談到精準名單,您會想到什麼?
當我們談到精準名單時,我們第一個常常會想到的是,根據用戶特點、興趣或以往的購買行爲,精準的向「用戶」或「舊有客戶」推薦有興趣的商品或服務,進而讓其轉變成我們的「新客戶」。然而,多數行銷人接下來會告訴我們的是:「什麼推薦不推薦的? 什麼用戶推薦清單?簡單用FB等網路行銷的方式就可以了啊,爲什麼還要針對舊有的客戶制定推薦清單?」
這段話講好像很有道理,但真的是如此嗎?
用FB、GA網路行銷即可,要自己做精準名單?
請讀者仔細回想一下自己行業會「持續」爲您創造獲利的客戶是誰?這些客戶通常會以舊有客戶(舊客)爲主,哈佛商業評論在《The Value of Keeping the Right Customers》這篇文章中提過:「開發一個新客的費用是留舊客費用的5–25倍」,這表示留住一個舊客遠比帶進一個新客更划算(圖1)!

所以我們的重心應該聚焦在如何讓「舊客回流」,再由舊客的那兒賺來的錢,再持續投資新客。然而,多數人的焦點都放在「如何以網路行銷的方式吸引新客,而不是想辦法創造舊客回購」這件事情。
讀者或許會問:「當我們客戶很少、商品數量還不多的時候,現階段還不需要CRM資料的管理吧?外面CRM廠商的系統都很貴呢!」
我們則認爲,企業如果哪天事業有成,或者剛好趕上「產業浪頭」,突然想要開始擴張,但是卻發現沒有完善的「舊客資料庫」, 使我們原來可以賺上幾倍盈利的空間,卻恍然成了「空」…。所以,我們認爲企業應該從小就要爲自身的客戶資料記錄上下功夫,以自己的領域知識,一點一滴的建立自己的客戶資料庫。哪怕我們是以最簡單的Excel sheet做記錄,在這「資料即原油」的時代下,每一筆正確資料對企業都是無上至寶,因爲最後及可再以機器學習的方法提煉原油,完成所要的「客戶精準名單」!
客戶精準名單概念 + Python實戰演練~GO!
所以...
- 資料蒐集:具體來說,最簡單的客戶資料要以什麼樣是形式創建?
- 精準名單:有了這些有用的客戶資料後,要怎麼做出精準名單?
且讓我們以情境個案搭配Python實戰,步步講解!
備註:情境個案因保密問題,將以真實個案經轉換之虛擬個案分析呈現。
情境主題:
- 產品:某甲公司的A商品/服務
- 通路:以實體通路行銷爲主,電話、email行銷爲輔
- 價格:$ 2,500元新台幣
- 成本:$ 750元新台幣
- 行銷與廣宣相關成本:$ 175元新台幣 / 攤到每位顧客
- 資料蒐集:已有蒐集過往舊客資料,並且測試了45,211位舊客(to C)對A商品的實際購買狀況(購買 = 1;無購買 = 0),以便對甲公司其他舊客做有效的行銷
- 面對難題:想知道不同商品(在此以A商品爲例)的客戶精準名單,以便知道我們對每一客戶的應該推薦何種商品
客戶資料蒐集的考量要素
客戶資料要以什麼樣是形式創建?相信讀者其實可從圖1中看出一些端倪,這時候我們可以花1分鐘想想,圖1的資料結構包含了什麼樣的元素?
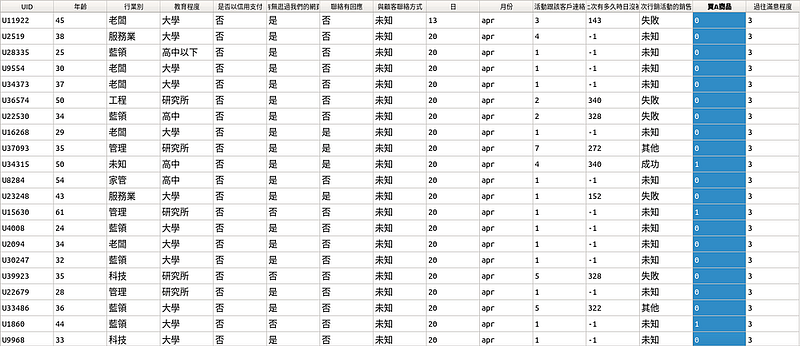
細看圖1,不難發現,蒐集資料要考量的要素:
- 人口變數:每一位客戶購買本商品時,管理者會想要知道的顧客資訊,如圖1的客戶年齡、行業別、教育程度等與客戶切身相關的變數。特別要注意的是,這些變數通常難透過後天的行爲所改變(通常不可變動)。
- 行爲變數:該變數通常會由該知識領域的專家進行制定,如圖1呈現的全部活動跟該客戶連絡次數、與顧客聯絡方式、過往滿意程度等公司可以直接或間接控制的變數。
- 主要行爲變數:即指公司主要要觀察的重要變數,如圖1的是否買A商品或成交不同的商品等。
其實在客戶資料庫中,尚可包含諸多種類的變數,但以我們輔導的經驗觀察,如果中小企業能將上述3種變數做好蒐集工作,便已經有相當程度的水準可以進行「客戶精準名單」的分析了!
