情境
疫情初期,有一段影片顯示一名女子正在吃煮過的「蝙蝠」,並形容蝙蝠吃起來「很像雞肉」。這個影片在網路上引起了大量的反彈,許多人批評這個吃野味的習慣是新冠病毒的原因。但實際上,這個影片並非在武漢拍攝,而是由中國旅遊節目主持人汪夢雲 2016 年在西太平洋島國帕勞拍攝的旅遊節目。這個例子清楚地展示了「新聞」如何散播謠言,並對無辜的人或群體造成傷害(BBC NEWS, 肺炎疫情:隨病毒擴散全球的五大假新聞 2020)。
上述案例實際上就是「假新聞」,而「假新聞」,已存在於你我生活之中!
何謂假新聞?
(王維菁 et al., 2021) 提到,假新聞的定義為刻意以模擬、類似新聞的形式,來傳遞虛假及錯誤的訊息,目的在誤導大眾,以獲取政治或經濟利益。假新聞大致上可以分為以下幾種類型:
- 諷刺:指以戲謔、挖苦或誇張的方式傳播的資訊,例如:諷刺漫畫、惡搞影片或惡意評論
- 誤傳:指因為疏忽或無知而傳播錯誤的資訊,例如:錯別字、資料錯誤或引用錯誤
- 欺騙:指故意製造或修改資訊,以達到某種目的或利益,例如:偽造文件、照片或影片,或者故意選擇性地報導資訊
- 謠言:指沒有確實的來源或證據而傳播的資訊,例如:未經證實的傳聞、猜測或推測
為什麼識別假新聞重要呢?
假新聞是一種對事實和真相的扭曲,可能造成社會的混亂和分裂,影響民主政治和公共利益。假新聞不僅挑戰媒體專業主義和公信力,對我們來說,更是對數位媒體素養和批判思考能力的考驗(羅世宏, 2018)。
我們可以透過多種方式來對抗假新聞。首先可以利用新聞事實查核組織或其他可靠的資訊來源來驗證新聞的真實性。此外,我們也可以主動闢謠和更正錯誤資訊。
另一種方法是利用機器學習和深度學習技術來判斷新聞的準確性。這些技術可以初步探查新聞的準確性,並有助於我們更有效地識別和防止假新聞的傳播,從而保護公眾的權益和社會的穩定。這些都是我們對抗假新聞的重要工具。
在知道了判斷真假新聞的重要性後,本系列文章將帶讀者探索「假新聞偵測」的世界。本系列將分成兩個系列。系列一,進行資料理解和探索性資料分析(EDA);系列二,進行建模前必要的資料前處理,如:詞向量轉換等和建模,以建立出假新聞偵測器。透過這兩篇系列文的文章,我們將逐步建立出能偵測假新聞的工具!
那我們就開始系列一:假新聞預測(1)- 資料清理與理解吧!
載入套件
首先載入資料處理、視覺化等套件。
""" re, string, unicodedata, punctuation 為 Python 的標準函式庫,用於處理正則表達式、字符串和 Unicode 資料 """
import re
import string
import unicodedata
from string import punctuation
""" numpy 和 pandas 為資料處理的函式庫 """
import numpy as np
import pandas as pd
""" seaborn 和 matplotlib 為用於資料可視化的函式庫 """
import seaborn as sns
import matplotlib.pyplot as plt
import plotly.express as px
import plotly.graph_objects as go
""" BeautifulSoup 用於解析 HTML 和 XML 文檔 """
from bs4 import BeautifulSoup
""" sklearn 為機器學習函式庫,同時也包含資料預處理到模型評估的工具 """
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
from sklearn.model_selection import train_test_split
""" nltk 為自然語言處理函式庫,提供了從文本清洗到詞性標註的工具 """
import nltk
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk import pos_tag
from nltk.corpus import wordnet
nltk.download('stopwords')載入資料集
接著載入資料集,本系列文共有兩個資料集,包含真假新聞的資料:
- True.csv:真新聞資料集
- Fake.csv:假新聞資料集
# 載入真新聞資料集
true = pd.read_csv("True.csv")
# 載入假新聞資料集
fake = pd.read_csv("Fake.csv")合併資料
在此步驟,我們新增 category 欄位,用於表示該新聞的類別。接著會將兩個資料集合併起來,即可在同一個資料集中同時處理真假新聞:
- 如果 category 為「1」,則表示該新聞為「真新聞」
- 如果 category 為「0」,則表示該新聞為「假新聞」
