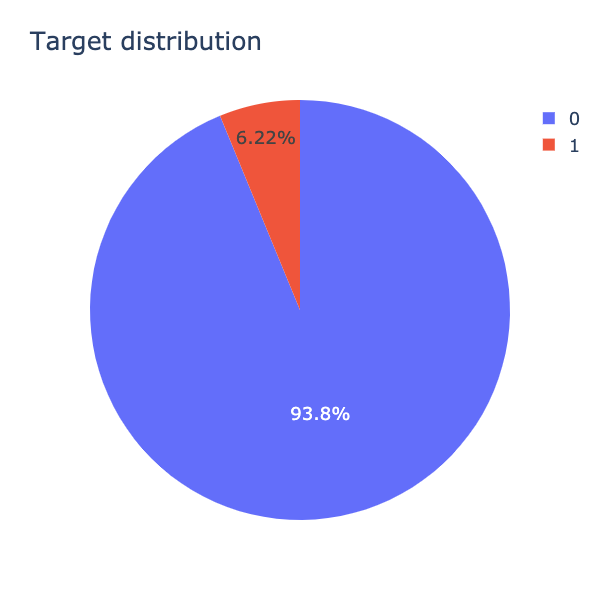
在〈自動篩選惡意言論,找出省錢關鍵! 情境介紹篇:敘述性統計分析〉的文章,我們已經對資料集的結構與資料內容有所瞭解了!資料的比數分配是極其不平均,正常言論佔了93.8%,而惡意言論卻只有6.22%(如圖1.),資料分配不平衡會影響機器學習的結果,那該怎麼辦呢?
不用擔心!本篇文章會一步一步帶領一起解決這些問題!首先,我們先了解資料不平衡會帶給機器學習什麼問題吧!全部程式碼可以參考GitHub!
資料前處理
資料不平衡 (Imbalanced Data)
我們可以看見資料被分類成正常言論與惡意言論的比例相距非常大,正常言論與惡意言論的資料比例為93%與7%,兩者資料量有非常大的差距,也就是說被歸類到惡意言論的數量非常少,資料數量不對等的狀況稱為資料不平衡(imbalanced data)。
現實中有許多資料不平衡的狀況,例如銀行絕大多數是正常交易,只有非常少數是盜刷紀錄。 還有,生產線上絕大多數是正常的商品,只有非常少數有瑕疵。
但資料不平衡會有什麼問題嗎?會有的,因為訓練模型中的正常言論的數量太多,所以模型預測正常言論的「準確度」可能會很高,但是預測出來的結果卻與現實差距很多,也就是說實際上模型並沒有有效率的學習到。Ching Tien在《心理學和機器學習中的 Accuracy、Precision、Recall Rate 和 Confusion Matrix》提到一個很生動的例子:如果今天有一個老師,他出的考卷 100 題有 99 題的答案都是 C ,如果你知道這件事,以後遇到這個老師出的考卷你就全部猜 C ,雖然你不一定有唸書,但每次都可以考 99 分上下,這時候準確率就不是一個好的衡量方法。 相同的概念也可以套用在極度不平衡的資料集裡!當我們的訓練集有太多的正常言論,電腦就想說猜正常言論就對了,而不是依照訓練資料做判斷,最終沒有達到機器學習的目的!
那我們應該怎麼做呢?
我們需要先對原始資料進行資料預處理 (如圖2.)。
Oversampling:
將少數資料量複製到與多數資料量一樣多。
Undersampling:
將多數資料量刪減到與少數資料量一樣多。
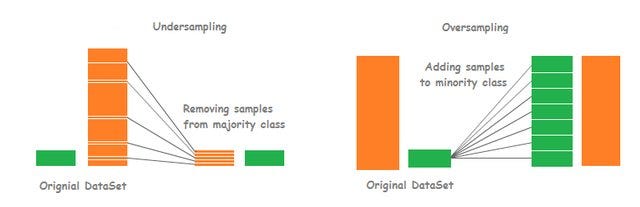
Oversampling 與Undersampling的方式有很多種,Oversampling常用的方法有RandomOverSampler、SMOTE、ADASYN,Undersampling的常用方法有RandomUnderSampling、CNN、Tomek Links。
我們這次使用imbalanced-learn套件中的RandomOverSampler與RandomUnderSampler模組!在經資料切分的訓練集資料中,有783,945則正常言論,51,972則惡意言論,總資料筆數為835,917則!
RandomOverSampler會隨機將少數的資料複製到與多數資料一樣的資料筆數。經過RandowOverSampler後,正常言論仍為783,945則,惡意言論則會複製至783,945則,總資料筆數為1,567,890則!(如圖3.)
RandomUnderSampler會隨機取從多資料集中取出與少資料集相同的資料筆數,因此,經過RandomUnderSampler之後,惡意言論仍為51,972則,正常言論則會取出51,972則,故總資料筆數為103,944則!(如圖3.)


