在〈自動篩選惡意言論,找出省錢關鍵! 深度學習篇:找出最適模型〉一文中,我們講解了資料處理與模型設定的方法,在本篇中,我們將從營收的角度比較各個模型的成效,並探討去除惡意言論的更多商業應用。
由 GRU 模型來看 Quora 的商業價值
營收試算 — 情境假設
接著讓我們實際來算算看上述模型能夠藉由去除惡意言論帶來多少的效益吧!為了更清晰的呈現結果,我們將比較使用 GRU 模型去除惡意言論、不去除任何言論、去除所有言論,這三種處理方式所將帶來的效益。首先,我們要先針對使用者人數、效益、和惡意言論辨識正確與否所帶來的影響做一些假設,如圖1所示。
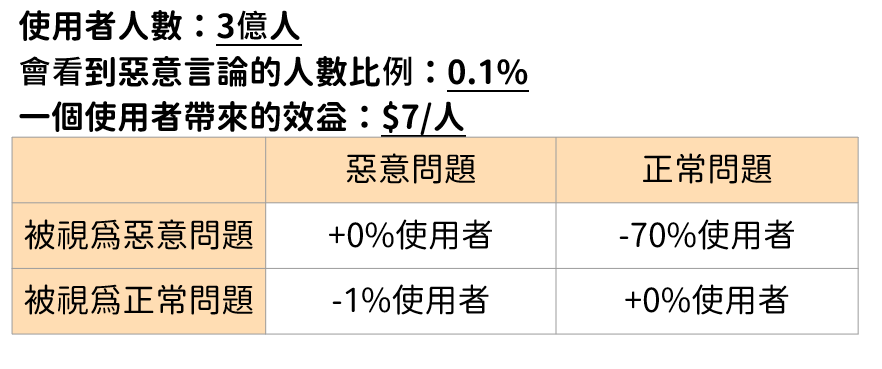
2018 年,完成 D 輪 8500 萬美元融資後,Quora 的估值到達 20 億美元,使用者規模則突破 3 億人,根據此數據,我們假設每位使用者能為 Quora 帶來 7 塊美元的效益。如圖1所示。
針對惡意言論對使用者的影響,我們假設每則惡意言論會被 0.1% 的使用者看到,其中 1% 使用者會因此停止使用 Quora;有 70% 使用者會因為自己的正常言論被當成惡意言論錯刪而感到生氣,因此離開 Quora;至於惡意言論被正確判讀為惡意言論而刪掉、正常言論被判讀為正常言論而留下,則不會對使用者人數帶來任何影響。
營收試算
在我們了解 Quora 在大市場的情境假設之後,我們可以利用以下公式,分別計算「保留全部言論」、「利用 GRU 模型去除言論」、「利用 logistic regression 模型去除言論」對營收結果的影響:
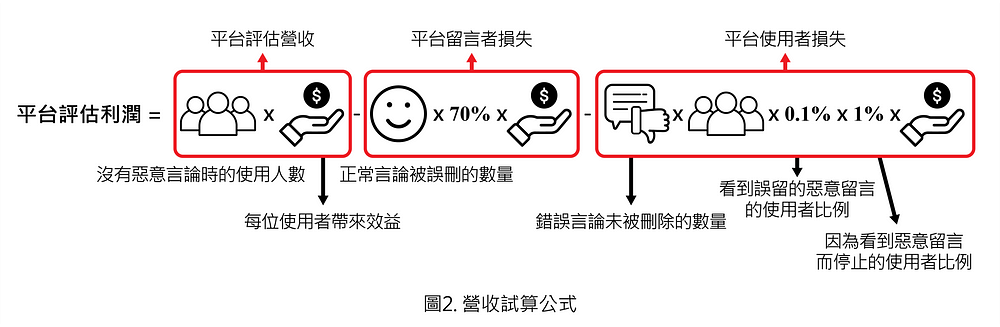
為了將損失更具體的呈現,我們將之拆分為「平台留言者損失」與「平台使用者損失」,兩者的定義如下:
- 平台留言者損失:使用者的正常留言被刪除時,留言者停止使用平台對 Quora 帶來的損失,稱為平台留言者損失。
- 平台使用者損失:平台使用者損失指的是惡意留言被保留在平台上時,其他使用者看到、因此停止使用 Quora 平台所帶來的損失。
舉例而言,有一位使用者在平台上留言「台北七間排隊名店」,誤被判斷為惡意留言刪除,這位使用者氣不過,因此停止使用,這時平台減少的收益就稱為「平台留言者損失」;有另一位使用者在平台上留言「你這個北七!」,卻被判斷為正常留言,沒有被刪掉,這時有 1% 的使用者會看到這則惡意留言,在這 1% 的使用者之中又有 0.1% 的使用者會因為覺得 Quora 沒有做好惡意留言的管制而停止使用 Quora,這些使用者的離開所帶來的損失稱為「平台使用者損失」。
- 保留全部言論
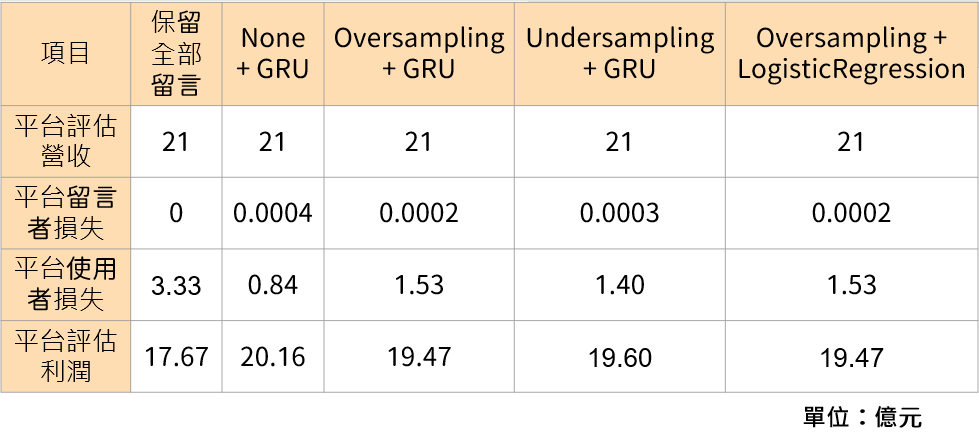
營收 = (3 億 * 7 元/人) — (0 * 70% * 7 元/人) — (15856 * 3 億 * 0.1% * 1% * 7 元/人) = 17.67024 億
平台評估營收:3 億 * 7 元/人 = 21 憶
平台留言者損失:0 * 70% * 7 元/人 = 0
平台使用者損失:15856 * 3 億 * 0.1% * 1% * 7 元/人 = 3.32976 億
平台評估利潤:(3 億 * 7 元/人)-(0 * 70% * 7 元/人)-(15856 * 3 億 * 0.1% * 1% * 7 元/人) = 17.67024 億
- 利用 None + GRU 模型去除惡意言論
營收 = (3 億 * 7 元/人) — (9757 * 70% * 7 元/人) — (3980 * 3 億 * 0.1% * 1% * 7 元/人) = 20.1642 億
平台評估營收:3 億 * 7 元/人 = 21 憶
平台留言者損失:9757 * 70% * 7 元/人 = 47809.3 元
平台使用者損失:3980 * 3 億 * 0.1% * 1% * 7 元/人 = 0.8358 億
