現代人的生活型態,幾乎離不開 3C 產品~
而 FB 或是 IG 幾乎是數位時代下每個人日常的一部分。有的人用來記錄每天發生的趣事、和好友們互相分享生活點滴,有的人用來經營個人品牌,有的人用來作為同好的交流社群!
也因為趨勢潮流的帶動,讓社群媒體成為了新的資訊集結及傳遞的重要工具,也成了數據時代下,大家都想探究、挖掘、開發的新天地。
外行看熱鬧,內行看門道。本系列文章,將帶您用數據思維的角度來看 FB 這塊數據寶地背後隱涵消費行為。
此篇我們將從將最簡單也最基礎的部分入門著手。請跟著我從爬取 FB 粉絲專頁每篇貼文的「按讚數」、「留言」及「分享數」開始吧!

前面有文章講解到開啟 chromedriver 及登入 facebook 的方法,今天我們也會建構在這個基礎上,繼續探討 selenium 的神奇奧秘!
若還不了解上述內容的話可以參考以下文章
想知道 chromedriver 的強大請參考:
- 動態網頁爬蟲第一道鎖 — Selenium教學:如何使用Webdriver、send_keys(附Python 程式碼)
- 動態網頁爬蟲第二道鎖 — Selenium教學:如何使用find_element(s)取得網頁元素(附Python 程式碼)
- 想知道如何透過 selenium登入facebook請參考:FB 爬蟲可以更簡單-用Selenium自動登入FB-系列1(附Python程式碼)