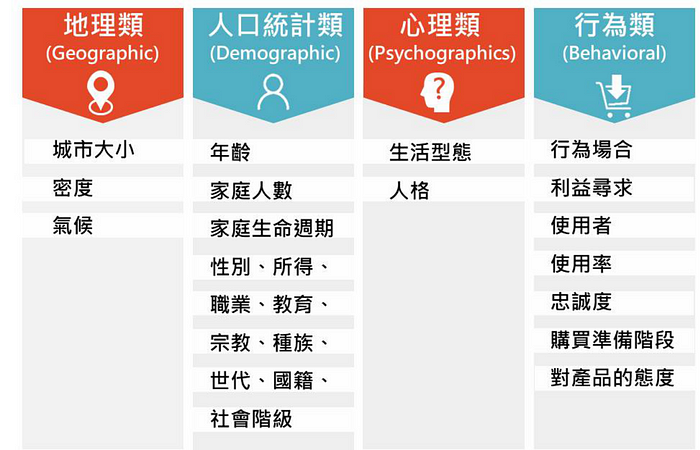
如果讀者想深入瞭解其他的區隔分類,可參考圖3。如果您對市場區隔有興趣,歡迎參考:
概念文章:選擇行銷市場的關鍵 — 市場區隔(Segmentation)
個案探討:「顧客標籤」悄悄透露你我的DNA
經濟實惠的蒐集管道?
那透過什麼管道蒐集?其實要蒐集資料,最經濟實惠的方法即是「問卷與訂單」。如果我們的產品夠吸引用戶購買或者深深的打到用戶痛點,便可於客戶購買產品時,以問卷或訂單的形式針對欲蒐集的資料進行提問,蒐集其人口變數,行銷人員進而再以行銷手法記錄客戶的「行爲變數」,逐步完善自己的客戶資料庫!
製作客戶精準名單
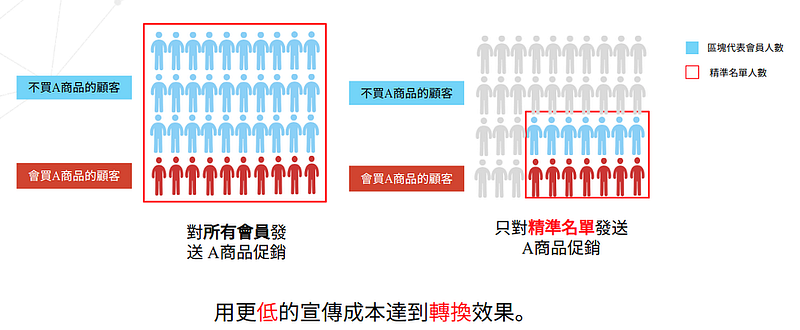
以機器學習製作客戶精準名單的好處在於,傳統我們在客戶資料庫中,會對「所有客戶發送A商品促銷」,但是透過機器學習,我們就可以抓出顧客名單,「只對精準名單發送 A商品促銷」(見圖4)
接着,我們使用「即時動態定價「實做 2」 — 集成模型(附實現程式碼)」文章中所使用的XGboost機器學習演算法,進行精準名單的分類預測!
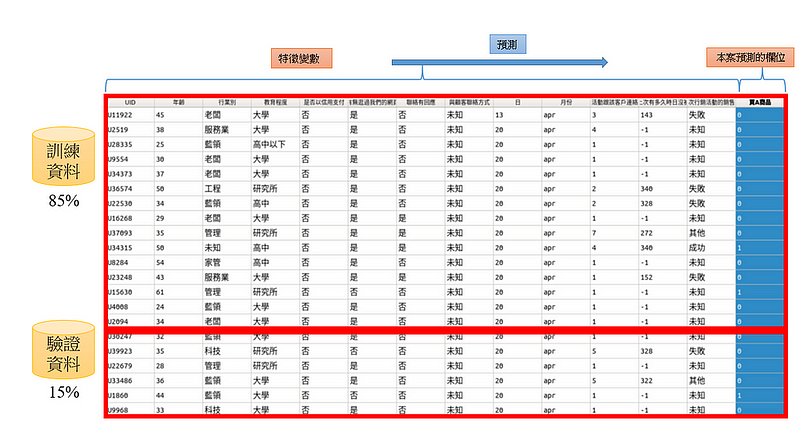
精準名單的機器學習架構(圖5)是:
- 切分80%的訓練資料集,作爲模型訓練使用;與20%的測試資料,驗證模型的效果
- 人口及行爲變數(自變數)對甲公司最想要知道的「是否購買A商品」進行預測(依變數)
- 找出每一個客戶預期會購買A商品的「機率」
- 再由高至低排序客戶購買機率
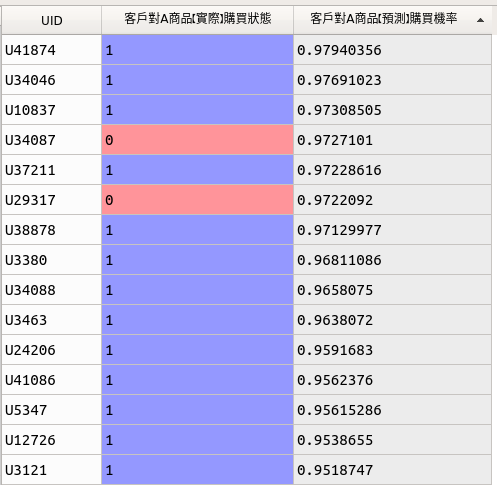
我們可看到圖6製作出來精準名單的結果(以20%的測試資料進行預測效果測試):
- 客戶對A商品【實際】購買狀態:代表客戶實際有購買A商品,當我們落地實際操作客戶精準名單的時候,其實是不會有該欄位的,在此會出現該欄位是因爲要讓讀者直觀的體會「預測」與「實際」狀況的比較,讀者可以自己實地操作文章附帶的Python程式碼,仔細查看圖7的詳盡結果