雖然經過Oversampling與Undersampling的資料在訓練模型的時候就會比較準確了!但,資料還是電腦看不懂的文字形式,所以我們也需要進行詞向量,轉換成電腦看得懂的「詞向量」型態!
詞向量
我們資料集的輸入是問句,屬於「文字」形式,但電腦看不懂文字,所以我們需要將「文字」轉換成「向量」形式,如此一來,電腦才能使用這些文字。 這種以「向量」來表示每個字詞的方式稱為「詞向量」。
此次我們使用的是Google已經訓練好的的Word2vec資料,也就是說Google已經幫我們訓練好每個字的向量了,我們只需放進數字對應即可。不過「句子字串」丟入Word2vec 資料對應前,我們需要先將句子切詞,再統一長度,才能進行詞向量。
若想了解更多詞向量的應用,可以參考〈詞向量在商業的應用〉,此文例用商業案例深入淺出地介紹詞向量!


我們將「文字形式」的問句轉換成電腦看得懂的「向量形式」後,我們就可以開始來建立機器學習的模型了!
模型建立
我們嘗試四種模型處理方式,分別是Oversampling、Undersampling、無處理三種前處理加上GRU與Logistic Regression兩種機器學習模型,接著我們會介紹GRU和Logistic Regression兩種模型!
以下是嘗試的四種模型:
- Oversampling + GRU
- Undersampling + GRU
- None + GRU
- Oversampling + Logistic Regression
Logistic Regression
我們以最基本的Logistic regression分類模型作為基準,最後會在簡單地與後面GRU模型進行比較!(如程式碼3.)
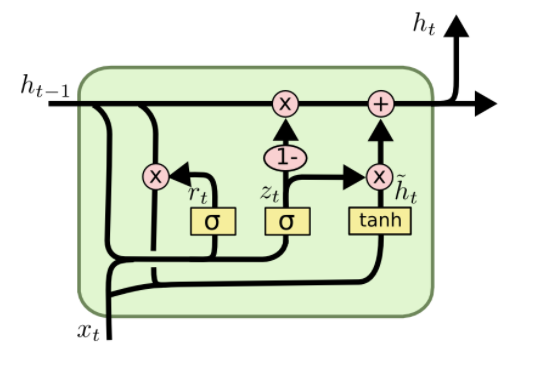
GRU(Gated Recurrent Unit)
進行完詞向量之後,我們可以進入模型訓練了!這次使用的是GRU(Gated Recurrent Unit)模型,是循環神經網路(RNN)的一種。
循環神經網路(Recurrent Neutral Network, RNN)是在進行自然語言處理(Natural Language Processing, NLP)常運用的演算法,因為語言通常考慮字句與前後文的關係,避免斷章取義。簡單來說,循環神經網路可以記憶前段文字,使學習效率與精確度更高!目前循環神經網路有三種模型:simple RNN, LSTM , GRU。simple RNN有無法很好捕捉長期記憶的問題,所以無法訓練長文本,因此誕生了simple RNN的變形:LSTM(Long-Short Term Memory network)與GRU(Gated Recurrent Unit)!
LSTM繼承了simple RNN模型的主要概念,但增加了「閥」的概念,「閥」可以選擇性地讓資訊通過!LSTM有「輸入(input)」、「遺忘(forget)」與「輸出(output)」三個閥,但LSTM有執行速度較慢的問題。因此,GRU繼承LSTM的內容,但以「更新閥(update)」取代LSTM的「輸入閥」與「遺忘閥」,並簡化來增加執行速度,如此一來,在資料集大的時候可以節省不少時間!這次資料集有幾十萬筆,因此使用較省時間的GRU模型!(如程式碼4.)
更多關於GRU的文章可以參考:TengYuan Chang在Medium的《比較長短期記憶模型 (LSTM) 與改良後的遞歸神經網路模型:GRU》與李宏毅老師的Youtube頻道!
建立好模型架構之後,就可以放入訓練集訓練了!
我們把train_X與train_y放進模型擬合!在訓練模型時,會需要以下幾個參數:
batch_size:
一次放多少資料近模型訓練,batch_size = 512,就是一次放512筆資料進去訓練。
epoch:
訓練全部資料幾次。epoch =2 ,全部資料訓練兩次。
validation_data:
驗證集。讓訓練集進行模擬考,來挑選或調整訓練出來的模型。
最後訓練好的模型,就可以來進行預測了!預測出來的結果若大於0.34506則為1,若小於0.34506則為0。


訓練完機器學習模型後,我們要怎麼評估這個機器學習模型的好壞呢?在資料科學分類模型分析上,我們常使用混淆矩陣評估結果,而在商業實務上,我們傾向用商業利潤的角度評估模型的好壞,這樣能讓管理者更一目了然!本文將以資料科學角度出發,使用混淆矩陣評估結果!
