啊? 簽約?都是B2B阿? 要用精準行銷技法?
當談到「簽約」這件事情時,我們的刻板印象通常是公司對公司(B2B)之間的合約,合約的簽訂是拼業務、產品品質或者人脈經營所締造,這又與「行銷」及「機器學習」有何種關係? 說白一點,這似乎與獨立的個體(我)沒有甚麼太大的關係。
但真的是如此嗎?請大家仔細回想一下,我們在這一生中以個人名義到底簽過何種約?仔細回想一下,理應不難歸納出以下幾種合約形式:
- 手機合約:現今人人皆有手機,而我們通常會與電信供應商簽訂個人化契約,獲取如499、699網路吃到飽套餐等服務。
- 信用卡合約:「任刷1筆帳單,即享5%現金回饋,刷滿10筆,即享10%現金回饋!」類似的廣告都無所不在的存在於我們每日的生活中,相信只要是在職者,有1到2張的信用卡都不為過,而擁有信用的前提,同樣也是要完成個人化契約的簽訂。
- 線上合約:嗯? 線上合約? 如果您是雲端使用者,一定在熟悉不過如github、線上課程、防毒軟體等付費軟體,皆是個人化契約的常見範例。
在上述常見的三項「簽約」種類中,相信讀者們已經發現了企業為何欲用「機器學習」的方法來「行銷」個體客戶,同時也可以發現B2C的公司主要的客戶不在是企業個體,而逐漸轉移到了個人層次的經營。
在個人層次的經營上,企業主要會遇到常見的幾項痛點:
- 簽約客戶數以億計,誰會解約? 誰會續約?
舉例來說:github公司擁數以億計的顧客,每個人可能都因為該公司的服務狀況而放棄合約。每個月都會有數千萬的客戶合約到期,這些到期的客戶中,到底誰會解約? 又要如何預防解約? - 是廣告投放,還是隨意濫發?
雖然網路雲端服務商大量投放廣告(例如:優惠券)的成本相對於實體商店來說,成本根本相對低廉,但是到底要選擇「精準投放」? 還是「隨意投放」給簽約客戶? 這都是一門重要的學問。 - 機器學習做完,然後呢?
多數資料科學家對於機器學習技法早就駕輕就熟,但是多數結果評估出來僅是給老闆準確率,尚缺乏實質的「期望獲利」等金錢指標。
如果企業to C客戶已經多到不可勝數,已非經驗直覺可控,那我們一樣可採用之前所撰之自動採購文章的方法(當零售業的「採購」遇到機器學習時?!(附Python程式碼)),以機器學習找尋出可能之受眾,並評估實際獲利。
本次筆者一樣使用「相對廉價(5萬元)」的電腦,為讀者輕鬆實踐「Python機器學習 — 精準行銷評估顧客帶來的預期獲利」方法。
小提醒:Python機器學習實作會牽涉到模型評估指標、機率計算、獲利評估等科學與數學方法,如果對管理意涵有興趣的讀者,可直接跳至最後的【管理意涵】章節。

Python機器學習 — 評估顧客帶來的預期獲利 Go !
簡單講解過簽約的概念及問題後,接著,我們要深入行銷資料科學的「資料科學」領域,使用一真實線上服務商之零售資料進行分析,以Python 3 進行「評估顧客帶來的預期獲利」機器學習實戰!
情境主題:
- 產品:A公司主打的線上服務P產品
- 通路:100%的網路媒介
- 價格:$ 5,000元新台幣
- 成本:$ 884元新台幣
- 行銷文宣成本:$ 500元新台幣 / 每位顧客
- 銷售:A公司提供30天的免費線上服務 — P產品,期望期限內顧客能正式簽約購買P產品之服務
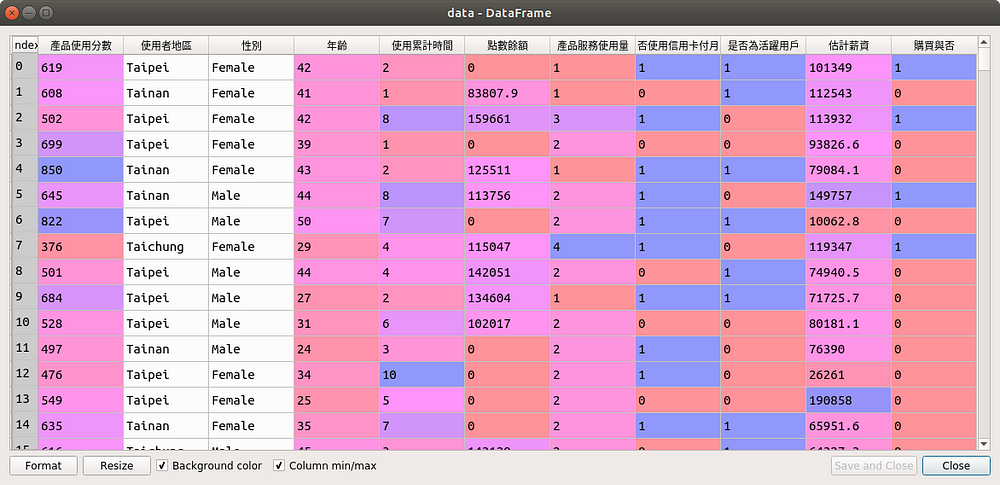
- 資料蒐集:目前已經有蒐集個別天數的每一消費者是否對P產品的實際購買狀況(購買 = 1;無購買 = 0),本次提供的為10,000位顧客使用第7天時購買狀況之資料集,詳見圖1
- 面對難題:
- 每隔1–2天便對數以萬計的顧客發送電子行銷文宣,不但購買率低下,甚至造成諸多客訴
- 顧客之預期獲利以人工經驗評估之,沒有量化或模型工具之協助,不曉得到底應該使用廣告全投放還是機器學習模型來做投放?