- 客戶對A商品【預測】購買機率:代表機器學習預測顧客購買A商品的機率,機率越高,則顧客越有意義購買A商品,而這便是我們落地實際操作客戶精準名單最爲重要的結果
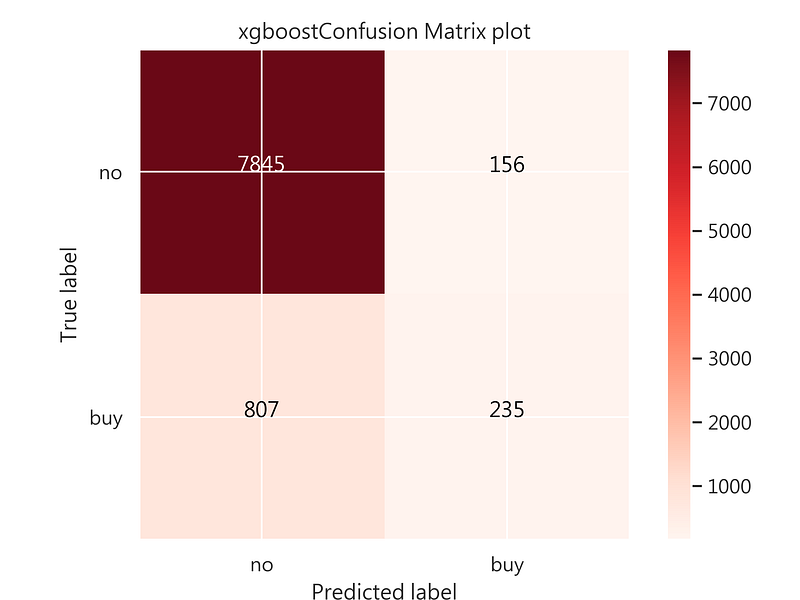
- 根據Confusion Matrix,Precision爲60%(235/391),對於線下爲主的甲公司來說,這效果算是不錯!
而這份名單的管理意涵有:
- 管理者可根據對A商品「預測」購買機率高的客戶推薦A商品
- 管理者可以依照「只要一張圖!透露誘惑消費者買到剁手的最佳優惠定價!(附贈Python程式碼)」本篇文章的區隔方法,將購買機率比擬成「價錢」進行區分,然後對不同程度的「購買機率」制定行銷方針,舉甲公司的案例來說,甲公司可以將行銷資源放在購買舉例高達9成的客戶,或者也可以將行銷資源投放到購買機率僅有50%左右的客戶身上,刺激其購買之可能性。
最後,我們來看看本案例所造成的效益(圖7),只對精準名單發送的效益(34萬的評估利潤)是大過於對所有會員發送的效益(24萬的評估利潤)!當然這精準名單的利潤還要在扣除資料蒐集、機器設備、資料科學專案合作等費用,不過以長期的成效來說,使用精準名單的效果要比以往的方式要佳。

還有疑問?
閱讀至此,讀者可能還會有些疑問,舉凡來說:
- 面對的客戶資料往往是時間序列形態,該如何預測下一段期間客戶會不會購買?
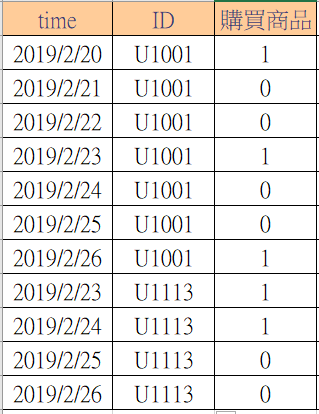
- 資料的蒐集還要配合成本考量,難道我們要永無止境的蒐集不同的變數?除了本文提到的專家法之外,有沒有方法可在一定時間內評估資料變數增減的必要性?
- 還有什麼方法可有效提昇「預期獲利」?該如何進行?
- 該如何製作精準名單的成本利潤矩陣?
…
這些實務上常遇到的問題及更多說明,我們都會在【 AI 行銷學:用 Python 機器學習創造商業新價值】中實戰說明!也歡迎各位讀者參考下述相關資訊!
本文程式碼:
作者:鍾皓軒(臺灣行銷研究有限公司 創辦人)
