案例剖析
當零售業的「採購」遇到機器學習行銷資料科學實戰案例時?!
「零售採購(Retail Procurement)」是零售業為了要實現銷售目標,而去探尋或預測市場產品/服務需求後,以最適合的時間與最低的成本,獲得零售業所要銷售的產品/服務數量。掌握採購數量與銷售數量這項任務對零售業可說是變動最大,且最需要經驗老到的人 — 採購者(Buyer)來執行,他們也正是企業中不可或缺的重要成員。
零售採購為何困難?
如果經營的是服飾與配件零售業,面對東大門零售採購通路上萬件的商品,一開始絕對會眼花撩亂,不知該採購何種商品,當然,但在採購執行上,絕對不是賣多少買多少,我們則應該按照每個禮拜或者固定期間的銷售來預估接下來的3–6個月的銷售走勢,推測採購數量。
當一家零售店僅有十幾樣商品須採購時,對經驗老道的採購者幾乎不成問題。不過讓我們換個場景,如果我們面對的是數百家零售分店、數十萬種商品或者數十個虛擬通路、數萬種商品,這時候企業主不是聘請1–2個採購者就可以解決採購問題,而是會開始面對「極高的風險」及「海量的成本」,以下臚列3項人工採購常見的問題:
1. 聘請採購者的成本
面對萬樣商品,採購團隊通常會聘請超過百人或千人團隊進行採購分析,以人為經驗不斷的臆測下期銷售量來推估採購數量。如此團隊便造成人事成本大增,如果人為採購所造成的庫存成本激增,很有可能將企業當期利潤全數併吞,甚至虧損。
2. 風險控制
雖然採購成員多達百人至千人,但一旦採購數量預估錯誤,造成企業虧損或倒閉的風險其實非常高,但似乎企業又僅能仰賴人工採購,所以面對龐大的人事、購貨及存貨的風險,零售業業主每天做生意可謂是鐵索橫江,心驚肉跳。
3. 促銷及活動考量
在促銷活動上(在此不探討如何搭配商品促銷達利潤極大化),採購者又應該如何精準針對萬樣商品評估採購數量?如果A商品配上B商品進行促銷,採購者通常預期兩樣商品銷售數量會達一致性而採購同數量,但現實往往不是如此,時常會發生A商品銷售數量高於B商品,而採購B商品造成庫存反而消耗掉促銷所帶來的利潤。
採購上種種變數,在人工未能完善的處理下,都可能是致使企業由盈轉虧的可能性。
有解決方案與案例?
好在近年的機器學習面對多維度的資料已能迎刃而解,更遑論面對龐雜的採購資料與決策,皆可建議相關方案。
舉例來說,美國大型電商 — 亞馬遜(Amazon)在零售業務上的收入佔了整體業務超過5成的營收,但在2018年,亞馬遜讓採購團隊不再進行人工的需求預測、制定採購策略等採購相關的工作,轉由全數交由機器學習處理。使得許多高階採購團隊成員相繼離職、另尋出路或者被公司調動職位。
亞馬遜這則新聞是2018年6月的新聞,這股「採購者職位調整」的風潮似乎離我們還很遙遠,相信許多讀者認為:
- 這是大公司僅存的現象,我任職的公司雖然雖然零售品有千樣以上,但建制這系統一定很昂貴,應該要幾億美金吧?
- 這種演算法一定是大公司才能負擔得起,我才不用擔心,採購很複雜,尤其是「銷售預測與評估」,機器根本不能跟人比,這就是唬人的消息!
- 唉~ 這種遠在天邊的消息,看看就好,不會真的實現。
面對如此質疑,讀者除了可以從下兩個連結詳盡參考亞馬遜的實際案例外,亦可同本文章作者使用「相對廉價(5萬元)」的電腦,為讀者實踐亞馬遜「簡化版」的「Python機器學習 — 自動採購與銷售預測」方法。
有解決方案與案例?
