Chapter 03 行銷資料科學技術概念
這一章我們要從資料蒐集、資料分析、資料呈現三種角度,來說明行銷資料科學技術的概念。其中,資料蒐集主要談網路探勘;資料分析主要談資料庫知識探索(KDD)、機器學習、監督式學習與非監督式學習、常見的機器學習演算法、決策樹、隨機森林、Apriori演算法、類神經網路、支持向量機、資料探勘與文字探勘之比較;資料呈現則討論資料視覺化與視覺化分析學及圖表價值的判斷標準。
一、資料蒐集
有關資料蒐集的技術,主要以網路探勘(Web Mining)為主。根據統計,目前全世界連結上網的網站,已高達十七億個,而可以算是各種知識來源之一的全球資訊網(WWW),一直是很多人想要開採的寶礦。因為全球各地的網路使用者,都會按照其所關切的主題,不斷產生各式各樣的內容。因此,如何從這麼豐富的資源中挖出有用的資訊,就得依賴網路探勘(Web Mining)技術。
[2] Etzioni, The world wide web: Quagmire or goldmine, Communications of the ACM, 39(i1), pp. 65-68,1996.
[2] Web mining is the application of data mining techniques to discover and retrieve useful information and patterns from the world wide web documents and services.
網路探勘的類別包括三種:網路內容探勘(web content mining)、網路結構探勘(web structure mining)、網路使用探勘(web usage mining),如圖1所示。

資料來源:Jaideep Srivastava, Prasanna Desikan, Vipin Kumar
繪圖者:余得如
(一)網路內容探勘(web content mining)
網路內容探勘是對網頁中的文字(text)、聲音(audio)、影像(video)、圖片(images)、結構紀錄(structured record)等內容,進行資料探勘。
網路內容是三種探勘中最有彈性、最複雜、卻也擁有最豐富的資源,因此除了文字文件(textual document)之外,更包含了各式各樣多媒體內容。像是從個人網頁中,可以得知他的興趣、嗜好、學經歷等,並透過網頁內容加以分析。而企業如果想知道其他競爭對手的現況,也可以分析公司網頁的內容,進一步了解它的主要產品、屬性、市場區隔、甚至評估市場佔有率等。
(二)網路結構探勘(web structure mining)
網路結構探勘的目的,在架構出網站中的超鏈結模式,並透過圖形方式來呈現網站的內部結構,進而檢視網站的設計。大部分的網路結構探勘,在於讓網站運作更有效率。
以上的網路內容探勘以及網路結構探勘,一般可透過網路爬文技術,利用R或Python等語言來開發爬蟲工具並進行抓取。
(三)網路使用探勘(web usage mining)
網路使用探勘則是企圖發現使用者的瀏覽特徵。透過分析使用者瀏覽網站時所留下的記錄(通常是log記錄檔),進而了解使用者的瀏覽模式。比方說,一家公司老闆希望了解員工在上班時間,都在上些什麼網站,是認真辦公,還是上網購物、看股票、看成人網站等偷偷摸摸從事與公務無關的行為,都能經由公司內部網路使用探勘分析得知詳情。
網路使用探勘資料收集的方式,通常是在網頁裡埋下由JavaScript所撰寫出的追蹤程式碼(如Google Analytics)。另一種則是透過Web Service所產生的Access Log 來進行分析,但通常要自行撰寫Log的規則才會比較精確。
二、資料分析
資料分析首先探討資料庫知識探索(簡稱KDD),再就機器學習、監督式學習與非監督式學習、常見的機器學習演算法(如決策樹、先驗(Apriori)演算法等),以及資料探勘與文字探勘進行說明。
(一)資料庫知識探索
「資料庫知識探索(Knowledge Discovery in Database,簡稱KDD)」顧名思義,是從資料庫中,探索出有用知識的程序。隨著大數據的出現,KDD的概念廣泛應用於科學、行銷、投資、製造,甚至是詐欺犯罪調查等不同的領域。透過KDD的探索,我們可以從大量的原始數據中,找到有用的資訊。
根據學者法雅德(Fayyad)等人的觀點[1],KDD與資料採礦(或稱資料探勘(Data Mining)有所不同。KDD是指整個從數據中發現有用知識的程序。而資料探勘只是KDD程序中的一個特定步驟,如圖2所示。
[1] Fayyad, Usama, Gregory Piatetsky-Shapiro, and Padhraic Smyth (1996), “ From Data Mining to Knowledge Discovery in Databases, “ AI Magazine, Volume 17, Number 3. pp. 37-54.