- 不甚清楚客戶對哪個欄位特徵感興趣,讓A公司可以使力在該特徵欄位
資料來源:
A公司同意之真實線上零售資料為基底進行實做,並且已將敏感變數移除、屏蔽、更名及全部變數加工處理。
模型方法與損失函數:
本次機器學習模型主要以 Random Forest(RF)、XGBoost(XGB)、LightGBM(LGBM)三種模型進行分析預測。其原因為樹狀模型建模容易、解釋容易且較其他模型來說精準度更高。損失函數部份則使用分類常用的 Log-Loss(Cross-entropy loss)進行分類損失函數數值評估。
目標變數(或稱依變數):
購買與否:每一客戶對P商品的購買狀態,這是我們要預測的變數,購買=1;不購買 = 0。
標籤(或稱自變數):
- 產品使用分數 — 依據A公司估算每位顧客每天於產品使用上的流暢程度
- 使用者地區 — 總共有台北、台中與台南共三個地區之資料
- 性別 — 男、女之類別變數
- 年齡 — 使用者年齡
- 使用累計時間 — 使用者使用A公司任一產品時間
- 點數餘額 — 使用者對A公司產品總點數餘額
- 產品服務使用量 — 使用者每天產品使用程度
- 是否使用信用卡付月費 — 使用者支付方式是否為信用卡
- 是否為活躍用戶 — 使用者在A公司的評估中,是否為活躍使用者
- 估計薪資 — 使用者在A公司的評估中,所估計的可用薪資
資料購買比例之敘述統計:
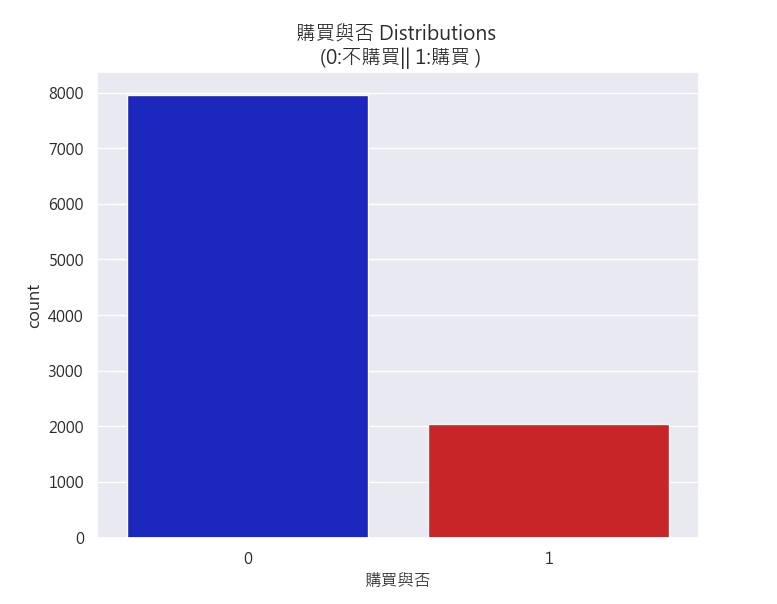
我們可發現這10,000筆資料中,購買與不購買呈現20/80的比例分佈(見圖2),為一不平衡資料集(imbalanced dataset),不過本次先不考量不平衡資料集所造成的困擾應之解決方案,我們直接以三種模型進行預測性建模!
不購買比例 79.63 % of the dataset
購買比例 20.37 % of the dataset
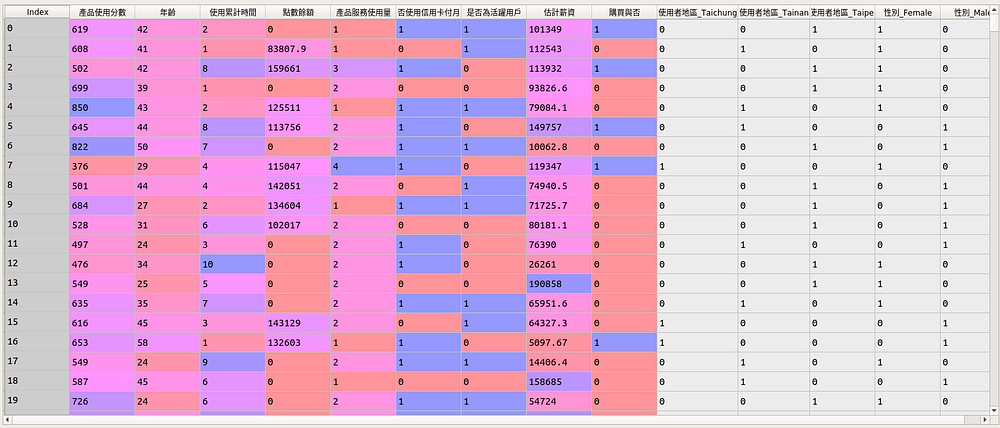
機器學習建模:
機器學習建模前,老樣子我們一樣先將類別變數 — 地區及姓別進行 One-Hot Encoding(見圖3),轉換為下述資料型態:
如欲知 One-Hot Encoding 的概念,請見本提問回覆
接著~ 我們就開始來簡單建模啦!
三種樹狀模型比較:
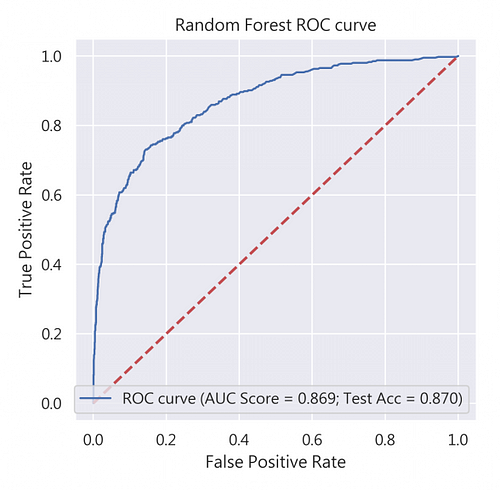
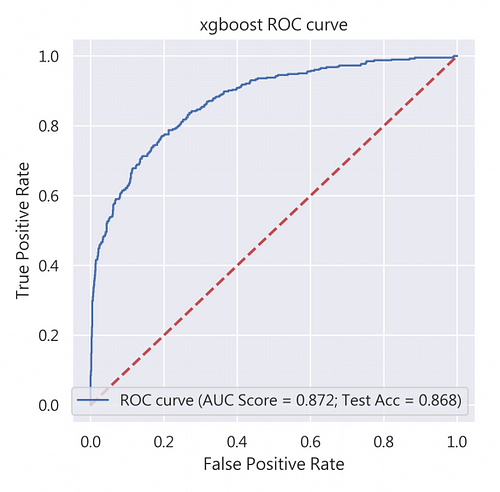
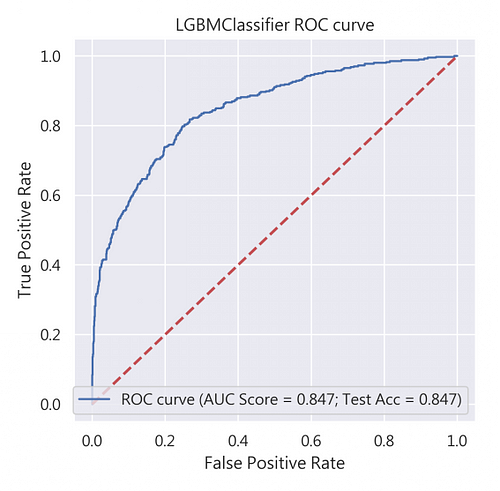
我們在此比較了Random Forest(RF)、XGBoost(XGB)、LightGBM(LGBM)三種模型的ROC曲線、AUC分數及測試資料集的準確度(Test Accuracy),見圖4,可發現RF的準確度最高!所以就決定RF當作我們最佳、最適當的評估模型吧!
