服務公司 B
公司簡介
資本額約6億新台幣;員工人數約400人
困境
- 如何降低員工離職率,找出員工離職的徵兆
目標
- 預測員工離職意願關鍵要素,提昇人力資源部門之人力管理效益
成效
- 透過將近20萬筆的離職員工資料,以隨機森林模型發展出99.93%準確率之離職模型,並運用於實務預測上
- 找出離職意願關鍵要素,並針對關鍵要素實際實施改革措施
技術應用
樹狀模型機器學習技術
Mixed effect模型
各類視覺化分析技術
案例剖析
假設驅動研究(Hypothesis-Driven Research)與資料驅動研究(Data-Driven Research)
2019年4月9日,新聞媒體出現了一則報導「IBM AI預測員工離職機率:正確率 95%,年省9億台幣留才費!」,正如標題所描述的,IBM開發出一套系統,能精準地在員工離職之前,預測他(她)何時即將離職,這樣IBM就能提前出手,挽留員工或者完成人力調度。根據IBM的估算,這套預測系統每年為公司節省9億新台幣,成效卓越。
儘管在該篇文章中,並未詳細說明離職預測模型建置的原理,只強調是透過人工智慧AI的方式來進行。事實上,目前可預測員工離職的方法越來越多,但這一篇文章我們先不討論人資單位如何預測哪些員工可能離職。我們打算先以「如何降低離職率」為例,讓大家了解一下傳統社會科學常用的方法論(又稱「假設驅動研究(Hypothesis-Driven Research)」),以及大數據分析所使用的方法論(又稱「資料驅動研究(Data-Hypothesis-Driven Research)」),有何不同。
首先我們回顧一下,以往要研究如何降低離職率,會如何進行?一開始,我們會先試著站在巨人的肩膀上,回顧一下現有的文獻,看看針對這個議題,有哪些已經發表過的文獻可以參考。上網搜尋後可發現,過去40多年,不斷有學者提出離職模型,例如:Mobley(1979)、Steers Mowday(1979)、Price-Mueller(1981)…等。如圖1、2、3所示。
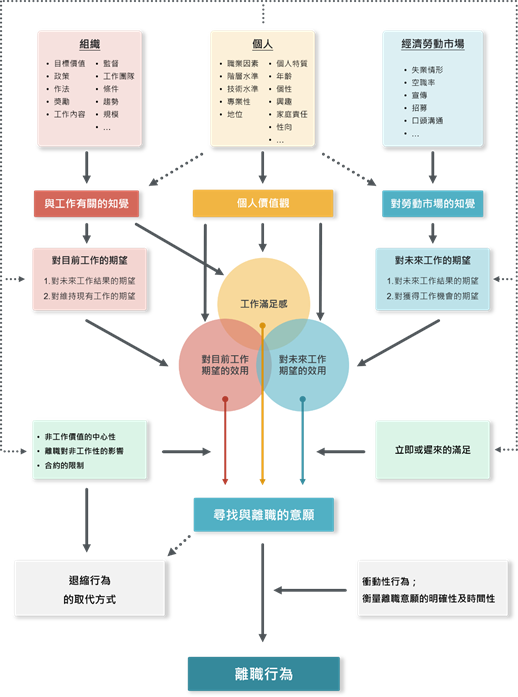
圖1. Mobley(1979)等人之離職模型(繪圖者:彭煖蘋)
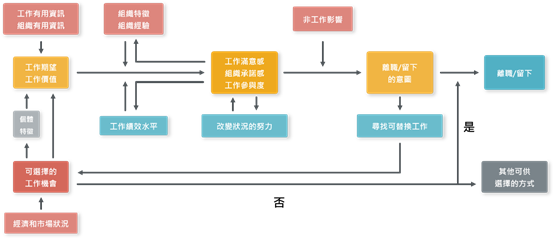
圖2. Steers & Mowday(1979)之離職模型(繪圖者:彭煖蘋)
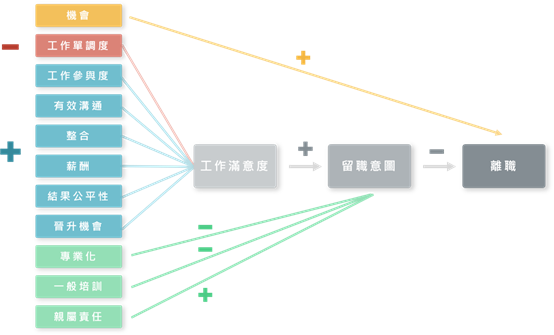
圖3. Price-Mueller(1981)之離職模型(繪圖者:彭煖蘋)
我們從以上三個例子可以看到,學者在發展模型的過程中,通常會先進行文獻探討,臚列出造成離職的可能動機(自變數),然後發展假設,再經由研究設計、抽樣設計、透過對樣本資料進行分析,驗證假設是否成立。而後續接手同一議題的學者則就自己的觀察,對之前研究者所發展出的模型,進行批判與補充,如此反覆循環。最終,這些模型透過各種假設的推論與驗證,並經後續學者們不斷地優化,漸漸地將離職模型的全貌勾勒出來。而這些模型發展的過程,就是傳統社會科學常用的方法論,又稱為「假設驅動研究(Hypothesis-Driven Research)」。