模型評估
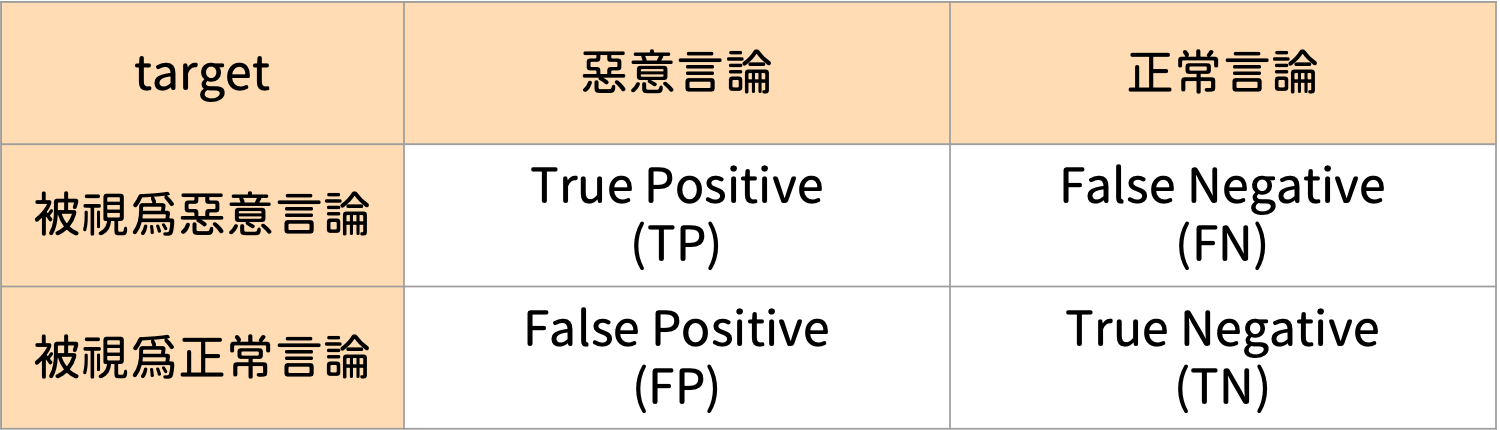
我們使用混淆矩陣(Confusion Matrix)評估結果,真實與預測之間共有四個關係,分別是True Positive(TP)、False Positive(FP)、True Negative(TN)與False Negative(FN)。其中FP(Type I error)與FN(Type II error)彼此之間是tradeoff的關係,也就是說,若希望FP小,則FN就會變大,反之亦然(如圖6.)。
我們會有幾個指標來評估模型的好壞,分別是:Accuracy, Precision, Recall, F1-score四者。
Accuracy
實際上預測正確的機率。Accuracy = TP+TN/ TP+TN+FP+FN
Precision
「預測」正確中「實際」正確的比例。Precision(準確率) = TP/(TP+FP)
Recall
「實際」為正確中「實際預測」正確的比例。Recall(召回率) = TP/(TP+FN)
F1-score
F1-score是Precision與Recall的調和平均。在Precision與Recall同等重要時,就可以使用F1-score來評估模型好壞。F1-score = 2/ (1/precision + 1/recall )
在我們模型中,我們認為正確言論被誤判成惡意言論與惡意言論被保留皆會對使用者與Quora平台有負面影響,因此我們希望在Accuracy在90%的條件下,F1-score越大越好!
以下是四個模型的結果!
- None + GRU
Accuracy = 95.7%
Precision = 62.7%
Recall = 70.7%
F1 score = 66.5% - Oversampling + GRU
Accuracy = 95.2%
Precision = 59.3%
Recall = 64.5%
F1 score = 61.8% - Undersampling + GRU
Accuracy = 84.9%
Precision = 27.9%
Recall = 94.1%
F1 score = 43.1% - Oversampling + LogisticRegression
Accuracy = 69.0%
Precision = 10.4%
Recall = 54.0%
F1 score = 17.5%
從上述條件比較,根據資料科學的觀點,第一個None + GRU最符合所需條件,Accuracy為95.7%,且F1-score最高為66.5%。
但如果呈現給管理者,管理者能夠馬上理解嗎?
我們要怎麼做,老闆才能馬上理解呢?
或許已經想到了!就是換成財務指標,能馬上明瞭,哪一個模型會是最好的決策依據?關於如何用商業利潤評估模型的好壞,我們會在下一篇文章和大家分享商業價值的分析成果!

參考資料:
- A look at different embeddings.!
- Google 的 Word2vec 模型
- Quora 2019年在Kaggle平台上舉辦的Quora Insincere Questions Classification 競賽。
- Random Oversampling and Undersampling for Imbalanced Classification
- Understanding LSTM Networks
- 心理學和機器學習中的 Accuracy、Precision、Recall Rate 和 Confusion Matrix
- 比較長短期記憶模型 (LSTM) 與改良後的遞歸神經網路模型:GRU
- 如何辨別機器學習模型的好壞?秒懂Confusion Matrix
- 循環神經網路(RNN) 概念參考資料
作者:葉庭妤、趙熙寧(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究有限公司創辦人)