這時候身為行銷資料科學家的我們得到這好消息後,立馬跑去跟老闆報告最好的模型 — RF!讓我們大展伸手,直接使用該模型來預測第7天會購買的消費者吧!
老闆這時見獵心喜,看過2009年哈佛商業評論一篇短文 — 「棄權」領導學,要適時放權給員工去做,所以也沒多想太多,相信自家的行銷資料科學團隊準沒錯!於是乎,便直接授權團隊執行。
所以… 分類模型的準確率就是一切嗎? 這麼簡單!?
以技術上來說,準確率當然是評估不同模型最適合不過的指標,我們時常看到Arxiv、SCI、SSCI等高等級論文,近乎皆以準確率當作標準進行模型好壞的評估指標,但我們仔細想想,當準確率這個評估指標遇上不平衡資料集、商業目的性的不同及預期獲益之評估時,我們就不能一味盲目的相信準確率這項指標。
所以行銷資料科學有一重要的部分即是要恰當的評估建模需求,因此行銷資料科學家應該要仔細考慮模型的實際應用方式,並擬定相應的度量指標。舉例來說:
- 從不同評估指標中以成本及營收作考量,找出預期獲利最大的模型,這樣對於商業才真正有用武之地
- 使用不同取樣技術(Sampling technique),將不平衡資料集進行調整,找出獲利最大獲之模型
- 利用20/80法則,找出分類上最適當的獲利曲線
看起來… 還不是清楚到底哪些指標可以使用?
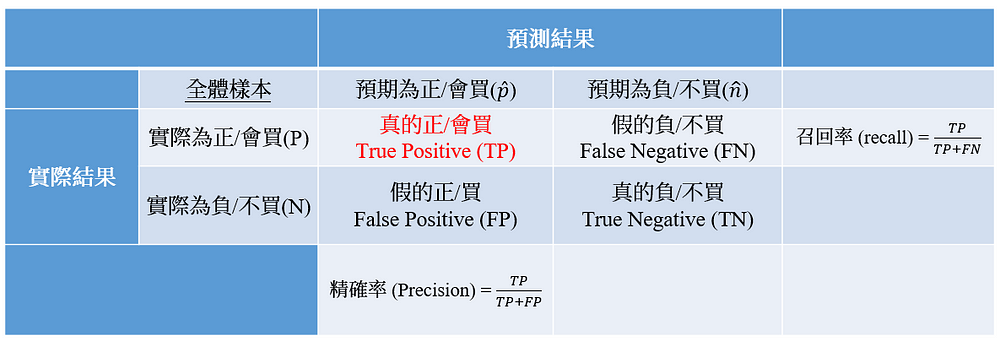
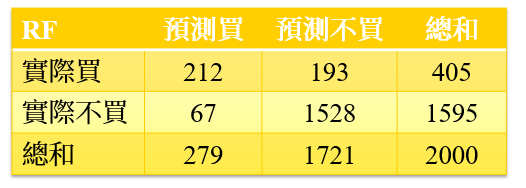
這時候我們就會使用到混淆矩陣(Confusion matrix)的兩種概念 (見圖5) — 精確率(Precision)與召回率(Recall)(見圖),在商業上,我們最希望的就是Precision與Recall兩者比例都可達到接近於1,不過這通常是非常難發生的,所以我們就要從不同模型中抉擇我們最想要的指標。
- 召回率(Recall) — 成本低廉的線上商業活動建議使用
代表的是在實際會買的顧客中,真正會買的顧客有多少比例。該指標我們會應用在線上簽約、買賣、服務等效益評估,因為當我們要求Recall高的時候,犧牲的通常是Precision,相較造成「假的正/買(FP):錯誤預測會買的人」數量衝高,不過線上(online)投放廣告成本相對線下(offline)低廉,所以行銷資料科學家能透過模型增益「真的正/買(TP)」,但犧牲「FP」,來達成效益最大化之目標! 這件事背後所代表的管理意涵是「在網路行銷成本成本相對低廉的狀況下,哪怕錯誤預測會買的人多(FP多),我寧願多投放給可能購買的人(TP高+FP高),因為只要有多一個人買,我網路行銷成本相對來說就賺回來不少了!」 - 精確率(Precision) — 成本高昂的線下商業活動建議使用
代表的是在預測會買的顧客中,真正會買的顧客有多少比例。該指標則會應用在線下活動、保安等寧可精準也不可濫投的高成本及高報酬商業活動,因為當我們要求Precision高的時候,犧牲的通常是Recall,相較下會造成「假的負/不買(FN):錯誤預測不買的人」數量衝高,所以當我們舉辦行銷成本非常高昂的活動時,瞄準的一定是高消費顧客,方足以支應行銷成本,所以行銷資料科學家能透過模型找出精準「真的正/買(TP)」(在不平衡資料集下,要求更精確的Precision,TP數量相對會更少),但犧牲「FN」,來達成效益最大化之目標! 這件事背後所代表的管理意涵是「在線下活動高昂成本的基礎下,哪怕真正會買的人(TP較少)相對較少,且錯誤預測不買的人多(FN多),我寧願高成本投放給更精確會購買的人(TP中等+FP非常低),因為只要一個人進行大筆的消費,行銷成本便能因大筆的消費金額中快速賺回!」
雖然可以針對不同的商業目與兩種指標來挑選適合的模型,不過我們通常還是會要求兩者之間需要在至少0.4或0.5以上進行平衡,否則將等於該模型沒有正常的預測效力。
針對這些指標,有具體的應用範例,而且真的有效果嗎?
