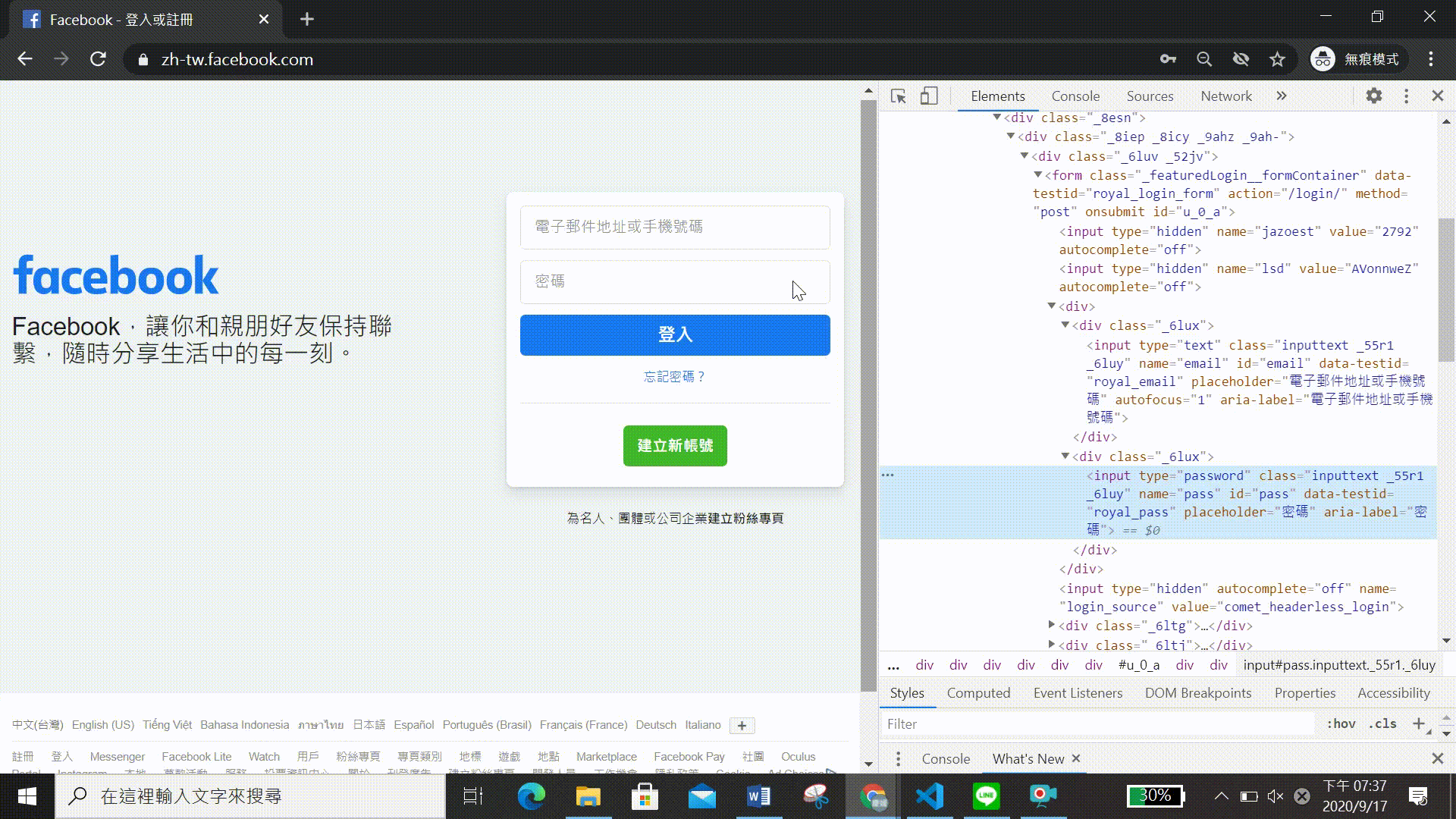
要達到第一個步驟前我們需要先學習如何找網頁元素,因此要先打開網頁檢視器(Windows系統:請按F12或者是ctrl + shift +i;MacOS系統:請按option+command+c)可以看到以下畫面(圖一)。
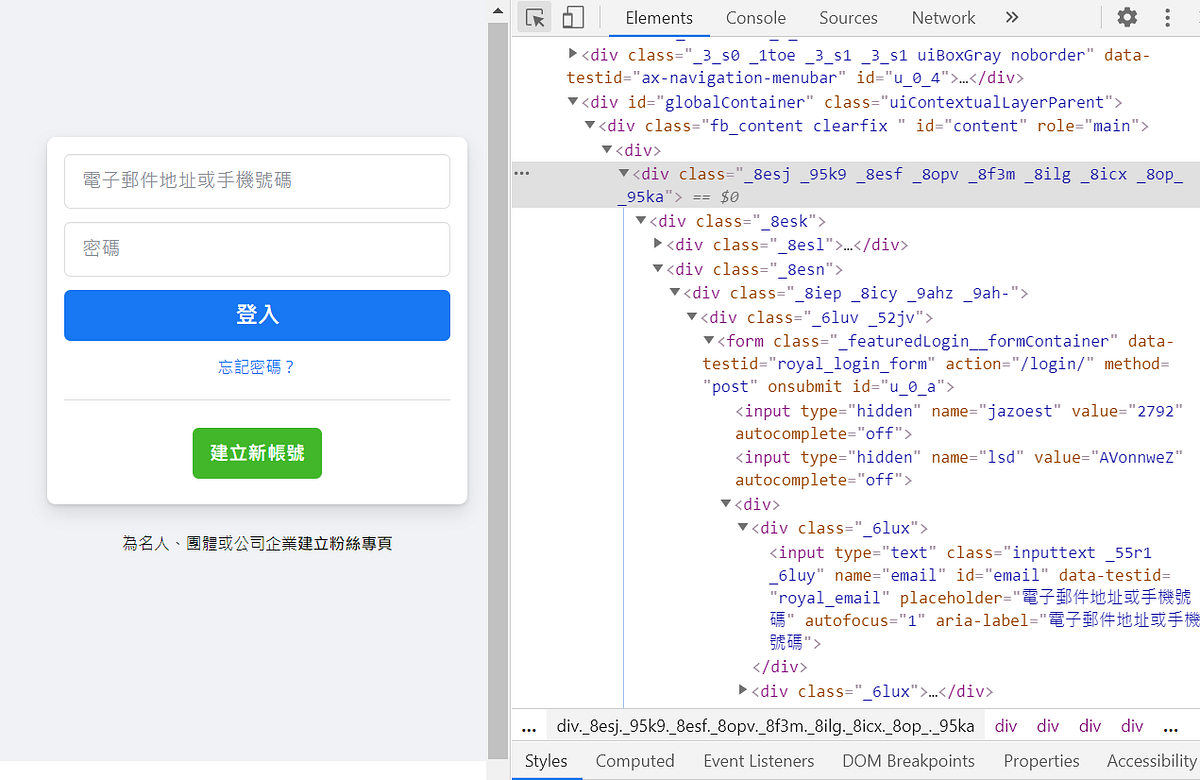
在網頁檢視頁面的左上角點「Elements」這個按鈕後(圖二),只要把滑鼠移置想爬取的位置,就可以檢視它的網站的元素了~
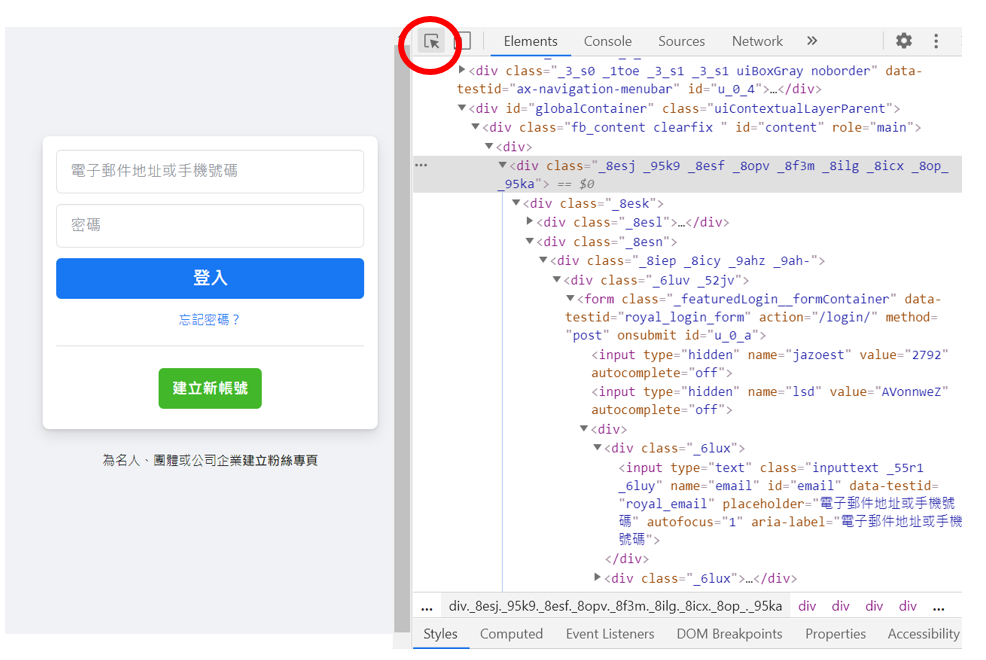