簡單講解過採購的概念及問題後,接著,我們要深入行銷資料科學的「資料科學」領域,使用我們在採購常用的資料結構,以Python 3 進行「自動採購與銷售」機器學習實戰!
我們即將使用一真實零售業的採購資料進行分析。與往常以「顧客UID」為主的分析方式有所不同,這次我們將以「產品面」的角度切入自動銷售。讀者可以想像一下,當我們被派任採購本月或本週,甚至是明日的商品數量時,我們可能依憑的資訊有:
- 日期 — 2018/1/1(還有過往10個月的資訊)
- 分店編號 — 5號分店、10號分店、15號分店均有出售
- 商品編號 — 55140
- 銷售量 — 20單位,一單位50元
- 促銷與否 — 目前沒促銷
等基本資料,接著,最困難的就來了,身為採購者的我們該如何根據現有狀況訂定5天後的採購數量? 一般來說,採購者便根據過往銷售資料採用移動平均法等方式找出可能的最適採購量,或者依憑直覺進行採購,但是當我們遇到促銷、周圍分店進行跳樓大拍賣等狀況時,面對單單一樣商品,或許我們還能應付,但如同前述所說,如果面對的是一位採購者至少要負責1000樣採購產品時…,精準的計算評估就顯得相當重要。
如果這時突然採購系統突然跳出一系統訊息:「根據機器學習分析,
- 建議5天後2018/1/5高麗菜的採購數量區間為27–34顆
- 預測銷售區間為1,250–1,700元
- 根據統計結果,機器準確率為82.25%,人為自訂準確率為64.27%,
因此建議您於本區間內執行採購。」
這時我們便有實在的數字依憑參考,讓機器成為輔助我們採購的好夥伴!
閱讀至此,讀者可以花幾秒整理思緒,想想我們這樣做的目的到底為何?
主要目的整理如下:
- 由機器預測萬種商品每天的銷售量,再由人工決定採購數量水位,協助採購者採購上猶豫的時間,節省人工每個月數千小時的估算。
- 可將大量商品相關標籤納入考量,提昇整體預測能力,例如:加入競爭對手、地理環境變數、各種利害關係人等標籤。
- 迅速掌握不同品項的「動態採購量」,便可根據時間週期調整商品供需。
資料來源:
某公司同意之真實零售業的採購資料為基底進行實做,並且已將敏感變數移除、屏蔽及全數變數加工處理。
模型方法與損失函數:
本次機器學習模型主要以 LightGBM(lgb),分析預測。原因為資料變數多達633種,最後亦有超過1千萬比觀察值,所以以快速且精準的lgb進行建模。損失函數則使用RMSLE。
目標變數:
銷售量_log:每一件商品的銷售量,這是我們要自動預測的變數,有了預測銷售量,我們就可以推測可能的採購量。由於具有右偏分佈,便對銷售量取log1p,讓其儘量呈現常態分佈,讓機器學習訓練上較好收斂。
標籤(或稱自變數):
- 日期 — 每件商品的日期
- 分店編號 — 每家分店編號
- 商品編號 — 每件商品編號,每一件商品都有他獨特的編號
- 促銷與否 — 每件商品的促銷狀況
- 生鮮與否 — 該商品是否為生鮮或者易腐食品
- 分類 — 商品分類
資料結構轉換:
首先來理解2017年開始的商品銷售紀錄(df_train),圖1顯示每一件商品每天在不同分店的銷售量與促銷資訊。由於每天不間斷記載著54家分店的紀錄,所以2017年累積下來便多達2,380多萬筆資料。
對於行銷人來說,如何能快速透過客戶、商品或CRM資料庫結合【機器學習】找出重要的【願意購買公司的產品的目標客群】、【商品推薦給誰,最會購買】與【消費者重視/覺得應改善的變數】無疑是行銷人最想了解的重要訊息。
對於資訊人來說,或許機器學習技法早就駕輕就熟,但是多數結果評估出來僅是給出準確率、損失函數,但是準確率真的等於獲利率嗎?所以更需要搭配實質的「期望獲利」等指標,讓機器學習真正與商業指標結合。
傳統方法上,便會使用敘述統計的方法,抓出購買過該商品客戶的相似用戶,可惜如此我們不但無法知道每一個客戶對該商品的購買可能性(機率),甚至無法確切以【有統計根據】的方法評估消費者重視/覺得應改善的變數。
本次專案將透過機器學習方法,產出【老闆與主管】可快速理解的【數據分析成果】。將客戶基本資料,如:性別、年齡、商品購買記錄等,發掘【目標客群願意購買公司的產品的機率】,作為廣告投放的參考標的!