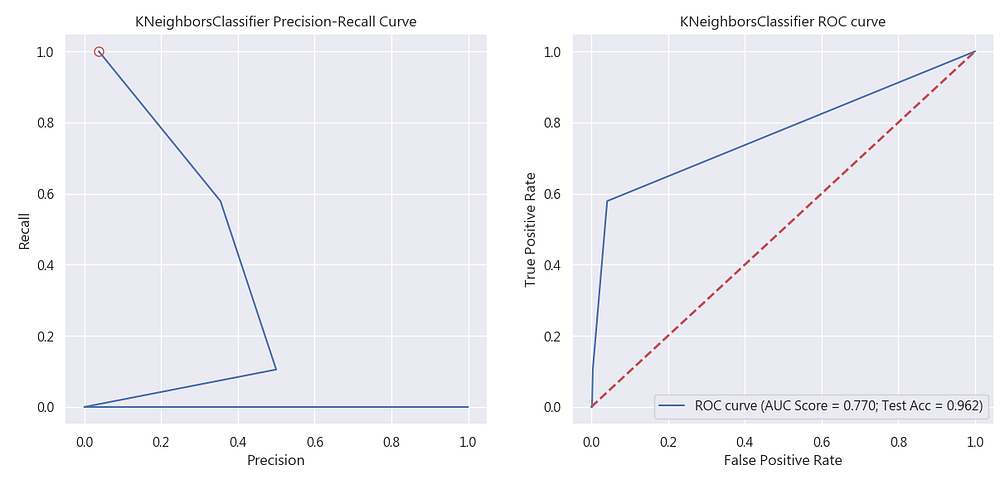
針對於精確率(Precision)與召回率(Recall)我們會使用所謂「Precision-Recall Curve」來了解分類於商業使用上的好壞。讓我們隨機取一98%不購買,僅有1%購買的不平衡資料集(見圖6)來進行測試:
請見文末對應程式碼:precision_recall_case.py
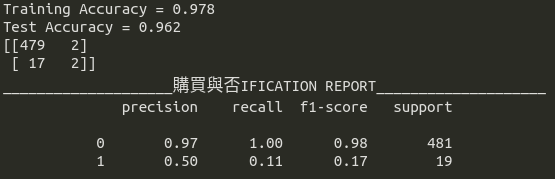
對其進行KNN的簡單分類,從圖7中可以發現其實ROC曲線的分數還不錯,AUC分數可以達到77%,測試資料集的準確率更達96%,如果僅看ROC曲線,很容易發現這似乎是一個不錯的分類器,但我們如果看Precision-Recall Curve,就會發現這實際上是一個不好的分類器,當Precision為50%時,recall僅有11%
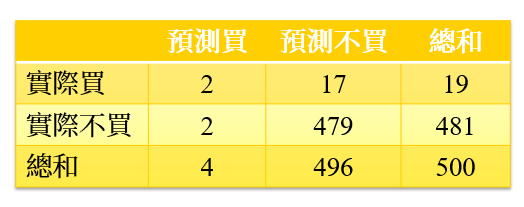
從圖8中,可以看到如果使用該分類器結果進行廣告投放,結果僅建議投放4人,結果2人購買,如果損益兩平點在7人以上,該模型絕對會被棄卻採用,但這時剛入門的資料科學家可能會因為準確率而建議公司使用該分類器,從圖8的表現中就知道這可虧大了。同時,這就是為何我們堅持precision與recall至少要在穩健的0.5以上的原因。
講解了許多機器學習成效的評估觀念,接著就讓我們將Precision-Recall Curve應用本文案例吧!
請見文末對應程式碼:contract_one.py
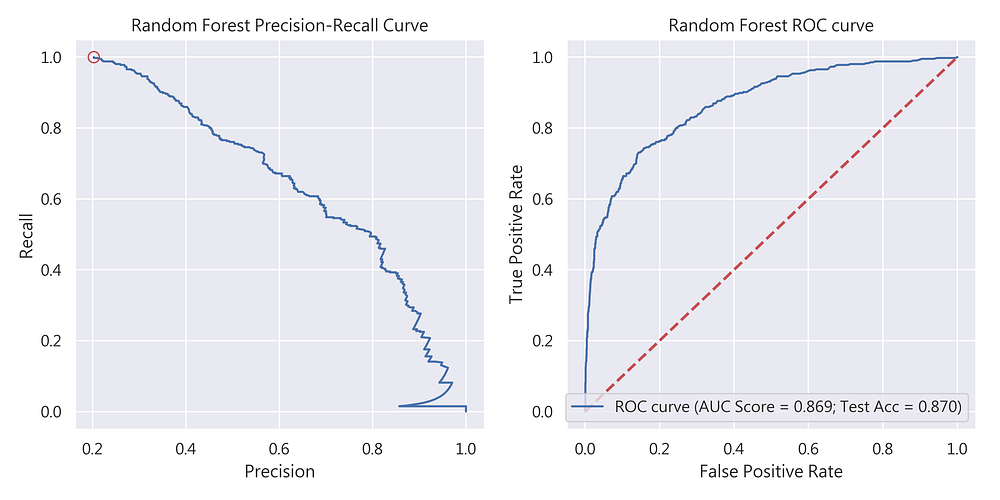
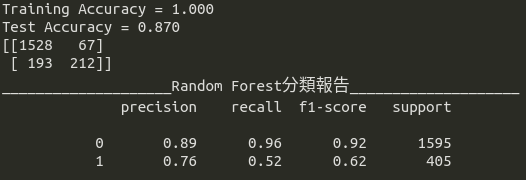