Selenium 必備技能 — 網頁檢視器概念說明
要爬取一個網頁的資料,必須從檢視網頁內容開始!相信已經閱讀過其他篇 Selenium 爬蟲系列的文章的朋友們,應該已經對網頁檢視器很熟悉了吧!
如果還不太了解的話,沒關係!我來快速為各位講解一下,只要依循以下的步驟實際操作,就能夠簡單找到想要的網頁資料喔!
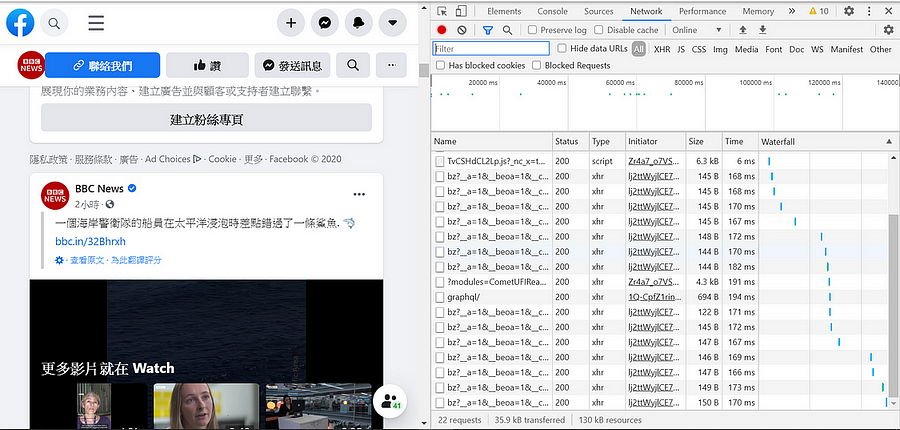
1. 請大家打開網頁檢視器 (Windows 系統:請按 f12、macOS 系統:請按 option+command+c) 可以看到以下視窗 (圖一)
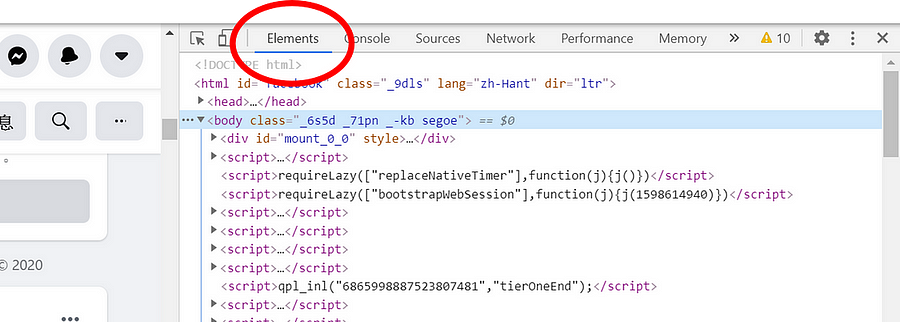
2. 點選視窗上方的 Elements (圖二),檢視網頁元素
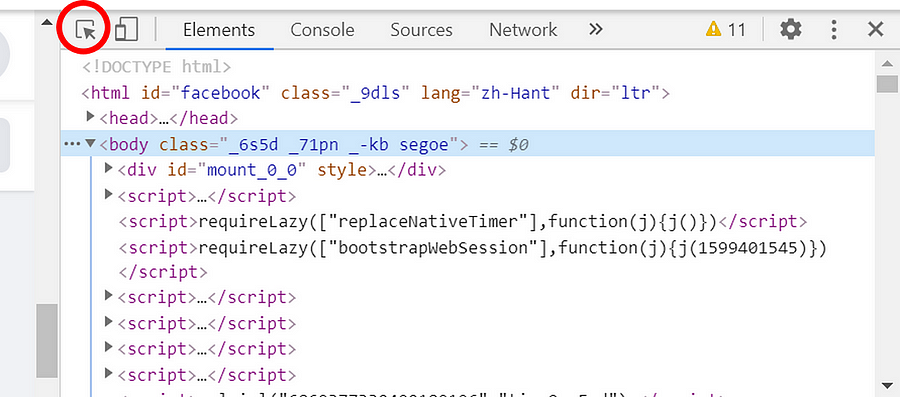
3. 點選 Elements 左邊的箭頭 (圖三)
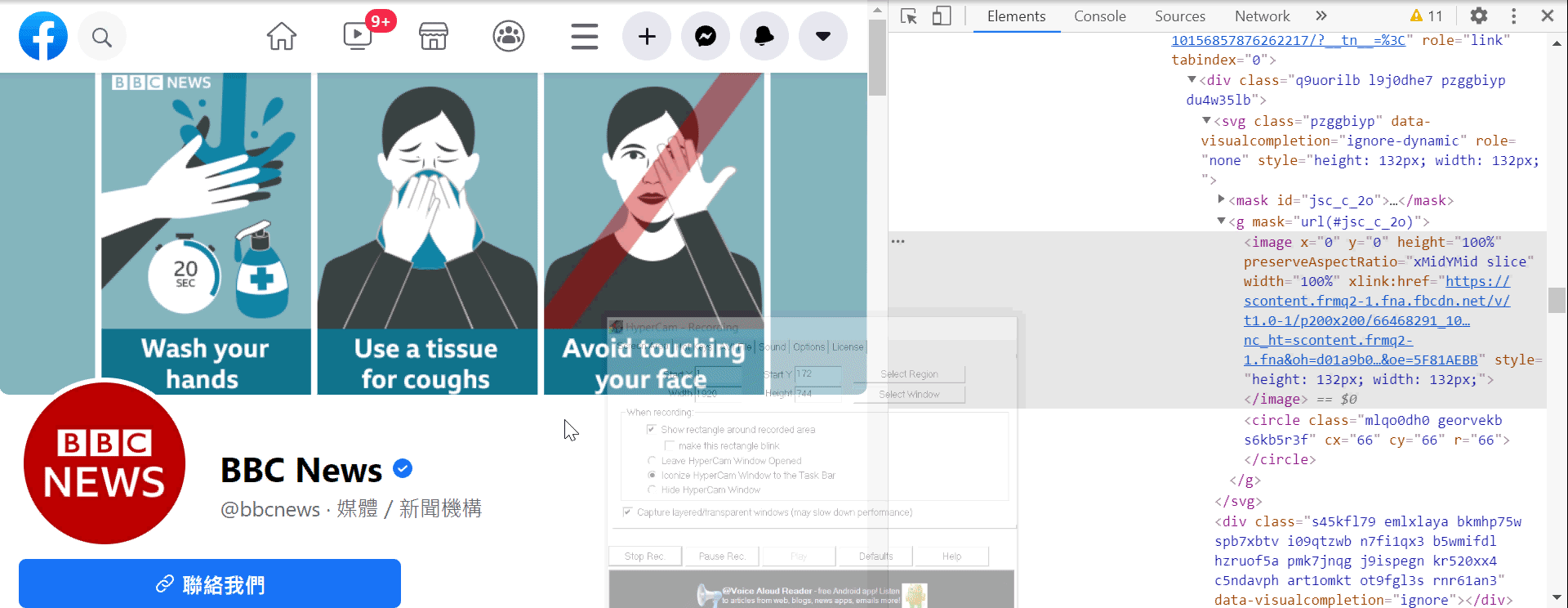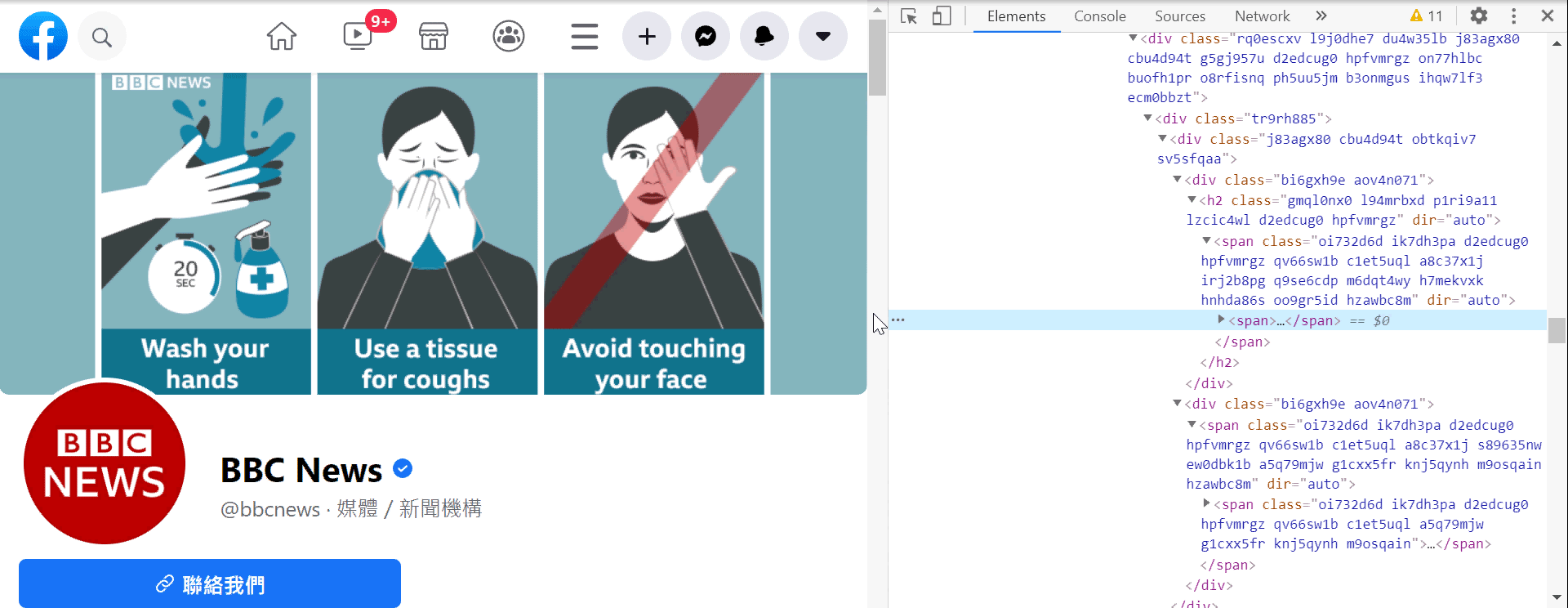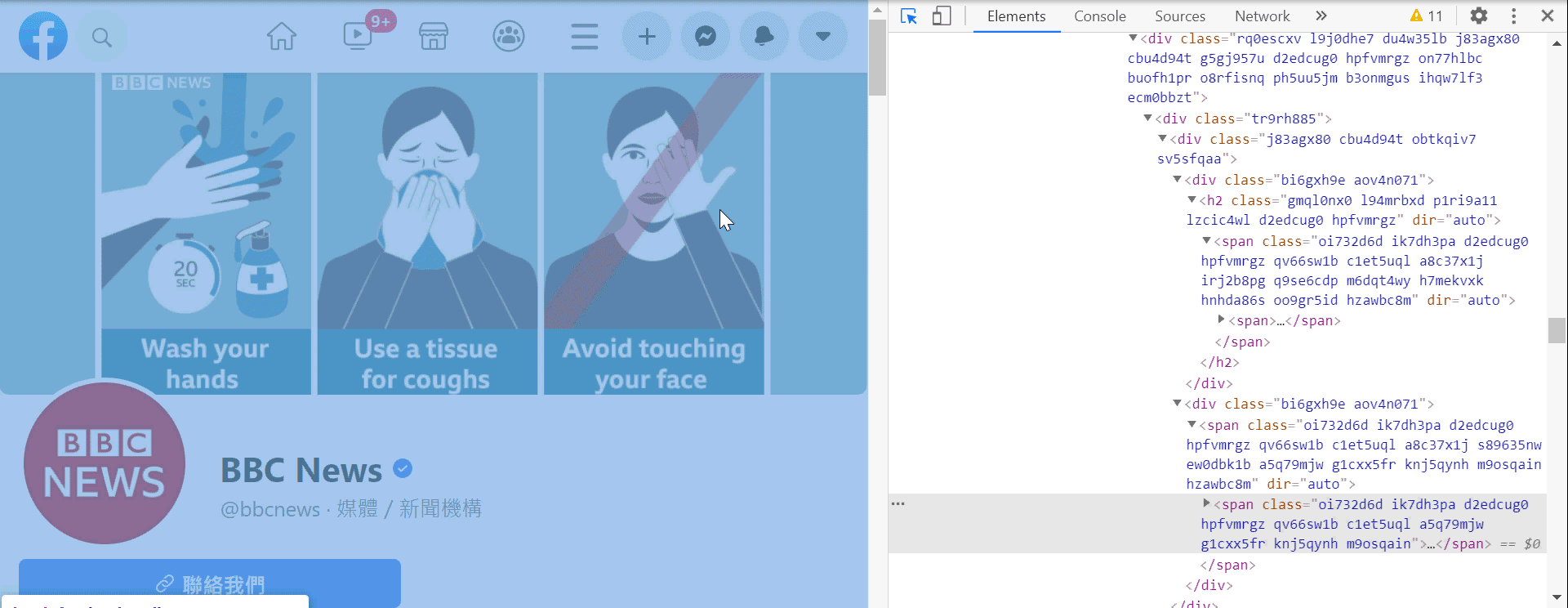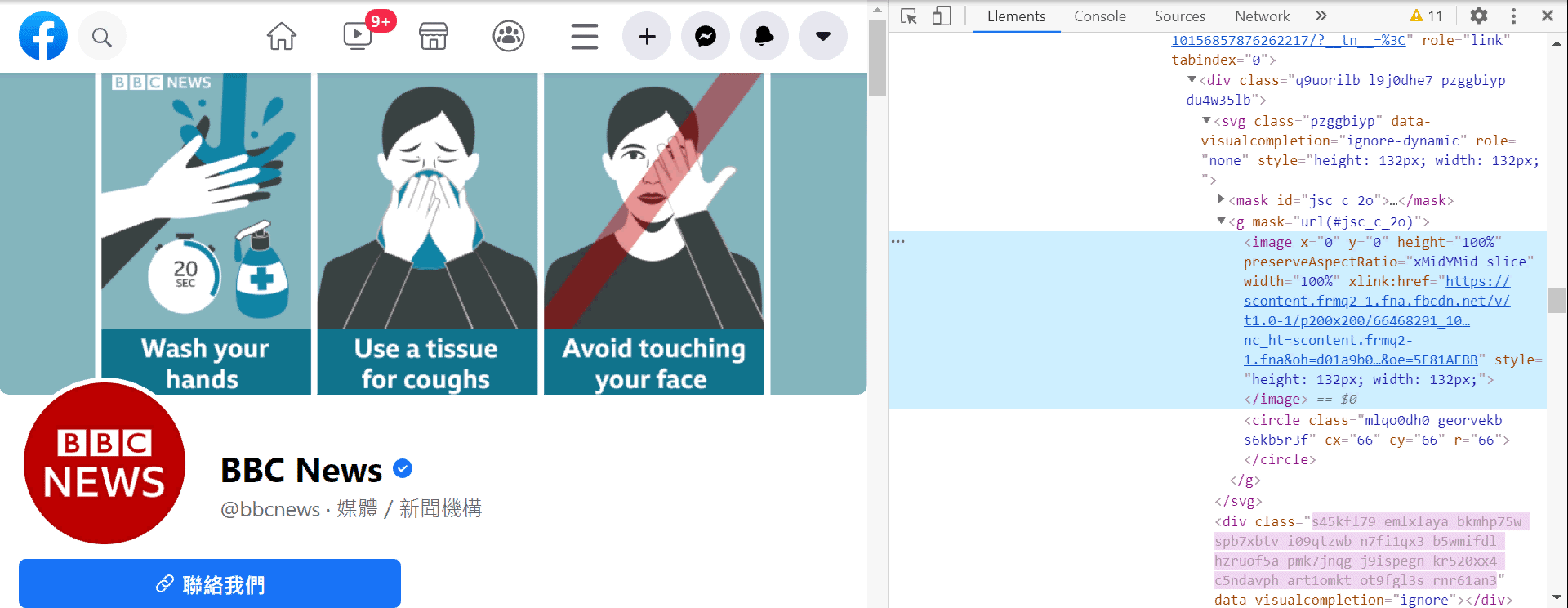