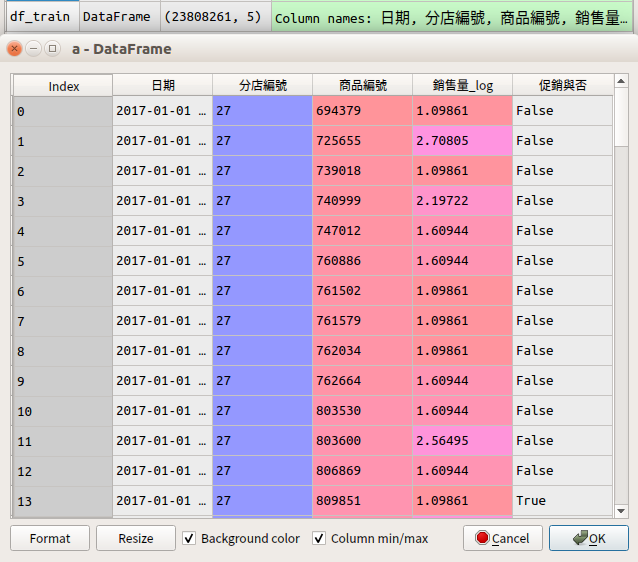
圖1.
再來是另一個項目資料紀錄(items),圖2紀錄著各項商品分類代碼與生鮮與否,我們會將本資料進行對商品銷售紀錄進行關聯,將資料串連在一起。從下圖維度可見我們本次有4,100項商品讓我們進行分析。

圖2.
最後則是分店紀錄(stores),圖3記載54家分店的城市、縣市及級別。

圖3.
商品為觀察值的資料結構轉換
因為我們要預測商品銷售量為主,所以在資料結構的排列上,圖4以商品本身為觀察值(當作「列」使用)。經過轉換後,我們可以看到圖4列出每一分店,每一的商品的資訊,讀者在這邊可以將其當作類似每一消費者(UID)的消費紀錄的概念來想像。

圖4.
知識領域的結晶:新增變數(feature)作為機器學習的變數
嚴格說起來,目前的變數僅有10個,扣除目標變數 — 銷售量,就僅剩下9個變數,如果能夠借重採購或銷售的「領域知識專家(Domain Knowledge Expert)」時常使用的評估手法,將其手法轉換成新的變數,讓機器學習演算法吸收其中精隨,讓預測效果更加準確。
經過與銷售與採購部門的討論後,領域知識專家根據經驗、上游廠商出貨速度、內部決策流程等,歸納出該公司最常以3, 7, 14, 30, 60, 140天數作為採購的「間隔標準」,更細部一點來說,便是以其間隔天數的平均、移動平均數值、中位數、最小值衡量下一次採購量的標準。
雖然認知憑借這些變數可以得出預測銷售與採購量,但是一旦上萬樣商品加入「領域知識的重要變數」,例如:間隔天數、生鮮與否、促銷與否、促銷內容、尺寸、顏色、經濟環境、競品狀況等,便使得預測評估變得更加複雜化起來,導致專家預測的銷售與採購量時常失準。
我們團隊對該領域的零售產業絕對不比這些專家,也比不過擁有的10–20年銷售與採購經理的經驗。不過這時候我們可將這場會議所提及的「知識領域」由原先的9個變數全數量化成超過1200個變數。會從9個變數延伸到超過1200個變數主要原因為:
- 有半數(本文章使用的633個變數)皆為公司每產品的3, 7, 14, 30, 60, 140的採購天數間隔做平均、移動平均、最大值等當作變數(如圖5所示)。
- 另外半數(其他約600個變數)則是使用每產品的促銷文字敘述、商品文字敘述、尺寸、顏色、經濟環境指標、平台種類、外部網路輿情、產品新聞內容等形成另外的600個變數(部份類別資料進行one-hot encoding及重要文字資料以也當作欄位,所以資料維度就會擴大),這些變數的使用原因為這些便是消費者第一眼接觸到的資訊,所以這些資訊對現場人員整商品而言非常重要;其二,我們能透過機器學習的方法找出哪些資訊需要加強,方便現場人員調整這些可控變因。不過因為資料敏感性,故不在此文章使用。