圖2 資料庫知識探索(KDD)程序
繪圖者:廖庭儀、趙雪君
法雅德(Fayyad)等人以另兩名學者布拉赫曼(Brachman)和阿南德(Anand)(1996)[1]的概念為基礎,發展出KDD程序的基本步驟:
[1] Brachman, Ronald J. and Tej Anand (1996), “The process of knowledge discovery in databases,” Advances in knowledge discovery and data mining, American Association for Artificial Intelligence Menlo Park, CA, USA ©1996, pp. 37-57.
步驟1—訂定目標(identifying the goal)
從消費者觀點(the customer’s viewpoint),確認此次資料探索的目標。蒐集資料的範圍涵括各種相關的實務應用領域(application domain),以及所該具備的技術知識。
步驟2—建立目標資料集(creating a target data set)
選擇一個我們有興趣或想更深入探索的資料集來執行運算分析。
步驟3—資料清理與前置處理(data cleaning and preprocessing)
對所選定的資料集做資料清理(data cleaning)與前置處理(data preprocessing)。 刪除資料中的雜訊(noise),例如離群值(outliers)、重複紀錄、不正確的屬性值等,同時對資料不足的欄位進行填補(填補方法通常會以平均值或高度類似的範例值進行替代)。資料越完整,對下一步的分析越有利。
步驟4—資料轉換(data transformation)
資料轉換主要在進行資料減縮與投影(data reduction and projection),在操作上,使用降維(dimensionality reduction)技術,來減少所考慮變數的有效數量。
(以下步驟5-7,皆為資料採礦(data mining)的程序。)
步驟5—選擇資料探勘方法(Choosing the data mining method)
例如:分類(classification)、分群(clustering)、關聯(Association)等分析方法。
步驟6—選擇資料探勘演算法(Choosing the data mining algorithms)
選擇一個或多個適當的資料探勘的演算法,例如:決策樹(Decision Tree)、單純貝氏(Naïve Bayes)、邏輯迴歸(Logistic Regression)、隨機森林(Random Forest)、支持向量機(SVM)、神經網路(Neural Network)、K平均(K-means)或Apriori。在這些過程中,必須要決定哪些模型與參數的選用是適當的,同時也要確認選定的資料探勘方法與KDD整個過程的衡量指標是否一致(例如:相較於模型的預測能力,最終使用者可能對模型的建立更感興趣)。
步驟7—資料探勘(data mining)
選定資料模式(patterns)呈現的形式,如:決策樹圖、迴歸分析圖、聚類分析圖等。讓最終使用者了解根據前面各程序步驟所獲得的資料探勘結果。
步驟8—解釋探勘模式(interpreting mined patterns)
對最終選定的資料探勘模式進行解釋。過程中,可能需要返回步驟一至七中的任何一個步驟,並且重複執行。
步驟9—鞏固發現的知識(acting on the discovered knowledge)
運用KDD最終發現的知識結果並採取行動。同時,也要檢視該知識結果與過去的觀點是否一致。
最後,KDD程序強調步驟之間的交互影響,並且不斷地反覆運行其中的步驟。
(二)機器學習(Machine Learning)
過去,機器是透過人類撰寫程式來進行執行,「一個指令、一個動作」就是描述這種情境。但這句話,其實也隱含機器不會舉一反三,只能被動且制式地聽從人類命令的貶抑之意。但是現在機器學習(Machine Learning)的出現,可是將這種概念徹底打破。機器學習是給予電腦(或機器)眾多的範例,透過建立訓練模型,讓機器能自行判斷進而學習,而非由人類下指令。
機器學習是從人工智慧(AI)演變而來,屬於AI的一個分支。從人工智慧的研究歷史來看,AI以「推理」為出發,到以「知識」為核心,再到以「學習」為重點,形成一條脈絡。而機器學習則是實現人工智慧的一條重要途徑,最終則希望以機器學習為手段,解決人工智慧中的問題。
維基百科指出,近三十多年來,機器學習已發展成為一門多領域的學科,但其中牽涉機率理論、統計學、逼近論、凸分析、計算複雜性理論等。機器學習理論主要是設計和分析一些讓電腦可以自動「學習」的演算法,並從資料中自動分析獲得規律、再利用規律對未知資料進行預測。
以「人類學習辨識貓」這件事來說,如圖3所示。媽媽指著貓的照片對小小孩說:「這是貓咪」。下次當一隻貓跑到孩子旁邊時,媽媽又指著貓說:「這是貓咪」。幾次之後,孩子看到感覺像貓的照片或動物時,就自然地說出:「這是貓咪」。回顧一下小朋友的歸納經驗的過程,就是人類學習的方式。