4. 將移動鼠標移動到網頁中任意的區塊做點擊,即可得到鼠標對應區塊的網頁元素!(影一)
抓取文章框架
在抓取貼文按讚數、留言數、分享數前,如果我們能夠一次抓到粉絲專頁內多篇貼文的網頁元素,就能夠使用 for 迴圈把所需的內容一次抓下來,簡單又快速!因此我們將所有貼文先爬取下來。
— — — — — — — — — — — — — — —
*注意事項:
因為 facebook 是一個動態網頁,必須滾動滾輪才會有更多貼文的出現,因此可以先使用 Javascript 中的 window.scrollTo() 讓程式自動幫你下拉滾輪,直到所需的貼文都出現後,就可以停止下拉的動作了!(請參考以下程式碼)
# 建立一個scroll function
# scrolltimes代表頁面滾動的次數
def scroll(scrolltimes):
for i in range(scrolltimes):
# 每一次頁面滾動都是滑到網站最下方
js = ‘window.scrollTo(0, document.body.scrollHeight);’
driver.execute_script(js)
time.sleep(2)
# 呼叫scroll function,就會直接滾動頁面
scroll(5)
程式執行展示影片如下 (影二)
— — — — — — — — — — — — — — —
1. 下拉完滾論後,移動滑鼠箭頭至第一篇貼文 (圖四)
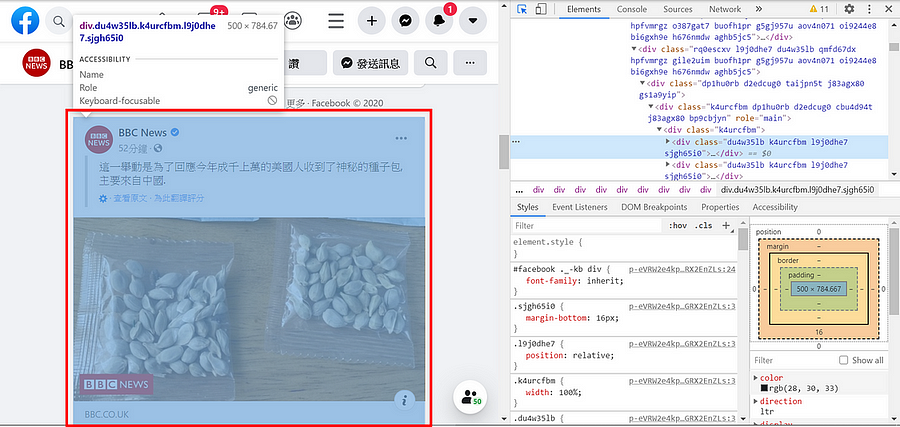
2. 就可以找到第一篇貼文的class name 是 ‘du4w35lb k4urcfbm l9j0dhe7 sjgh65i0’ (圖五)
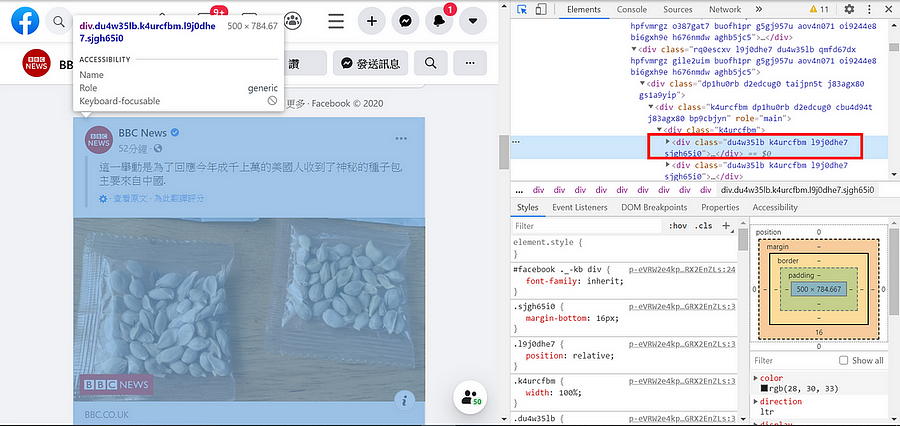
3. 接著就可以發現每一篇貼文的 class name 都是一樣!如下圖中每一個紅色框框都是代表一篇貼文 (圖六)
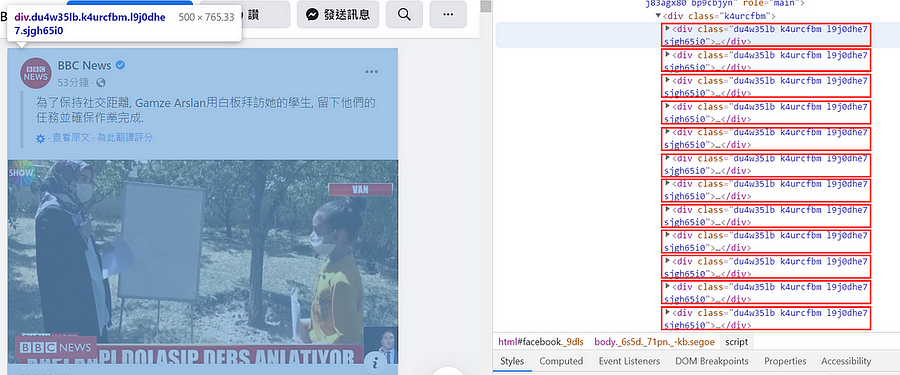
6. 使用 BeautifulSoup 套件,把我們剛剛找到的 class name 放進 find_all() function 裡面,並執行以下程式碼,即可把全部貼文內容都抓取下來囉!
from bs4 import BeautifulSoup as Soup
# class name可能會修改,需要定期偵錯!
soup = Soup(driver.page_source, “lxml”)
frames = soup.find_all(class_=‘du4w35lb k4urcfbm l9j0dhe7 sjgh65i0’)
*BeautifulSoup 補充說明:
