情境:
現今大多數的網站需要處理惡意與分裂性的言論。 Quora身為美國最大的問答社群,為了讓使用者能更安全地分享知識,Quora希望能找出模型有效預測惡意言論可以促進平台上的溝通。
任務:
原競賽要求根據問題敘述預測是否為惡意言論。 但我們再進一步評估以機器學習模型篩選惡意言論,Quora可節省下多少因惡意言論造成的金額損失。
預期成效:
以收益、節流省錢的前提下,找出最佳的機器學習模型!
本篇目的:
了解資料狀態與內容,以及惡意言論與正常言論包含了哪些字詞!
已提供的資料:
完整資料集可Kaggle上獲得!
- train.csv :訓練集
- test.csv:測試集
- sample_submission.csv: 應繳交成果格式
- embeddings:以訓練好的詞向量檔案
資料簡介
資料數量
因為最後我們想計算出模型可以省下的金額,需要與實際target比較。最終預測目標是找出能為Quora省最多錢的機器模型!
- 訓練集:1,044,897筆資料,變數包含 qid,question_text,target
- 惡意言論:64,954筆
- 正常言論:979,943筆
2. 測試集:261,225筆資料,變數包含 qid,question_text,target
變數介紹
- qid:問題的辨識碼,每個問題不重複。
- question_text:問題敘述。
- target:是否為惡意言論。1為惡意言論(insincere),0為正常言論(sincere)。以下舉訓練集中惡意言論與正常言論各一則。
- 惡意言論:Why do most Palestinians support terrorism?
- 正常言論:How is strategic positioning is different from marketing positioning?

資料基本訊息
在本篇文章中,我們主要以敘述性分析為基礎,找出分別在問句中含有惡意意涵與正向意涵的可能字詞有哪些!系列二則會以機器學習模型自動篩選惡意留言,敬請期待系列二文章哦!
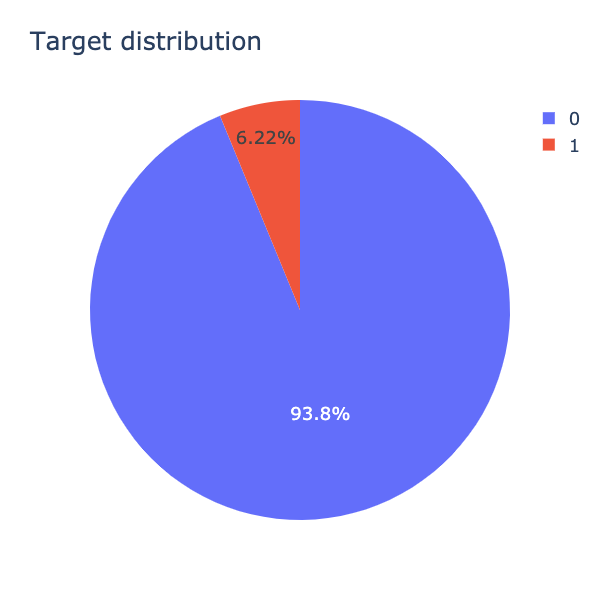
我們利用圓餅圖查看一下資料的狀況(如圖3.),93.8%的言論被分類為正常言論(標記為0),只有少許的6.22%是惡意言論(標記為1)。大部分Quora平台的文章都是正常言論,只有極少部分是惡意言論,資料的分佈極不平均,相差15倍之多!
惡意言論包含哪些字詞?
我們已經了解資料基本內容與言論分佈狀況,接著,我們可以進一步了解被歸類為惡意言論與正常言論可能分別包含哪些字詞!