圖3 人類學習與機器學習
繪圖者:余得如
現在「機器學習辨識貓咪」也以上述類似人類學習的方式。首先,先將大量貓的照片給予電腦,由機器透過訓練模型的建立,最終能辨識出貓的照片。2012年,Google就從YouTube影像中,隨機擷取了1,000萬張貓的影像照片,並透過機器學習,讓電腦終於能對貓咪進行辨識。
(三)監督式學習與非監督式學習
我們先前提過「機器學習」是人工智慧的一環,而機器學習能透過資料與「經驗」自動改進電腦程式的效能。一般來說,最基礎的機器學習(Machine learning)分成兩種類型[1]:監督式學習(Supervised learning)與非監督式學習(Unsupervised learning)。以下,我們先簡單比較監督式學習與非監督式學習之差異。
每份資料背後都有模型(Model)。圖4為一系統模型圖,包括:輸入(Input)、模型(Model)、與輸出(Output)。

圖4 系統模型圖
繪圖者:張庭瑄
監督式學習(Supervised learning)包含了輸入(u)與輸出(y),而非監督式學習(Unsupervised learning)則只有輸入(u)。但這樣的說明,無法讓人清楚了解兩者的不同。回到上述機器辨識貓的案例。
所謂「監督式學習」,大致的作法是,先讓機器(電腦)看有「標記(俗稱標籤)」的資料。比方說,先看有標記狗和貓的照片各一萬張,然後再詢問電腦,新照片裡的動物,究竟是狗還是貓。這樣訓練機器的過程,很像是老師提供多種範本給學生,或是先告訴學生答案(哪種動物是狗還是貓),因此被稱為「監督式學習」。
至於「非監督式學習」,則是在機器訓練的過程中,不給標準答案(亦即不需要事先輸入標籤註明是狗還是貓),訓練時僅須對機器輸入範例,它會自動從範例中找出背後的規則。因此,機器在學習時,並不知道其分群結果是否正確。
接著,我們再以監督式學習與非監督式學習裡,常見的資料探勘工具:分類(Classification)與分群(Clustering),並以銀行為例來說明。
1.「分類」(Classification):
銀行將現有的持卡人資料(亦即「輸入(u)」),轉換成每個人的「信用評等」,對現有持卡人進行區分,並建立「分類模型」,決定是否發卡(亦即「輸出(y)」)。如圖5所示。圖中的分類方式是透過「決策樹」(Decision Tree)來完成。從圖中我們可以發現,不同階層的決策準則代表著不同屬性(例如︰年齡、所得、婚姻狀況…等),透過這些不同的屬性,我們可以將持卡人分成不同的類別(例如︰存款是否超過20萬、是否擁有信用卡)。最下面的內容即是銀行對於不同類別持卡人的發卡與否。當銀行建立了有效的預測模型之後,就可以依此做為未來是否發卡之依據。例如︰哪一類人,銀行該「發卡」給他、哪一類人,銀行又「不該發卡」。
所謂「監督式學習」,大致的作法是,先讓機器(電腦)看有「標記(俗稱標籤)」的資料。比方說,先看有標記狗和貓的照片各一萬張,然後再詢問電腦,新照片裡的動物,究竟是狗還是貓。這樣訓練機器的過程,很像是老師提供多種範本給學生,或是先告訴學生答案(哪種動物是狗還是貓),因此被稱為「監督式學習」。
至於「非監督式學習」,則是在機器訓練的過程中,不給標準答案(亦即不需要事先輸入標籤註明是狗還是貓),訓練時僅須對機器輸入範例,它會自動從範例中找出背後的規則。因此,機器在學習時,並不知道其分群結果是否正確。
接著,我們再以監督式學習與非監督式學習裡,常見的資料探勘工具:分類(Classification)與分群(Clustering),並以銀行為例來說明。
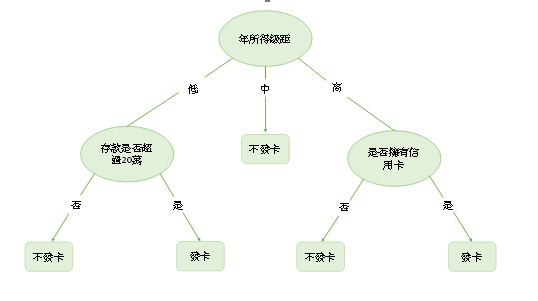
圖5 決策樹
2.「分群」(Clustering):
銀行將現有的持卡人資料(亦即「輸入(u)」),根據持卡人的屬性,對現有持卡人進行區分,建立「分群模型」,不同階層的分群準則,代表著不同屬性(例如︰年齡、所得、婚姻狀況、刷卡頻次、刷卡金額…等),透過這些不同的屬性,我們可以將持卡人分成不同的群別(例如︰停滯型、穩定型、成長型、貢獻型、超級VIP型)。
當銀行建立了分群模型之後,就可以對不同的群體,發展不同的市場區隔策略。例如︰對超級VIP型的卡友進行尊榮行銷活動。
從機器學習方式的角度來看,「分類」(Classification) 屬於「監督式學習」(Supervised learning)(透過目標變數訓練模型)。而「分群」(Clustering) 則屬於「非監督式學習」(Unsupervised Learning) (沒有要預測的對象)。就上述銀行的例子來說,「分類」透過「發卡與否」(亦即「輸出(y)」)來進行「分類模型」的發展,而「分群」只是單純的對持卡人進行區分。如表1所示。