find_all() 為抓取所有符合此 class name 的元素內容
find() 為抓取第一個符合此 class name 的元素內容
抓取按讚數
- 首先,我們的目標是把第一篇貼文的按讚數抓取下來,使用網頁檢視器點選第一篇貼文的按讚數,即可找到對應的網頁元素 (圖七)
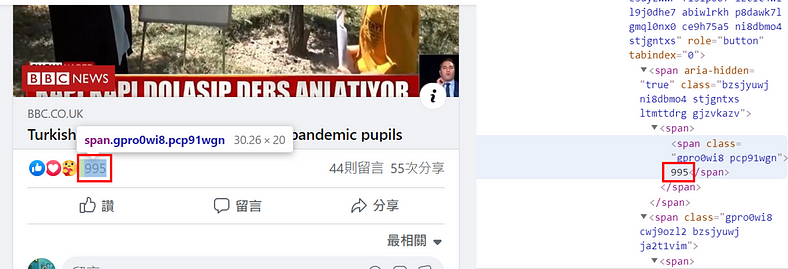
2. 找到按讚數的 class name,但要注意的是,這個 class name 前面還有一個 span 標籤 (圖八)
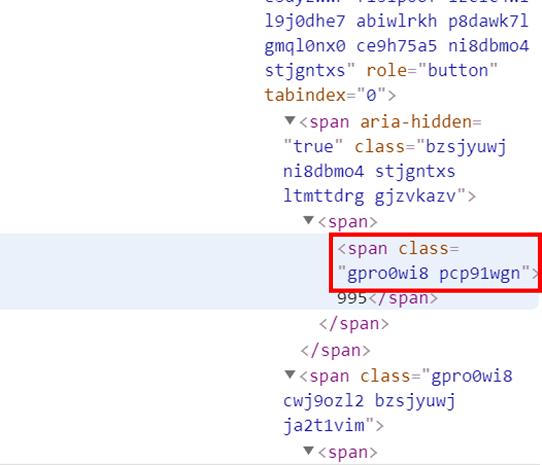
3. 我們一樣使用 BeautifulSoup 套件,把我們剛剛找到的 span 標籤及 class name ‘gpro0wi8 pcp91wgn’ 放進 find() 裡面,請參考以下程式碼 (因為我們現在只要抓取按讚數一個 class name 的內容,所以使用 find() function)
from bs4 import BeautifulSoup
# 前面解釋過的,抓取所有貼文
soup = Soup(driver.page_source, “lxml”)
frames = soup.find_all(class_=‘du4w35lb k4urcfbm l9j0dhe7 sjgh65i0’)