最後,放入機器學習演算法,套句我的啟蒙我機器學習的老師 — 李宏毅說的話「接著,機器就會自己學習」。
經過測試資料集的驗證確認後,就可得出每一家分店,每一樣商品,每天的銷售量,然後再反推採購數量。

圖5. 我們將所有銷售與採購會用到的相關知識全部量到機器學習演算法的新增變數中。
最後,我們透過領域知識的量化,最終神奇的從9個變數中,新增超過1200個變數(本次呈現633個變數供大家使用)
所以機器學習 — 自動採購到底有沒有效果阿?
說明具體效果前,讓我們將存貨理論中會提到的專業知識,如:Lead Time等要素不做考量,直接以每一天的存貨數量當作一天存貨成本計算的基準。
首先,我們直接以圖6的專家經驗法與機器學習法簡單觀看幾個商品觀察值查看差異,我們很快就可以查看到各自在銷售完後,雖然都有存貨(採購量-銷售量),但是明顯發現機器學習法在存貨控管上明顯比專家經驗法還要好。

圖6.
從專家經驗法,圖6明顯可以看專家怕缺貨而盡可能以庫存滿足消費者可能的需求,這樣的結果反而造成採購與貨成本反嗜了商品所帶來的利潤,舉例來說:
第一家分店的811237號商品於2017/7/28的實際銷售量為20個,依照專家經驗法,當天鋪貨就進103個,機器學習法則鋪11個,直觀上的結果是機器學習的方法少了9項銷售的收入,但實則我們計算下來可以發現:
每一天為基底:
專家經驗法:20(銷售量)*27(均價)- 83(存貨量)*3.57(單位存貨成本)= 243.69
機器學習法:11(銷售量)*27(均價)- 0 = 297
機器學習法比專家經驗法的收入還要高上53.31元
這時候會有讀者跳出來反駁,說:「哪有! 你看看第一家分店的810950號商品於2017/8/4銷售來說,專家比機器賺得錢還要高117元呢!」
讀者如果這樣思考沒錯,但如果該公司以往常每3天的進貨時間做考量,我們換個方向思考,以每三天為基底來計算的話:
每三天為基底8/4-8/6:
專家經驗法:(14+4+0)*27- (6+15+3)*3.57= 400.32
機器學習法:(14+4+0)*27- (-5+6+5)*3.57= 464.58
機器學習法比專家經驗法的收入還要高上64.58元
也就是說,機器學習自動採購能夠改善專家經驗法因為人工過量採購而帶來的庫存問題,進而節省庫存成本,轉化為更高的毛利。
透過機器學習 — 自動採購,可省多少及賺多少?