至於何謂「資料驅動研究(Data-Hypothesis-Driven Research)」。2009年Google於Nature發表了一篇文章「Detecting influenza epidemics using search engine query data」,內容談到Google透過分析5,000萬個使用者常用的搜尋字串,同時比對2003年到2008年間季節性流感的傳播資料,進而發展出預測流感的模型。為了對流感進行預測,Google陸續建立了4.5億個不同的數學模型,作法上要比過去傳統的模型更加精準。而以上的方法論即為「資料驅動研究(Data-Driven Research)」。
回到「如何降低離職率」這個議題上,要降低員工離職率,最佳的方式可能是想辦法預測同仁何時可能會離職,進而讓主管在同仁離職之前,就能先行加以挽留,並藉此讓優秀同仁留下來。
以「資料驅動研究」的概念為基礎,筆者藉由公司的人資資料,發展出離職預測模型。在發展模型的過程中,相關變數包括基本資料、人資資料、績效表現資料等共41項,內容如:部門、職位、性別、學歷、每日遲到分鐘數、遲到次數、請假、考績等,分析約20萬筆(項)紀錄。並採用隨機森林(Random Forest)為工具進行分析。而為了衡量模型的預測效能,將資料隨機切分成70%的訓練資料集(Calibration Sample),以及30%的驗證資料集(Holdout Sample),做為模型檢驗。

圖4. 運用隨機森林建立預測模型(繪圖者:鍾皓軒)
根據預測模型,我們挑選出「考績」、「月遲到分鐘數」、與「年齡」是公司整體離職的重要特徵(關於這一部分,每家企業可能會有很大差異。一位曾經為台灣某家世界級企業做過類似專案的教授就曾分享,影響該公司離職率最大的變數是「請假」)。
這項發現,在「考績」與「年齡」上並沒有太大的驚喜,畢竟各行各業「考績」差、「年齡低」的員工離職率較高實屬常態。但是「月遲到分鐘數」的重要性竟然高過「年齡」等其他變數,就值得進一步探討。先撇開學術研究不談,這樣的結果,對各單位的主管來說,除了可讓主管發現個別員工可能離職的前兆(例如:月遲到分鐘數高的人),同時也可發現哪些員工已經接近自願性離職的邊緣(考績差、月遲到分鐘數高、年齡低的同仁)。
以上資料驅動研究(Data-Driven Research)乃是透過「資料庫知識探索(Knowledge Discovery in Database,簡稱KDD)」的方法來進行。在做法上,KDD透過訂定目標、建立目標資料集、資料清理與前置處理、資料轉換、選擇資料探勘方法、選擇資料探勘演算法、資料探勘(data mining)、解釋探勘模式和鞏固發現的知識等步驟找出預測模型。
從以上離職模型的探討中我們可以發現,「假設驅動研究(Hypothesis-Driven Research)」著重在員工離職的心理動機,而「資料驅動研究(Data-Hypothesis-Driven Research)」則以員工在職場上實際工作所呈現的資料,做為研究內容,而這也是兩者最大的差異所在。