# 抓取第一篇的按讚數
# find()裡面要先放’span’標籤再放class name
# frames[0]為第一篇貼文
# .text為抓取文字內容
# class name可能會修改,需要定期偵錯!
like = frames[0].find(‘span’,class_=“gpro0wi8 pcp91wgn”).text
4. 成功抓取第一篇貼文後,接下來我們使用 for 迴圈,把所有貼文的按讚數儲存在一個 list 裡面,請參考以下程式碼
# 建立一個空的list
like = []
# 抓取每一篇貼文的按讚數
# class name可能會修改,需要定期偵錯!
for ii in frames:
thumb = ii.find(‘span’,class_=“gpro0wi8 pcp91wgn”)
# 有些貼文沒有按讚數,所以抓下來的東西是None,因此直接append 0
if(thumb == None):
like.append(‘0’)
else:
like.append(thumb.text)
5. 但是會發現程式執行完後,抓下來的數值格式不太統一 (圖九)
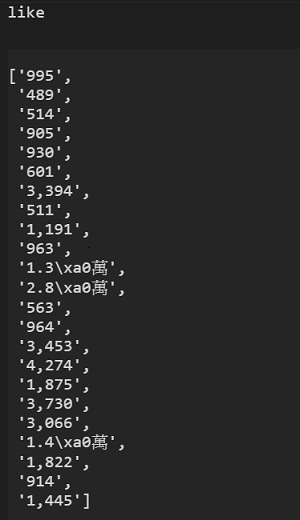
6. 因此我們要進行資料整理,請參考以下程式碼
for i in range(len(like)):
# 處理出現 '\xa0萬' 的數值
if(like[i].find('\xa0萬') != -1):
like[i] = int(float(like[i][:like[i].find('\xa0萬')])*10000)
# 處理有出現 ‘,’ 的數值
else:
like[i] = int(like[i].replace(‘,’,”))
7. 程式執行完後,數值就會變得美觀又整齊了喔!(圖十)
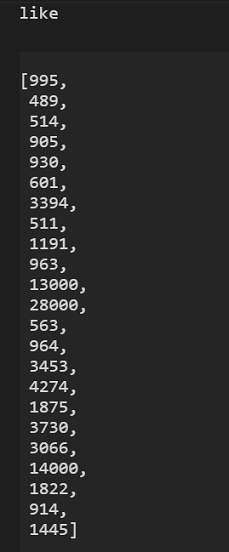
抓取留言數
抓取留言數的方法和按讚數大同小異,以下會再簡單的做介紹!
- 如同按讚數,第一步是使用網頁檢視器找出留言數的網頁元素 (圖十一)
2. 留言數的 class name 就是下面這一大~串,記得還有下面的 span 標籤喔! (圖十二)
3. 一樣使用 BeautifulSoup 套件,把我們剛剛找到的 span 標籤及 class name 放進 find() 裡面,抓取第一篇貼文的留言數,請參考以下程式碼
from bs4 import BeautifulSoup
# 前面解釋過的,抓取所有貼文
soup = Soup(driver.page_source, “lxml”)
frames = soup.find_all(class_=‘du4w35lb k4urcfbm l9j0dhe7 sjgh65i0’)
# 抓取第一篇的留言數
# find()裡面要先放’span’標籤再放class name
# frames[0]為第一篇貼文
# .text為抓取文字內容
# class name可能會修改,需要定期偵錯!
read = frames[0].find(‘span’,class_=“oi732d6d ik7dh3pa d2edcug0 hpfvmrgz qv66sw1b c1et5uql a8c37x1j muag1w35 enqfppq2 jq4qci2q a3bd9o3v knj5qynh m9osqain”).text
4. 成功抓取第一篇貼文後,接下來我們使用for迴圈,把所有貼文的留言數儲存在一個list裡面,請參考以下程式碼
# 建立一個空的list
comment_nums = []