# 真新聞
true['category'] = 1
# 假新聞
fake['category'] = 0
# 合併 true, fake 資料集
news_dataset = pd.concat([true, fake], axis=0)探索性資料分析(EDA)
合併完成後,先來進行 EDA,以幫助我們更好地理解資料,並發現可能的模式、趨勢和異常。在此會進行以下 EDA,:
- 查看資料是否存在缺失值:目的是確保資料的完整性
- 查看真假新聞的比例:目的是確保資料是否存在不平衡的情況
查看資料是否存在缺失值
news_dataset.isna().sum()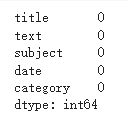
- 如圖 1 所示,可以看到資料並無存在缺失值,所以不需額外處理
查看真假新聞的比例
- 查看真新聞和假新聞在資料集中的分佈情況
fig = px.histogram(
news_dataset,
x="category",
color="category"
)
fig.update_layout(
title="真假新聞比例",
title_x=0.5,
width=700,
height=500,
bargap=0.03
)
fig.show()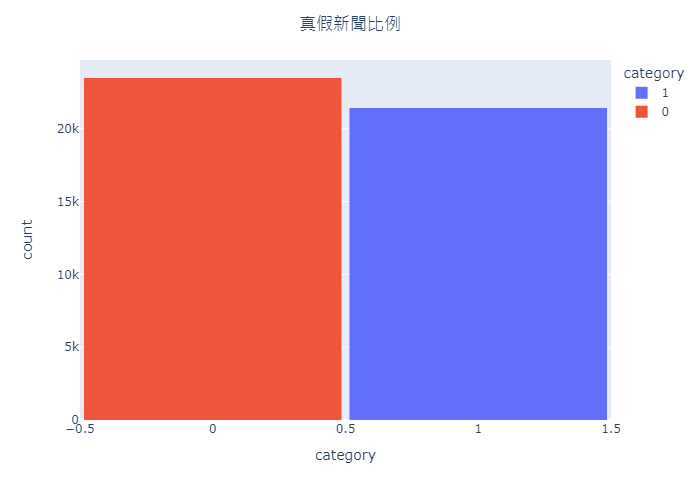
- 如圖 2 所示,可以看到資料集當中真假新聞的比例並無相差太多,因此也不需額外處理資料不平衡的問題
文字最終整併:產出 text 欄位
- 此步驟將所有的文字資料合併在一起,讓我們可以一次處理所有文字的資料
# 將 text 與 title 合併起來,並刪除不需要的欄位
news_dataset['text'] = news_dataset['text'] + " " + news_dataset['title']
del news_dataset['title']
del news_dataset['subject']
del news_dataset['date']文字資料處理
完成上述 EDA 以及合併文字後,接下來要針對「text」進一步處理,以下是處理的步驟:
- 去除 HTML 標籤:HTML 標籤在本資料集文本中並無意義,因此將其去除
- 去除停用詞(stopwords):停用詞是指在語言中使用頻率非常高但實際意義不大的詞,例如 “the”、”is” 等,所以將從文本中去除停用詞
- 去除網址:網址在本資料集文本中無特別意義,因此將其去除
- 去除標點符號:標點符號在某些情況下可能會對分析產生影響,因此我們選擇去除它們。
設定停用詞
首先先設定停用詞,並新增標點符號於停用詞當中。
※ 本系列使用 nltk 內建的 stopwords
# 預設停用詞
stop = set(stopwords.words('english'))
# 加入標點符號
punctuation = list(string.punctuation)
stop.update(punctuation)文字清理
- 在此步驟會進行去除 HTML 標籤、停用詞(包含標點符號)以及網址
# 在文本中,有出現類似於 HTML 的標籤,例如:<NOV N.S>等,因此將其去除
def remove_html_tags(text):
soup = BeautifulSoup(text, "html.parser")
return soup.get_text()
# 移除方括號
def remove_text_inside_brackets(text):
return re.sub('\[[^]]*\]', '', text)
# 移除 URL
def remove_url_links(text):
return re.sub(r'http\S+', '', text)
# 移除停用詞
def remove_stopwords(text):
return " ".join([word for word in text.split() if word.strip().lower() not in stop])
def clean_text(text):
text = remove_html_tags(text)
text = remove_text_inside_brackets(text)
text = remove_url_links(text)
text = remove_stopwords(text)
return text
# Apply function on review column
news_dataset['text'] = news_dataset['text'].apply(clean_text)合併後 EDA
- 在處理完文字後,最後可以再次進行 EDA 來更加了解文字的資料
- 下述將查看字詞長度以及 n-gram 長度
字詞長度