隨機森林(Random Forest)
首先登場的是隨機森林,從圖9我們可看到其測試資料集準確率為87%。Precision-Recall Curve的表現也相當不錯(precision = 0.76;recall = 0.52;非常符合precision與recall 至少0.5以上的標準),建議可作為預期獲利的候選模型之一。
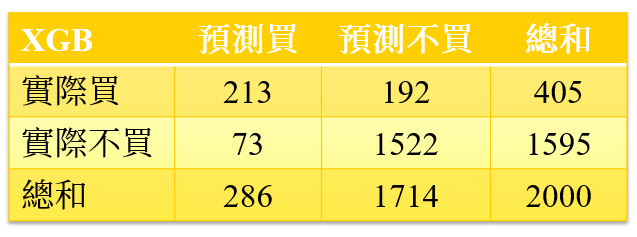
eXtreme Gradient Boosting(XGBoost)
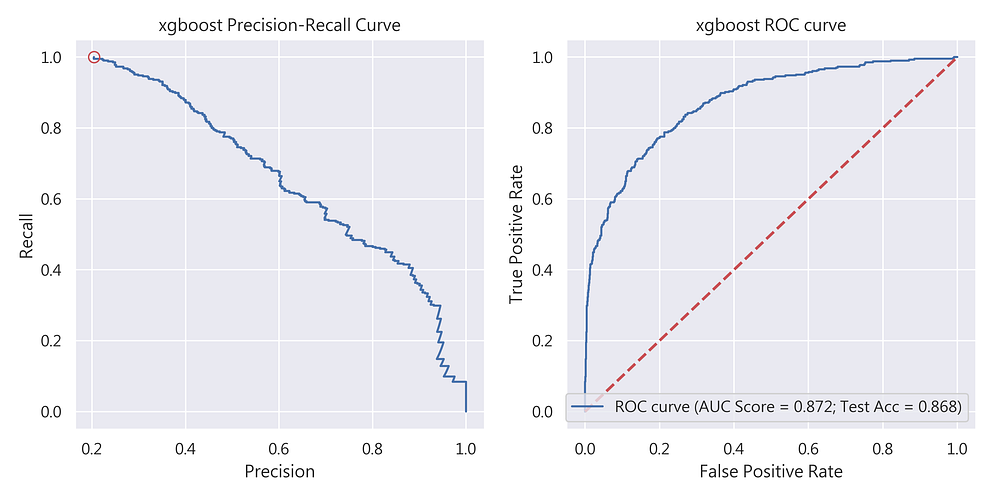
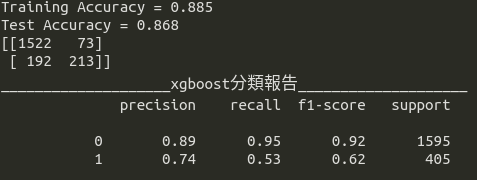
其次登場的是XGBoost,從圖10我們可看到其測試資料集準確率為88.5%。Precision-Recall Curve的表現也相當不錯(precision = 0.74;recall = 0.53;非常符合precision與recall 至少0.5以上的標準),建議可作為預期獲利的候選模型之一。
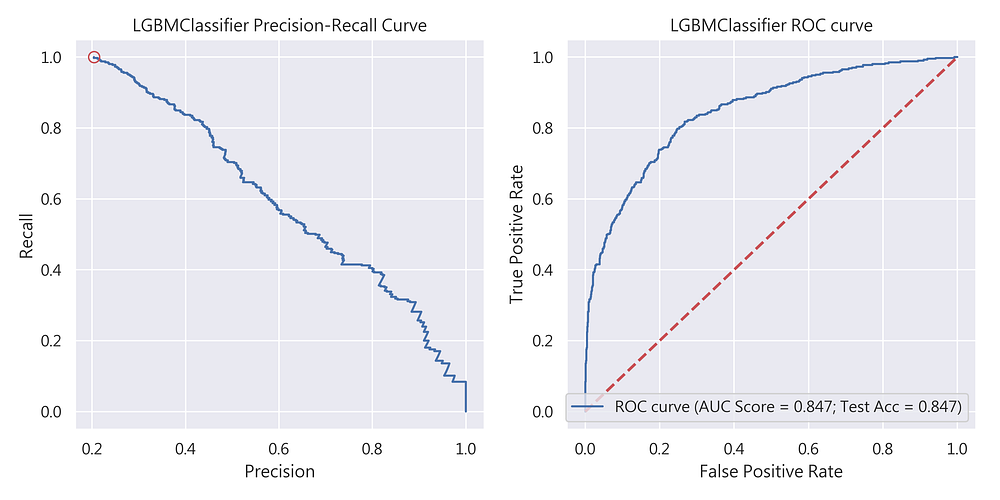
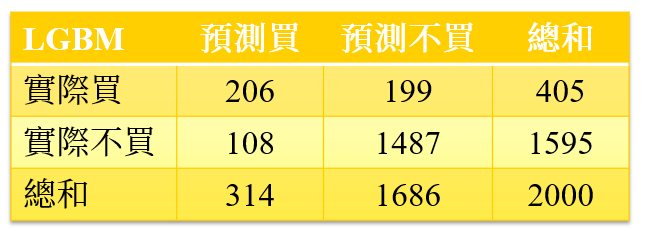
Light Gradient Boosting(LGBM)
最後登場的是LGBM,從圖11我們可看到其測試資料集準確率為84.7%。Precision-Recall Curve的表現也相對較差(precision = 0.66;recall = 0.51;符合precision與recall 至少0.5以上的標準),同樣建議可作為預期獲利的候選模型之一。
那… 那… 這些模型,應該如何與預期獲利結合?