# 抓取每一篇貼文的留言數
# class name可能會修改,需要定期偵錯!
for ii in frames:
read = ii.find(‘span’,class_=“oi732d6d ik7dh3pa d2edcug0 hpfvmrgz qv66sw1b c1et5uql a8c37x1j muag1w35 enqfppq2 jq4qci2q a3bd9o3v knj5qynh m9osqain”)
# 有些貼文沒有留言數,所以抓下來的東西是None,因此直接append 0
if(read == None):
comment_nums.append(‘0則’)
else:
comment_nums.append(read.text)
5. 但也會發現程式執行後,抓下來的數值格式不太統一,因此使用下方的程式碼進行資料整理
# 把'則留言'和','去掉
for i in range(len(comment_nums)):
index = comment_nums[i].find('則')
comment_nums[i] = int(comment_nums[i][:index].replace(',',''))
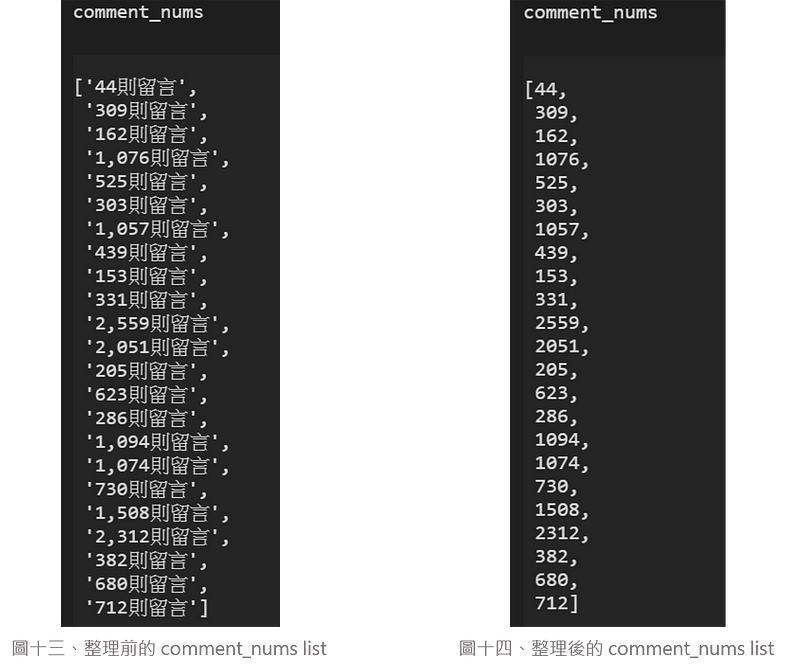
6. 以下分別是整理前(圖十三)及整理後(圖十四)的成果
抓取分享數
抓取分享數的方式與留言數又更相似了,因此我們仿照前面的方法,快速的講解一下抓取的方式,那我們就繼續看下去吧~
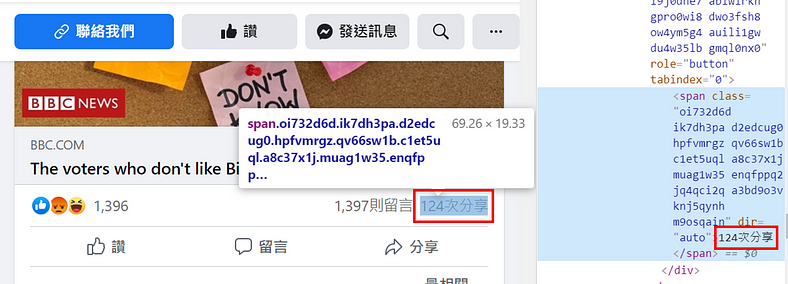
- 萬年不變的第一步,使用網頁檢視器點選分享數找出網頁元素!(圖十五)
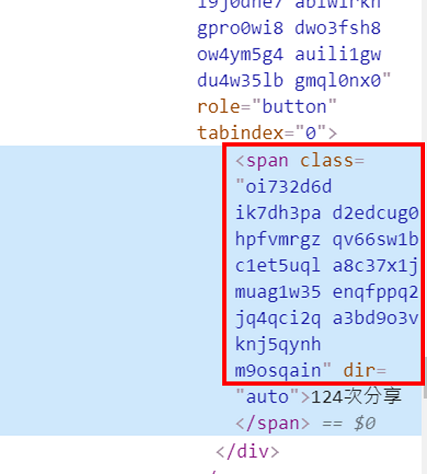
2. 又是萬年不變的第二步,找出分享數的 class name,另外還要注意什麼?沒錯!就是 span 標籤 (圖十六)
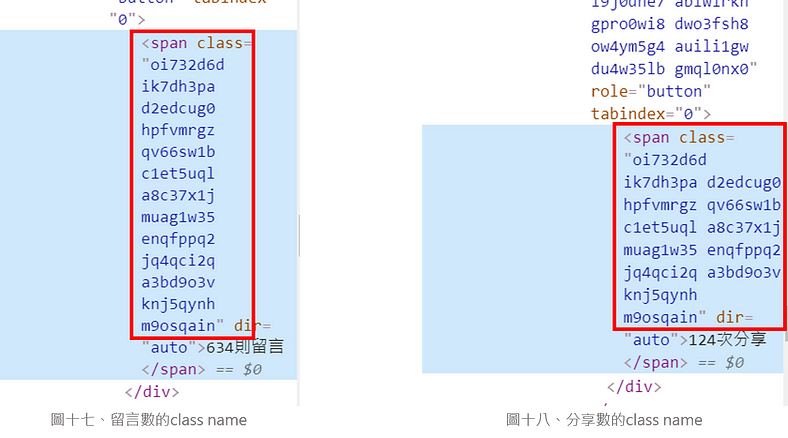
3. 但是如果仔細看看可以發現,留言數和分享數的 class name 好像一樣欸!(圖十七 、圖十八)
4. 因此我們先執行第一篇貼文的 find_all() function,並把此 class name 放進去,看看會得到什麼結果?