- 查看文本中字詞的長度分佈,目的在於了解真新聞和假新聞在字詞使用上的差異
# 對於真新聞的文本,首先將其分割成字詞,然後計算每條新聞的字詞數量
original_text_len = (
news_dataset
.query("category == 1")
.assign(text_split = lambda df: df['text'].str.split())
.assign(text_len = lambda df: df['text_split'].map(lambda x: len(x)))
)
true_plot = (
original_text_len['text_len']
.value_counts()
.reset_index()
.rename(columns={
"index": "text_len",
"text_len": "counts"
})
)
# 對於假新聞的文本也進行相同的操作
fake_text_len = (
news_dataset
.query("category == 0")
.assign(text_split = lambda df: df['text'].str.split())
.assign(text_len = lambda df: df['text_split'].map(lambda x: len(x)))
)
fake_plot = (
fake_text_len['text_len']
.value_counts()
.reset_index()
.rename(columns={
"index": "text_len",
"text_len": "counts"
})
)# 創建真新聞直方圖
original_text_hist = go.Histogram(
x=true_plot['text_len'],
y=true_plot['counts'],
nbinsx=20,
name='真新聞',
marker_color='green',
texttemplate="%{y}",
textfont_size=12,
textposition='outside'
)
# 創建假新聞直方圖
fake_text_hist = go.Histogram(
x=fake_plot['text_len'],
y=fake_plot['counts'],
nbinsx=20,
name='假新聞',
marker_color='red',
texttemplate="%{y}",
textfont_size=12,
textposition='outside'
)
# 最後,我們將這兩個直方圖添加到同一個圖形中
fig = go.Figure(data=[original_text_hist, fake_text_hist])
# 更新圖形的標題和軸標籤
fig.update_layout(
title_text='真假新聞字詞數量對比圖',
xaxis_title='字詞數量',
yaxis_title='次數',
bargap=0.2,
bargroupgap=0.05,
width=1000,
)
# 最後,顯示圖形
fig.show()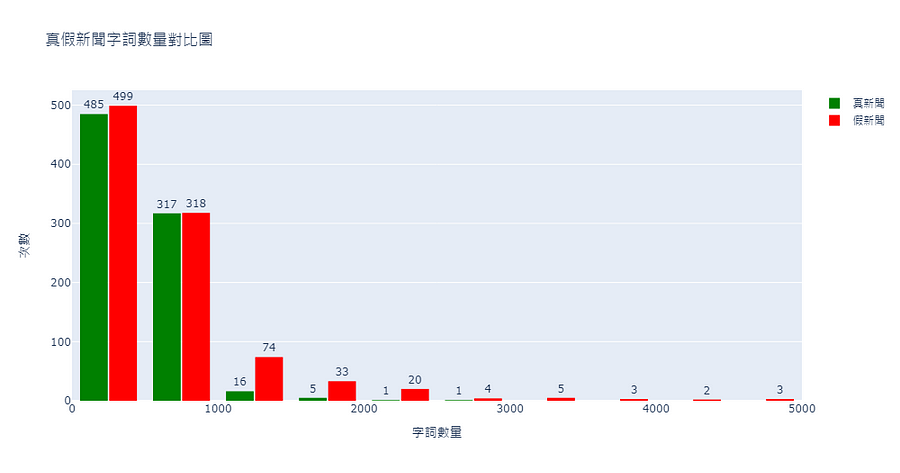
從圖 3 可得知假新聞每條新聞的字詞長度都高於字詞長度,且超過 3000 字以上的新聞皆為假新聞。
n-gram 長度分布圖
- n-gram 用於表示文本中連續 n 個項目(如單詞或字母)的序列,舉例來說:在一個 “我愛你” 的句子中,2-gram(也被稱為 bigram)會是 [“我愛”, “愛你”]
- 繪製 n-gram 可以讓我們大致了解本資料集的文本風格、結構
# 定義一個函數來獲取文本中出現頻率最高的 n-gram
def get_most_common_ngrams(corpus, n, g):
# 使用 CountVectorizer 來將文本轉換為詞頻矩陣
vectorizer = CountVectorizer(ngram_range=(g, g)).fit(corpus)
# 將文本轉換為詞袋模型
bag_of_words = vectorizer.transform(corpus)
# 計算每個詞的總出現次數
total_word_count = bag_of_words.sum(axis=0)
# 創建一個列表來存儲每個詞及其出現次數
word_frequency = [(word, total_word_count[0, idx]) for word, idx in vectorizer.vocabulary_.items()]
# 將列表按照詞的出現次數進行排序
word_frequency = sorted(word_frequency, key = lambda x: x[1], reverse=True)