接著我們統計實戰的2,680,240筆資料在2017/7/26到2017/8/10,單純計算以每一天為基底的存貨成本與銷售總和後所帶來的成效。
首先來看圖7資訊意涵:
- 平均價錢:原始資料轉換後之各項價錢,真實情況依每一家分店及採購狀況而有所差異。
- 數量:以一天為基底為採購、存貨及銷售循環所統計的總數量。
- 小計:平均價錢 * 數量之總額。
- 利潤:銷貨收入扣除採購、存貨及人力成本之利益。
結果(2017/7/26到2017/8/10 共 15天的結果):
1.利潤方面
圖7發現54家分店實施機器學習法已經開始比20年專家經驗法的的利益還要高上約6千8百萬元 ($68,616,574)(未扣除租金、員工支出及其他營業成本,所以這的利潤會遠比淨利還高上好幾倍)。
2. 成本方面
細觀圖7,會發現「機器學習法」雖然銷貨收入明顯較「專家經驗法」在銷貨收入上少了2億元,但「機器學習法」在採購成本及存貨成本相對「專家經驗法」來說,省下約2億7千萬元 ( $269,557,060),計算出利潤後,發現「機器學習法」效果明顯大於「專家經驗法」。
3. 人力方面
節省人力方面,相較以往80人來說,有了「機器學習法」的協助,預計調整採購人員職位,將採購相關人員降低8倍,僅留10位專家,審核及調整機器學習法預測的採購數量,一口氣降低210萬的成本。

圖7.
管理意涵:
除使用機器學習法可以輔助採購人員使用圖8的資訊輔助,得到較好的利潤、降低人力成本外,更重要的是,這解決以往該公司諸多採購人員花用在決定現有產品採購量的時間,現今公司可適時進行採購人員職位調動,做機器學習法難以達成且更有意義的事情:
- 找出生命週期短的商品,思考改進策略,讓該商品成為長銷品,成為常銷品後,最後交由機器學習法進行採購計算。
- 找出銷量差的商品,思考銷售策略,決定該產品是否持續銷售或者進行下架,降低成本。
探討更多可量化之專家領域知識,加入機器學習法中,讓採購預測上更準確。例如:本文章資料使用633個變數,實際資料使用超過1,200個變數,利潤差異較633個變數還要好約2倍。

圖8.
另外,由於硬體及軟體物美價廉,我們可一一破解前述讀者可能擁有的迷思:
Q1:這是大公司僅存的現象,我任職的公司雖然雖然零售品有千樣以上,但建制這系統一定很昂貴,應該要幾億美金吧?
A1:我們僅用了5萬元「新台幣」、30G記憶體、8核心i7的CPU、1個人力成本在1個小時內就可以建起系統原型(Prototype),剩下的軟體如即時通報採購系統的Python架構,的確要花不少人力成本與時間,但是軟體全部都為open source免費,光在軟體層面完全不用花錢,省下相當的成本。所以不用以為真的要花到「幾億美金」才能建制,如果辦公室裡面有相仿的電腦設備,自己簡簡單單就可以建制一個自動採購系統。這相比那些動輒千萬,也不見得有效的ERP系統,這樣豈不是更能節省成本?
這種演算法一定是大公司才能負擔得起,我才不用擔心,採購很複雜,尤其是「銷售預測與評估」,機器根本不能跟人比,這就是唬人的消息!
A2:其實重點不是複雜的演算法或者機器成本,反而是我們有沒有辦法將採購人員的領域知識量化成機器學習所需要的「變數」,直接讓演算法學習人類過往20幾年累積的經驗,產生1臺5–20萬元以內的機器就可以抵擋百人團隊,達到省成本的目的。
唉~ 這種遠在天邊的消息,看看就好,不會真的實現。
A3:我們已經在這篇文章以低成本5萬元電腦就可以簡單呈現一個機器學習-自動採購的原型,老闆如果有心想要嘗試或狠心節省成本,賺取更高利潤,或許花個幾十、百萬元來「一次調整」數百個採購專員一年千萬的花費,在短期內也不是不可能發生的。
機器學習 — 自動採購僅可以用在零售業?
「萬物同源,萬法同宗」,既然零售業都可以使用,難道傳產等產業(萬物)不能使用嗎?不同場景使用得演算法幾乎都是同一個樣子(同宗),最重要的還是我們對演算法的輸入(input)品質、領域知識的量化變數以及在不同情況下所使用的模型為何,僅抓這三點就可以實踐「萬物同源,萬法同宗」的精神,在任何資料科學任務上無往不利。