喔喔喔!留言數和分享數竟然一起出現了 (圖十九)
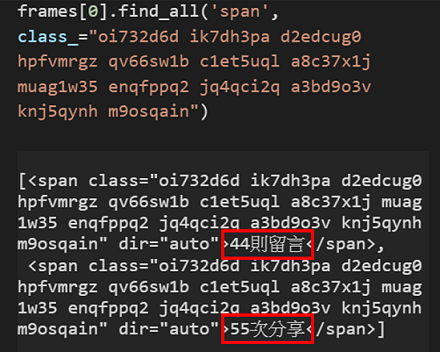
5. 那要怎麼取出分享數呢?因為分享數是第二個出現的,所以只要在整串 find_all() 後面再加上 [1] 就可以抓到分享數了喔,請參考以下程式碼,執行完後即可取出第一篇貼文的分享數了!
from bs4 import BeautifulSoup
# 前面解釋過的,抓取所有貼文
soup = Soup(driver.page_source, “lxml”)
frames = soup.find_all(class_=‘du4w35lb k4urcfbm l9j0dhe7 sjgh65i0’)
# 抓取第一篇的留言數
# find_all()裡面要先放’span’標籤再放class name
# frames[0]為第一篇貼文
# .text為抓取文字內容
# find_all() 後面要再加上 [1] 才能取出分享數
# class name可能會修改,需要定期偵錯!
read = frames[0].find_all(‘span’,class_=“oi732d6d ik7dh3pa d2edcug0 hpfvmrgz qv66sw1b c1et5uql a8c37x1j muag1w35 enqfppq2 jq4qci2q a3bd9o3v knj5qynh m9osqain”)[1]
read = read.text
6. 成功取出第一篇貼文的分享數後,那我們一樣使用 for 迴圈,把所有貼文的分享數儲存在一個 list 裡面,請參考以下程式碼
# 建立一個空的list
share = []
# 抓取每一篇貼文的分享數
# find_all() 後面要加上 [1] 才能取出分享數
# class name可能會修改,需要定期偵錯!
for ii in frames:
read = ii.find_all(‘span’,class_=“oi732d6d ik7dh3pa d2edcug0 hpfvmrgz qv66sw1b c1et5uql a8c37x1j muag1w35 enqfppq2 jq4qci2q a3bd9o3v knj5qynh m9osqain”)[1]
# 有些貼文沒有分享數,所以抓下來的東西是None,因此直接append 0
if(read == None):
share.append(‘0次’)
else:
share.append(read.text)
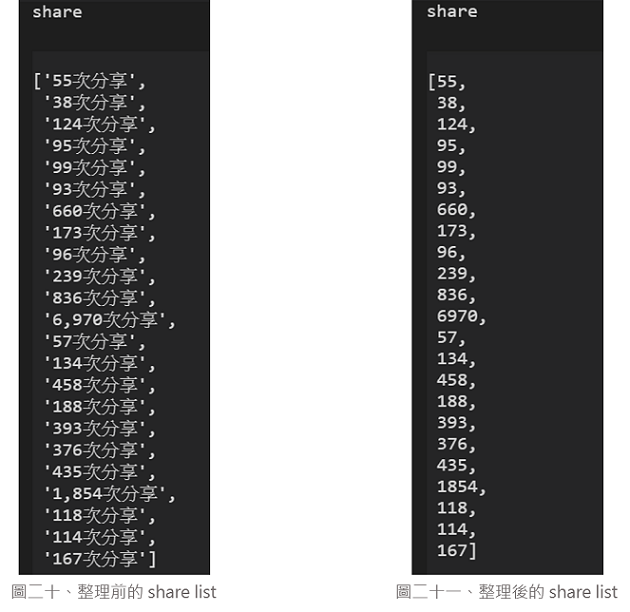
7. 並使用以下的程式碼進行資料整理!
# 把'則留言'和','去掉
for i in range(len(share)):
index = share[i].find('次')
share[i] = int(share[i][:index].replace(',',''))
8. 程式執行完後那我們就來看整理前 (圖二十)及整理後 (圖二十一) 的成果吧
以上就是 FB 貼文按讚數、留言數及分享數爬蟲的全部介紹!但是要注意!因為每個網頁都會定期維護,所以 class name 要定期偵錯喔!
學會了這幾招,就可以從自己的 FB 開始,試著爬取按讚數、留言數、分享數,或者也可以分析您自身經營的社群。可以初步比較那些種類的貼文其粉絲互動性指標是較高的,指標間的有無明顯的差異變化,再延伸應用至貼文類型發放選擇、貼文效益評估管理等。
本文完整程式碼在此
謝謝大家看完這篇陋陋ㄉㄥˊ的文章,希望能讓大家體會到爬蟲的神奇奧秘!
那我們就下次見啦,掰掰~
作者:許喬雅 (臺灣行銷研究特邀作者)、鍾皓軒 (臺灣行銷研究有限公司創辦人)