預期獲利的機率計算
闡述了這麼久,建模也完成了,終於來到要與預期獲利結合的單元了!不過在進行預期獲利部份計算前,我們還要先了解計算時應考量的兩個因素:

成本效益矩陣
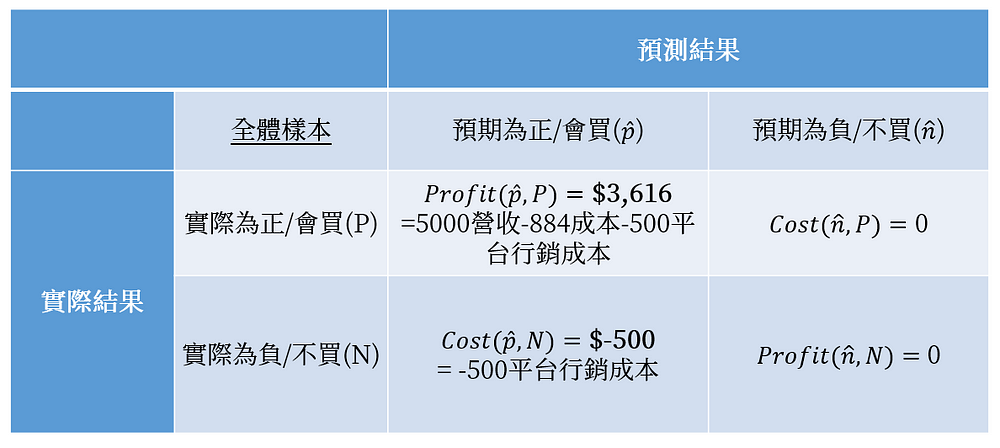
接下來我們在由混淆矩陣中產生圖12的成本效益矩陣,該矩陣代表的意涵為:
- Profit(p ̂, P)
此種情況為獲得廣告訊息且願意購買的顧客,代表企業獲利為$3,616元/每位顧客 - Cost(p ̂, N)
代表我們寄送了廣告訊息,但是顧客沒有回應,所以這筆固定花費為$500元/每位顧客 - Cost(n ̂, P)
代表該群顧客被預測不會購買,但是實際狀況是會購買的,這種情況下,我們沒花任何錢,顧客也沒有任何購買行為發生,所以為$0 - Profit(n ̂, N)
代表我們不發給這群顧客廣告訊息,實際上他們也不會產生購買行為,所以無獲利,同時也沒有成本$0
預期獲利機率模型
接下來,我們將預期獲利的機率與成本效益矩陣進行結合,產生「預期獲利機率模型方程式」,得出各自期望值的方程式如下圖13:
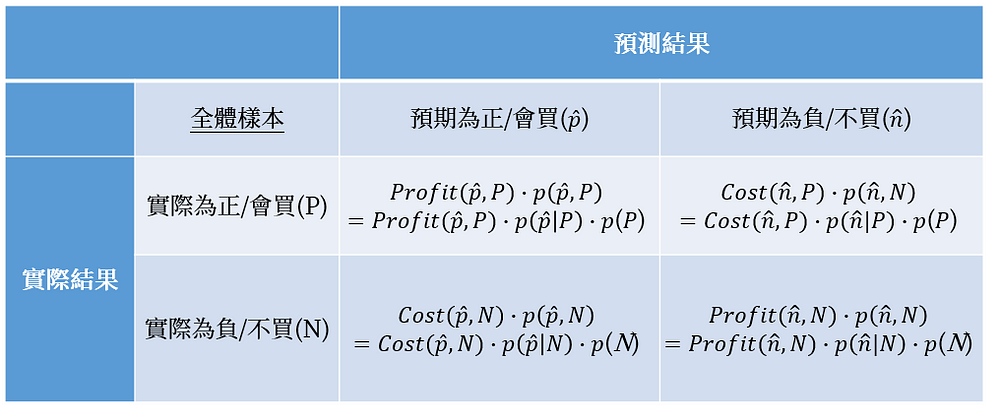
最後,我們再圖13的4組期望值的方程式各自加總,成為「預期獲利機率模型」:
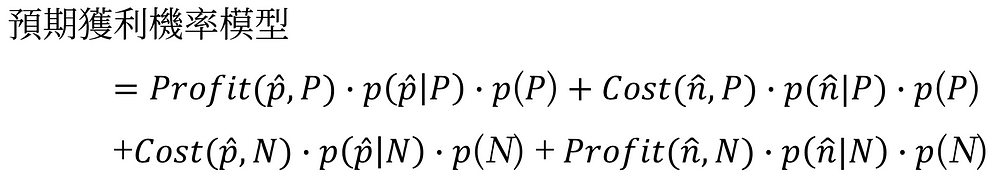
再將 p(P)與p(N)分別提出來,我們就可以分解出圖14的兩個模型出來:
- 第一行就是【在全市場中,客戶真實會購買的預期獲利】
另一種機率觀的解釋方式為,該位客戶在會購買的事件發生下,我們投遞廣告給該客戶後,該客戶購買該產品事件又同時發生所產生的期望獲利及成本 - 第二行【在全市場中,客戶真實不會購買的預期獲利】
另一種機率觀的解釋方式為,該位客戶在不會購買的事件發生下,我們不投遞廣告給該客戶,該客戶不購買該產品事件又同時發生所產生的期望獲利及成本

最終預期獲利機率模型之計算
最後,我們使用預期獲利機率模型以及三種樹狀模型各自的混淆矩陣進行評估,可以得到:
隨機森林(Random Forest)期望獲利 = $366.546;代表我們使用隨機森林(Random Forest)投放給被模型分類會購買的客戶,我們就能預期獲平均每位客戶$366.546元的獲利
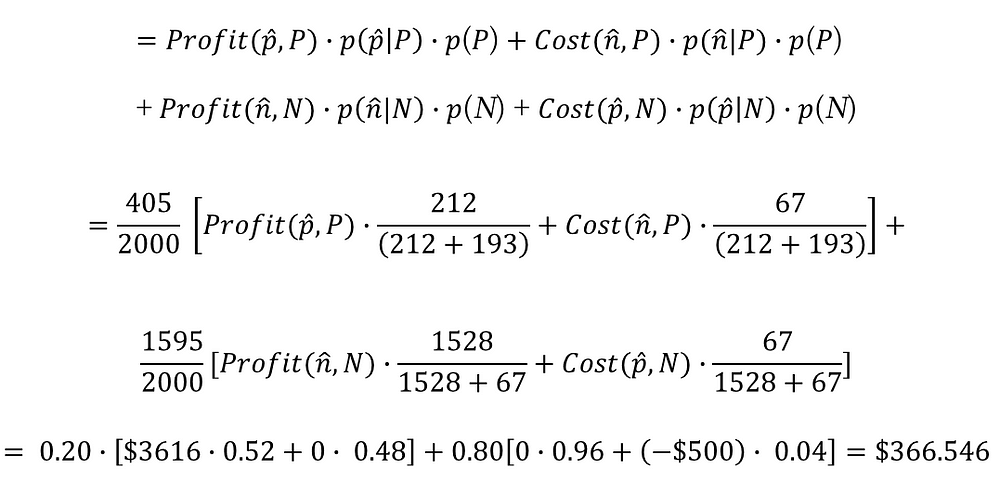
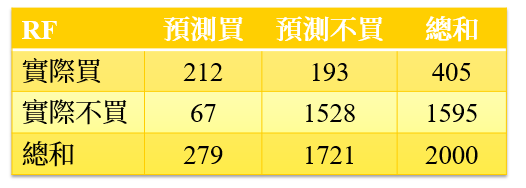
XGBoost期望獲利 = $366.85;代表我們使用XGBoost投放給被模型分類會購買的客戶,我們就能預期獲平均每位客戶$366.85元的獲利
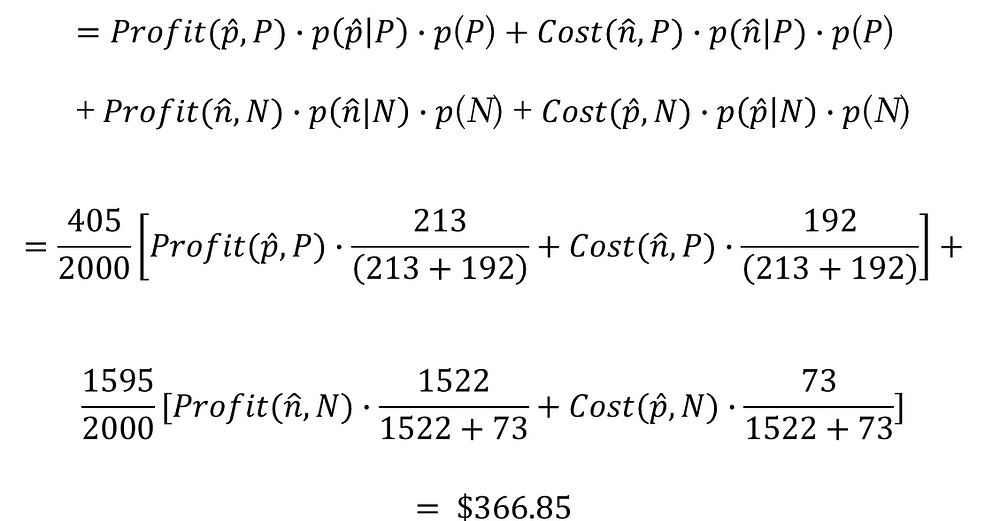
LGBM期望獲利 = $345.448;代表我們使用LGBM投放給被模型分類會購買的客戶,我們就能預期獲平均每位客戶$345.448元的獲利