既然我們想自動登入facebook,就必須先查找網頁中輸入帳號及密碼的網頁元素。聽起來可能有點複雜,其實只要重複前面Chromedriver 開啟網頁及尋找網頁元素所提到的方法就可以了,以下會進行詳細的介紹,就讓我們繼續看下去吧! 步驟流程可見(影二)
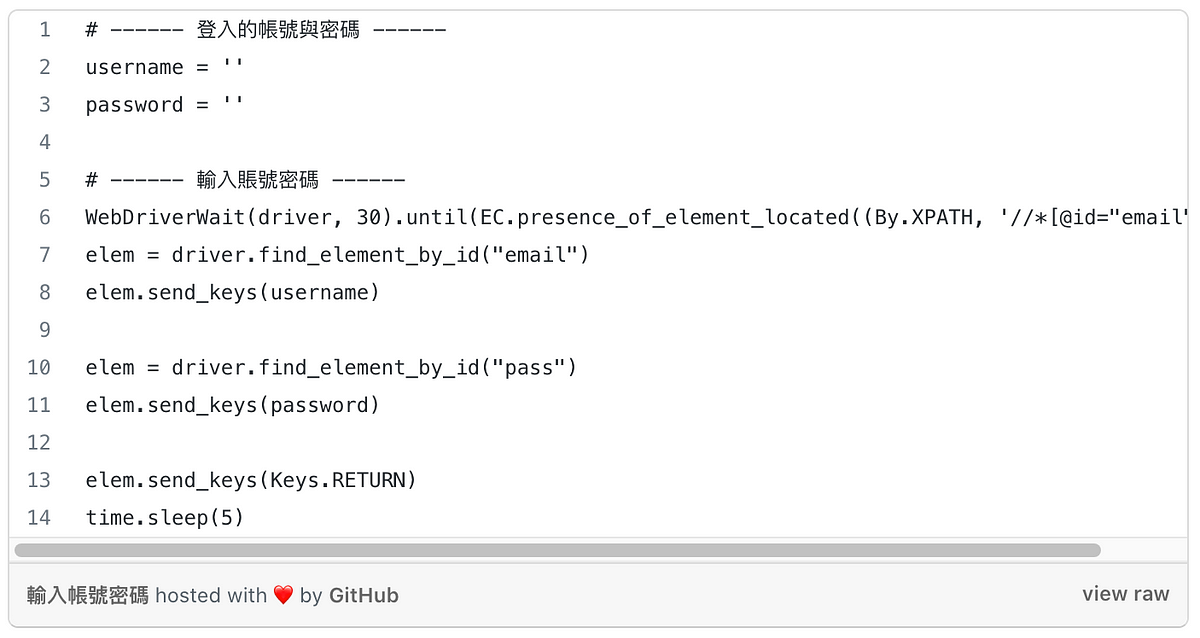
如果要找尋特定位置,通常會使用網頁元素中的id標籤,由上述步驟我們可以發現輸入電子郵件或手機號碼的id=email,輸入密碼的id=pass。找到網頁元素後只需用send_keys這個function就能自動輸入帳號密碼囉,如下程式碼所示!! 是不是很簡單呢~
2.前往要爬取的粉絲專頁