# 返回出現次數最高的 n 個詞
return word_frequency[:n]
# 設置圖形的大小
plt.figure(figsize = (16,9))
# 使用上面定義的函數來獲取出現頻率最高的二元詞組
most_common_bigrams = get_most_common_ngrams(news_dataset["text"], 10, 2)
# 將結果轉換為字典
most_common_bigrams_dict = dict(most_common_bigrams)# 使用 plotly express 的 bar 函數來創建一個長條圖
fig = px.bar(
x=list(most_common_bigrams_dict.values())[::-1], # 反轉 list 的用意是讓圖由高至低排序
y=list(most_common_bigrams_dict.keys())[::-1], # 反轉 list 的用意是讓圖由高至低排序
labels={'x':'Count', 'y':'Words'},
orientation='h',
color=list(most_common_bigrams_dict.values())[::-1],
)
# 更新圖形的標題和標題的位置
fig.update_layout(
title="前 10 名 Bigrams(兩兩配對的字詞)",
title_x=0.5,
autosize=False,
width=800,
height=500
)
# 顯示圖形
fig.show()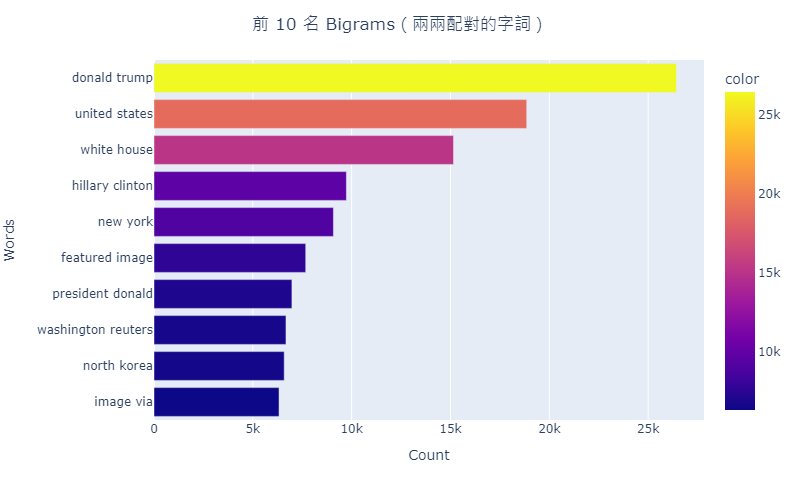
從圖 4 可看到字詞大多是與總統相關的字詞,因此可推測本資料集是在總統大選期間所蒐集到的資料。這也呼應在開頭提到的,假新聞其中一個利益是為了獲取「政治」的利益。
結論
在本文中,帶各位讀者從讀入資料、資料處理到 EDA,對於資料進行了完整的資料理解,最後我們可以統整出以下結論:
- 資料集中無缺失值
- 資料集中無資料不平衡的問題
- 假新聞擁有較高每條新聞的字詞長度
- 在總統大選期間,會產生大量的假新聞(因為真假新聞的比例竟然相差無幾)
從上述可得知,本次的資料集非常友善,不用讓花費太多時間在資料清理上。藉此讓我們在接下來的系列,可以專注在進行「詞向量轉換」以及「假新聞偵測模型的建置」!就請各位讀者敬請期待吧~!
The best way to learn Data Science, is to do Data Science.
作者:蔡尚宏(臺灣行銷研究資料科學家)、劉加德(臺灣行銷研究特邀編審)、鍾皓軒(臺灣行銷研究有限公司創辦人)
問卷(待補)
Reference
王維菁, 廖執善, 蔣旭政, & 周昆璋. (2021). 利用AI技術偵測假新聞之實證研究 [Journal article]. Empirical Research on Fake News Detection Using AI Technology, 39, 043–070. https://search.lib.ntut.edu.tw/ntut/sendurl_api_v3eds.jsp?pr=hy&url=https://search.ebscohost.com/login.aspx?direct=true&db=edshyr&AN=hyr.00590773&lang=zh-tw&site=eds-live
羅世宏. (2018). 關於「假新聞」的批判思考:老問題、新挑戰與可能的多重解方 [Journal article]. A Critical Thinking on ‘Fake News’: Old Problems, New Challenges and Possible Solutions, 35, 051-086. https://search.lib.ntut.edu.tw/ntut/sendurl_api_v3eds.jsp?pr=hy&url=https://search.ebscohost.com/login.aspx?direct=true&db=edshyr&AN=hyr.00501056&lang=zh-tw&site=eds-live
BBC. (n.d.). 肺炎疫情:隨病毒擴散全球的五大假新聞. BBC News 中文. https://www.bbc.com/zhongwen/trad/chinese-news-51293515
MATHUR, M. (n.d.-b). NLP using GloVe Embeddings(99.87% Accuracy). Kaggle. https://www.kaggle.com/code/madz2000/nlp-using-glove-embeddings-99-87-accuracy/notebook