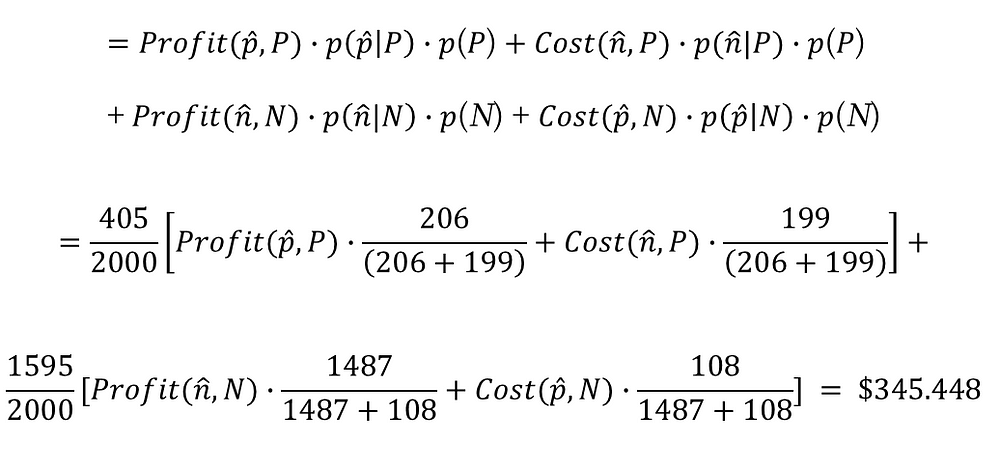
獲利總結表
從獲利總結表中(表1),我們可以驗證內文之前提過的「線上銷售活動」兩件事情:
- 線上活動因為行銷成本相對低廉,尤其是在自家平台進行廣告活動,所以recall越高,對線上活動的獲利確實越好
- 以準確度來說,Random Forest最高,但是以獲利來說,卻是XGBoost的獲利情況較佳,所以證實在商業利益的考量下,準確度不一定是唯一的標準,反倒要依照商業目的的不同(線上或線下活動? 獲利指標?)來挑選最適當的模型
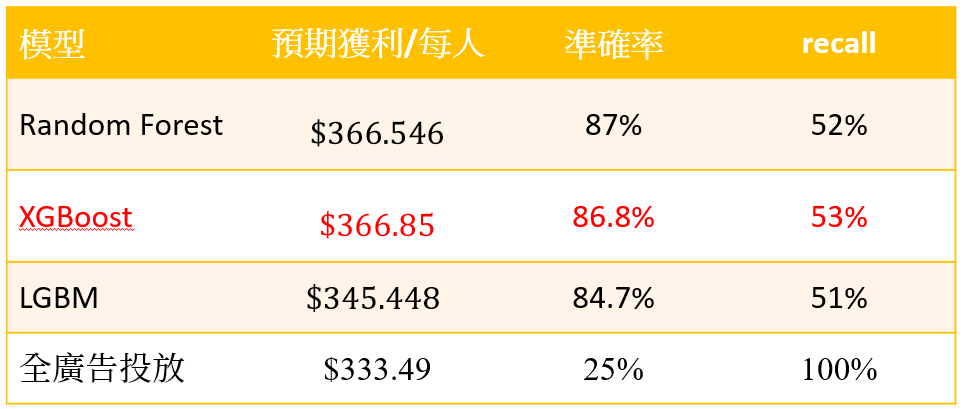
所以針對A公司,行銷資料科學家理應建議第7天要銷售P產品的模型是依憑準確率有一定水準且Recall表現相對好的XGBoost,而非單純以準確率高的Random Forest進行選擇。
另外,相信讀者亦產生另一疑問:「為何我一件產品可以賺約$3,613元,但實際每個人的平均獲利僅這麼少?」原因在於,預期獲利機率模型的計算式中全面考量了「全市場中,會選擇購買的客戶機率與期望值」、「這群購買的客戶中,被模型真正預測到的機率與期望值」以及「預測不會購買,但實際會購買客戶的機率與期望值」。最終在將各自期望值加乘機率後,方得出精準的「不同模型,對於現有全市場的個人預期之獲利」。
所以往後我們聽到老闆或行銷資料科學家們傾訴:「模型獲利看起來很準,但市場驗證下去似乎沒有賺多少? 一定是機器學習模型有問題? 或者資料量不足?」等相關問題時,或許不是機器學習模型本身有問題,反倒可能是計算預期獲利的方法、使用的指標,乃至於挑選利益最大化的模型上這幾個細節評估時,存在著邏輯上的問題。
管理意涵
從模型與預期獲利來看,我們可以得出以下幾個管理意涵:
【在管理上,應抓權? 還是棄權?】
上述案例提及老版因閱讀過2009年哈佛商業評論一篇短文 — 「棄權」領導學,所以大膽放權給員工們進行分析,不過在進行資料分析的同時,我們也應該參考大師們對於經理人與資料共舞的建議,如同湯瑪斯・戴文波特(Thomas H. Davenport)在哈佛商評中2018年的一篇文章 — 經理人應該如何運用數據資料所道:「經理人的職責是為分析師設定適當的參數,並以具說服力的方式,傳達他們發現的結果」,對應到本文來說,本案例的老闆不應該這麼容易「見獵心喜」,反而應該給予資料科學團隊設定適當的參數,也就是「對企業有益的目標 — 預期獲利」,透過最終的預期獲利,資料科學家們便更能以企業家的角度思考,找出真正獲利的模型,為企業創造更大的獲利。
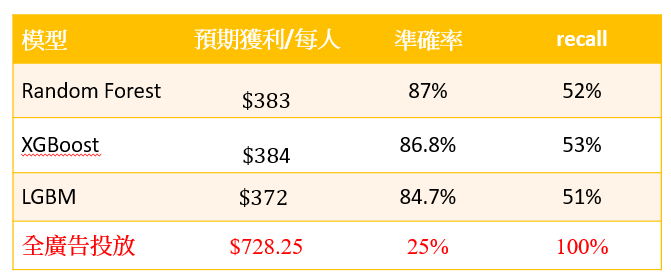
【廣告由模型操盤? 還是全部投放?】
