「大數據」問世之後,很多企業把大數據當成解決企業問題良方。儘管大數據同樣可依現代科學方法來研究和處理難解問題,但義大利科學家薩羅‧蘇奇(Sauro Succi)博士和倫敦大學學院(UCL)名譽教授彼得‧科維尼(Peter V. Coveney)指出,大數據分析仍存有三大障礙無法突破,因此雖然大數據帶來新視角,但企業卻不能把它當成救世主。

蘇奇與科維尼於2019年2月18日,在期刊Philosophical Transactions A上,發表了一篇名為《大數據:科學方法的終結?(Big data: the end of the scientific method? )》文章。蘇奇與科維尼認為,我們身處的世界非常複雜,因此大數據研究方法所提出的一些主張仍需要修訂。因為源自於伽利略的「現代科學方法」,背後存在著一些障礙,這些障礙包括:非線性(nonlinearity)、非局部性(non-locality)和高維度性(hyperdimensions),如圖1所示。
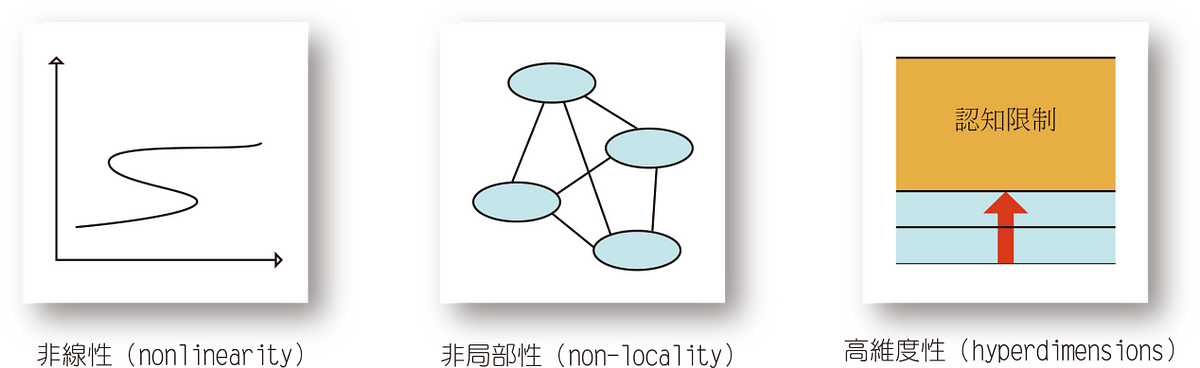
1.非線性(nonlinearity)
非線性是在理論建模時,眾所周知的難題。非線性建模最典型的案例,就是氣象學裡的「蝴蝶效應(Butterfly effect)」。一隻小蝴蝶在中美洲的古巴拍拍翅膀,能在美國德州引發龍捲風嗎?(Does the Flap of a Butterfly’s wings in Brazil Set Off a Tornado in Texas?)
蝴蝶效應是由美國氣象學家,也是麻省理工學院的教授愛德華‧諾頓‧羅倫茲(Edward Norton Lorenz)所提出,意思是指在一個複雜的系統中,一個變數的微小變化,配合背後的連鎖反應,將會對整個系統造成巨大的影響。而這種非線性的影響,大大限制了模型的預測能力。大數據分析可以協助解決一些非線性系統的問題,但許多機器學習演算法的基本假設,並不適合用在非線性系統當中。
2.非局部性(non-locality)
非局部性則是指存在著遠距離的相關性,縱使在系統裡不同的子系統或是變數之間距離很遠,但仍然可能保有因果關係。非局部性通常「違反直覺」,畢竟一般人會認為,越接近的事物,它們彼此之間的相互作用影響也最多。用機器學習來解決非局部性問題顯然是一個重大挑戰。
3.高維度性(hyperdimensions)
我們已經習慣在三維空間上,再加上時間維度來生活。但當維度超過三個以上,人類的認知就會受到相當大的限制(這時一般會透過數學來運算)。複雜系統背後所探討的變數非常多,而這也造成計算維度的複雜。
蘇奇與科維尼最後指出,如果機器學習技術能夠協助克服上述三個基本障礙,那將是非常理想的,但到目前為止,幾乎沒有證據能表明大數據分析研究能有效突破以上的障礙,這需要大家持續的努力(一些例外是在天文學,機器學習在天文領域開始獲得很大的進展)。
作者:羅凱揚(台科大企管系博士)、蘇宇暉(台科大管研所博士候選人)
繪圖者:張琬旖