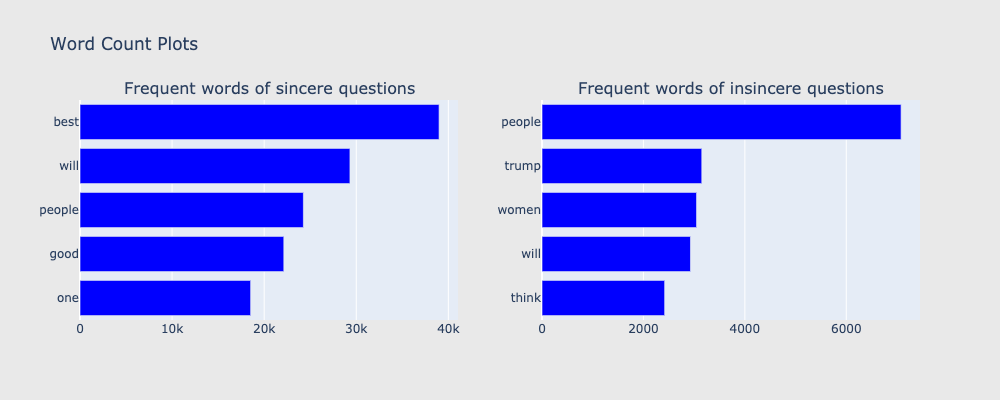
舉例來說,若以一個字作為切分單位的話(如圖4.),我們可以看到在正常言論中可以看見前五名分別是best、will、people、good、one。然而,在惡意言論中,出現頻率最高的五個單字分別為people、trump、women、will、think。然而,根據單字,我們不太能知道單字可能的意涵,例如正常言論與惡意言論皆有people,然而,兩種的people可能指涉不同的people,可能是指white people也可能是black people。
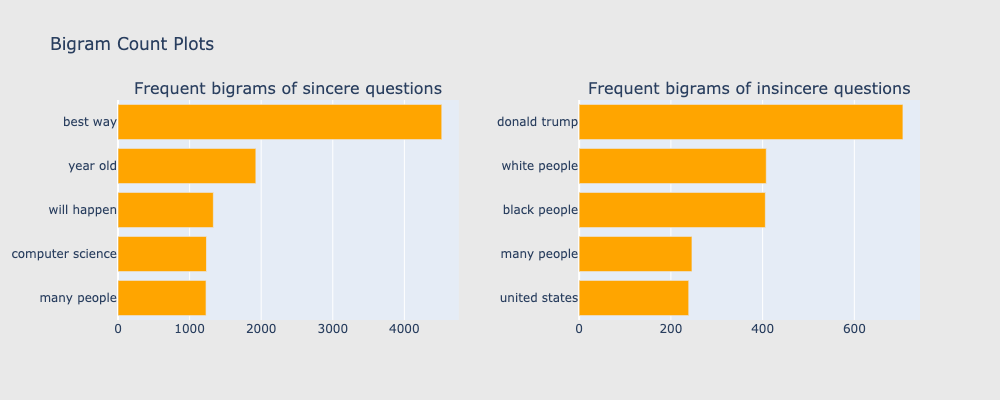
因此,我們進一步去對問題做雙字的切分,雙字詞讓我們更清楚理解兩種問題中的字詞!(如圖5.)舉例來說,在正常言論中的前五名字詞分別為best way、year old、will happen、many people、computer science,在惡意言論中,頻率前五名的字詞為donald trump、black people、white people、 many people、united states。我們就能很清楚地看出單字詞中的people分別是指哪些!
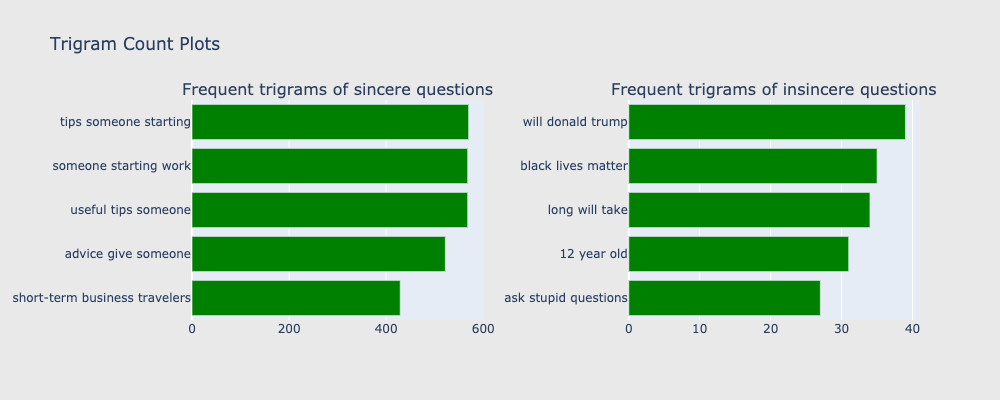
若我們更進階以「三個單字」切分為一單位,我們能更清楚欲保留問題和欲刪除問題分別傾向會有哪些字詞(如圖6.),在正常問題中,頻率前五名的單詞分別為tips someone starting、someone starting work、useful tips someone、advice give someone、short-term business travelers,從上述五個單詞可知正常言論多與尋求建議與協助有關,這些問題對於Quora欲營造友好知識社群氛圍有正面益處。
然而,有趣的是,在惡意言論中,will donald trump、black lives matter、long will take、12 year old、ask stupid questions,這些字詞多涉及種族年紀等敏感問題或是語調不友善,對於Quora平台氛圍有負面影響,也符合Quora 篩選欲刪除留言的標準。
我們已經看完一百萬筆資料的基本敘述性統計,也對正常言論與惡意言論內容已經有基礎理解!若以人工查閱方式審閱這些惡意言論,不僅耗時、也耗人力,另外,字詞配上不同組合會影響是否為惡意言論,例如:雖然在惡意言論中donald trump比例很高,但是donald trump與其他字詞組合仍可能在正常言論中出現。所以,若我們能可以利用機器學習找出惡意言論的字詞組合,並且判斷出惡意言論的話,便能省下不少的成本!那接下來,我們在之後系列二文章會正式說明如何進行機器學習與資料前處理!
參考資料:
- Quora 2019年在Kaggle平台上舉辦的Quora Insincere Questions Classification 競賽
- Scikit-Learn — train_test_split
- Simple Exploration Notebook — QIQC
作者:葉庭妤、趙熙寧(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究有限公司創辦人)