平台評估利潤:(3 億 * 7 元/人) -(9757 * 70% * 7 元/人)-(3980 * 3 億 * 0.1% * 1% * 7 元/人) = 20.1642 億
- 利用 Oversampling + GRU 模型去除惡意言論
營收 = (3 億 * 7 元/人) — (5608 * 70% * 7 元/人) — (7295 * 3 億 * 0.1% * 1% * 7 元/人) = 19.46805 億
平台評估營收:3 億 * 7 元/人 = 21 憶
平台留言者損失:5608 * 70% * 7 元/人 = 27479.2 元
平台使用者損失:7295 * 3 億 * 0.1% * 1% * 7 元/人 = 1.53195 億
平台評估利潤:(3 億 * 7 元/人)-(5608 * 70% * 7 元/人)-(7295 * 3 億 * 0.1% * 1% * 7 元/人) = 19.46805 億
- 利用 Undersampling + GRU 模型去除惡意言論
營收 = (3 億 * 7 元/人) — (6486 * 70% * 7 元/人) — (6677 * 3 億 * 0.1% * 1% * 7 元/人) = 19.59783 億
平台評估營收:3 億 * 7 元/人 = 21 憶
平台留言者損失:6486 * 70% * 7 元/人 = 31781.4 元
平台使用者損失:6677 * 3 億 * 0.1% * 1% * 7 元/人 = 1.40217 億
平台評估利潤:(3 億 * 7 元/人) -(6486 * 70% * 7 元/人)-(6677 * 3 億 * 0.1% * 1% * 7 元/人) = 19.59783 億
- 利用 Oversampling + LogisticRegression 模型去除惡意言論
營收 = (3 億 * 7 元/人) — (73594 * 70% * 7 元/人) — (7289 * 3 億 * 0.1% * 1% * 7 元/人) = 19.46931 億
平台評估營收:3 億 * 7 元/人 = 21 憶
平台留言者損失:73594 * 70% * 7 元/人 = 6829.9 元
平台使用者損失:7289 * 3 億 * 0.1% * 1% * 7 元/人 = 1.53069 億
平台評估利潤:(3 億 * 7 元/人)-(73594 * 70% * 7 元/人)-(7289 * 3 億 * 0.1% * 1% * 7 元/人) = 19.46931 億
財務分析結論
以平台總效益衡量,None + GRU 在所有模型之中的預期效益最高,這是由於 None + GRU 所導致的平台留言者損失較低,大幅降低影響其它使用者使用體驗的機會。然而,對於個人而言,正常言論被錯刪的損失(平台留言者損失)比惡意言論被忽視來得大,只是其影響人數較少,所以對效益的影響較小。而模型結果顯示,None + GRU 的錯刪情況最嚴重,若以社群口碑衡量,其實 None + GRU 對社群口碑最為不利,而 oversamplig 以及undersampling 則會帶來普遍良好的評價。總結而言,從資料科學面及財務面的角度來看,None + GRU 的表現仍為所有模型之冠。
管理意涵
綜合以上的模型,我們會推薦 Quora 在本案例之下使用 GRU 模型,因為這樣搭配的模型,能在營收方面達到最好的表現。這並不代表額外做 oversampling 或 undersampling 的處理在任何情況下都會導致較不理想的結果。在不同的案例中,oversampling 或 undersampling 甚至可能達到比 None + GRU 更好的效果,所以在選擇模型的時候,還是建議試試看所有的模型,並搭配當下的商業情境,才能挑到一個最適合的模型唷!
作者:趙熙寧、葉庭妤(台灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究有限公司創辦人)