繪圖者:廖庭儀
最後,常見的監督式學習資料探勘工具,除了分類(Classification)外,還包括了預測。而非監督式學習資料探勘工具,除了分群(Clustering)外,還包括了關聯規則(Rule of Association)。
(四)常見的機器學習演算法
常見的機器學習演算法,以「監督式學習(Supervised Learning)」與「非監督式學習(Unsupervised Learning)」兩大類進行分類,內容如圖6所示。

圖6 機器學習演算法
繪圖者:張庭瑄
在監督式學習(Supervised Learning)裡,通常要達成兩種目的:預測(Pedicting)與分類(Classification)。在預測方面,像是預測消費者購買行為,一般會透過線性迴歸(Linear Regression)、決策樹(Decision Tree)、隨機森林(Random Forest)、類神經網路(Neural Network)和梯度提升決策樹(Gradient Booting Tree)等演算法來進行。
在分類方面,則是對消費者加以歸類,一般會利用決策樹(Decision Tree)、單純貝氏(Naïve Bayes)、羅吉斯迴歸(Logistic Regression)、隨機森林(Random Forest)、支持向量機(SVM)、神經網路(Neural Network)和梯度提升決策樹(Gradient Booting Tree)等。
至於在「非監督式學習(Unsupervised Learning)」的部分,常見的功能可分成:分群(Clustering)、關聯(Association)與降維(Dimension Reduction)。實務上,在進行分群時,如:進行市場區隔,一般常用的演算法為K-平均(K-means)。在發展推薦系統時,則會用到Apriori演算法。至於在降維,則常用主成分分析(Principal component analysis,PCA)。
由於演算法的類型頗多,以下簡單就決策樹與Apriori演算法、支持向量機、人工神經網路等進行介紹。
(五)決策樹
人們在做決策時,通常會有許多的選擇方案。比方說,今天要從台北到台中,可以搭高鐵或台鐵,或者搭乘和欣客運或自己開車,由於每一種決策都有成本(時間、金錢)、風險(塞車或安全度)和成功的期望值,把這些可能的決策選擇都畫出來,它就會像是一棵倒立的樹狀系統,在資料科學中,這類的演算法就叫做決策樹。
以下我們以一家虛擬銀行核發信用卡的過程為例,來說明決策樹理論。
陳小姐剛從大學畢業,工作了幾個月,想要申請信用卡,她同時也提供了個人所得與資產等資料給銀行,而A銀行的信用卡部門,收到陳小姐的申請後,要從哪些資料來判斷是否應該發卡給她呢?
首先,銀行得先將陳小姐的資料,做變數轉換,如表2所示。

<<本頁僅供試讀,若須閱讀完整章節歡迎參考行銷資料科學>>

行銷資料科學|大數據x市場分析x人工智慧
出版社:碁峰
出版日期:2019/07/30
語言:繁體中文
定價:520元