登入facebook後,我們需要再次利用強大的Chormedriver前往想抓取資料的粉絲專頁。這個步驟非常簡單,您只需在下方程式的spec_url填寫該粉絲專頁的網址,就能前往囉~
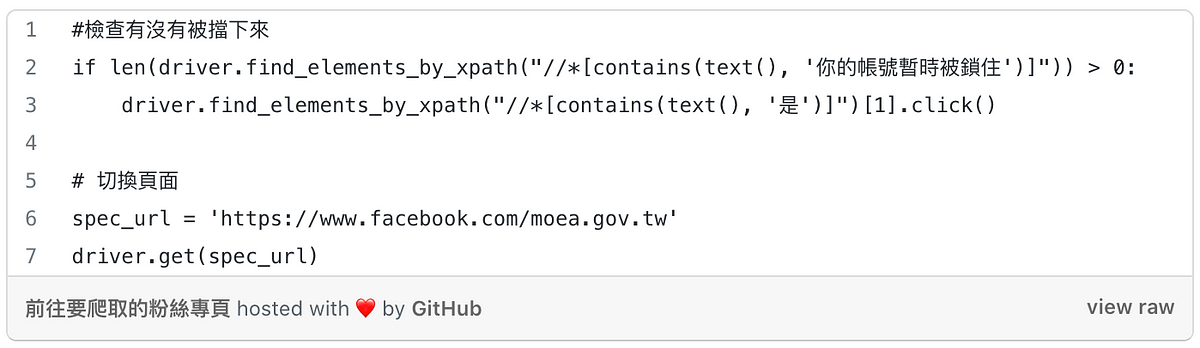
以上就是如何自動登入並前往特定粉絲專頁的教學,接下來Python FB 爬蟲系列的文章會分別介紹如何抓取不同的粉專資料,敬請期待!!!!!
可點此查看本篇完整的程式碼
如果對FB爬蟲有興趣的朋友, 要繼續關注這個系列的文章呦 !我們下次再見
作者:孔慶媛(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究有限公司創辦人)