管理者到底是要進行廣告全投放? 還是使用機器學習模型的結果? 一般資料科學團隊都會強調使用機器學習模型的結果就對了,但實際上這樣可能不是獲利最大的方式,我們必須要在投放廣告前,事先以不同模型及全投放的預期獲利進行評估,如果模型結果獲利大於全投放的結果,那我們就可以採行模型的結果,但如果行銷成本很低,舉例來說:在表2,我們的行銷成本僅有$ 5元/每人,其實可以發現進行「全市場廣告投放」相對賺得多;但在表3,我們的行銷成本如有$ 500元/每人,反倒「使用模型」相對賺得多。
這告訴我們如果能將「對每一個客戶的行銷成本」降低至某一程度,經不同模型的演算及全投放的比較,我們將很可能不需要機器模型,即能獲取利益最大化!
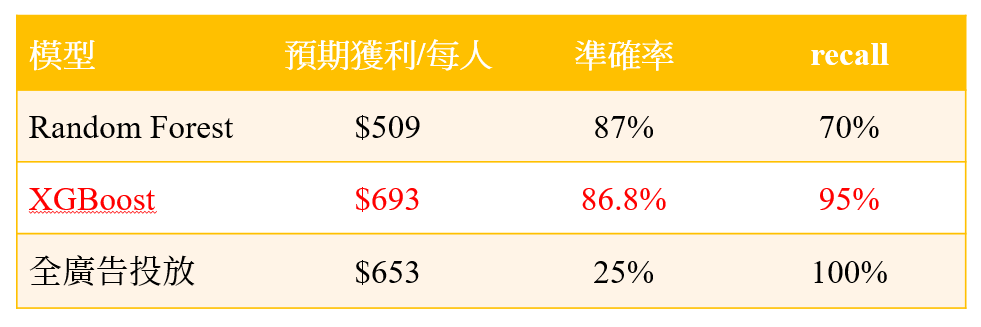
【怎樣挑選線上與線下商業活動的模型指標?】
對於行銷成本相較低廉線上活動來說(假設行銷成本100元/每人),Recall(預測到且真正會購買的客戶/預測到會購買的客戶比例)比例非常重要,如果Recall越高,行銷成本越低,預期獲益反而更高,如同表4,XGBoost的recall如果到達95%,獲益相較Random Forest來說高上非常多。而且就算「全市場廣告投放」狀況下,準確率僅25%, 但recall達100%的狀況下,還是可以發現其預期獲利遠比有87%準確率的Random Forest還要更高,由此可知,當我們行銷成本低廉且recall高的狀況下,我們的獲利將會有更高的成長空間!
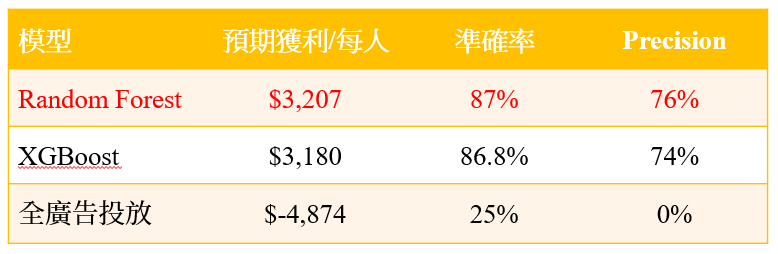
然而對於行銷成本高昂的線下活動來說(假設行銷成本1.5萬/每人),Precision(預測到且真正會購買的客戶/實際會購買的客戶比例)比例非常重要,如果Precision越高,雖行銷成本越高,但如果能更準確打到客戶,預期獲益反而更高,如同表5,Random Forest的Precision如果到達76%,獲益相較XGBoost來說高上許多多,且可見「全廣告投放」的Precision為0%,預期獲益則為負數,由此可知,當我們行銷成本高且單價高的時候,我們應要求模型的Precision要高,我們的獲利才將有更高的成長空間!
還有疑問?
閱讀至此,讀者可能還會有些疑問,舉凡來說:
- 文中有提到如果知曉模型評估出來的欄位特徵,便可讓A公司可以使力在該特徵欄位下更多功夫,創造更多營收,該如何知曉這些欄位特徵?
- 文中提到Sampling的方法,Sampling方法真的能有效提昇「預期獲利」嗎?那應該怎進行Sampling方法?
- 一直很夯的類神經模型對於本案來說,「預期獲利」的表現會更好嗎?
- 該如何繪出文中提到的「獲利曲線」? 獲利曲線對企業又有何種價值?
…
這些疑問我們都會在往後的文章中一一為各位解答。如果各位讀者亦有其他想了解之文章,歡迎於我們FB或本文留言討論喔~!
作者:鍾皓軒(臺灣行銷研究有限公司 創辦人)
