接續上篇文章,用資料分析的方法分析了資料科學家所需具備的跨領域知識、大多的工作內容及程度,以及所需的的程式技能,如果還沒看過的話可以點擊下方連結!
此篇文章,我們將繼續和大家分享要運用那些資料才能成為資料科學家,那麼我們就開始吧~
一、如果要深入資料科學,可以透過什麼資源來了解呢?
市面上有很多資料科學的相關課程與資源,但是該選擇哪一個呢? 別擔心! 我們依照資料科學家們的經驗,來為您做精準推薦!
我們將使用資料集中的Q12. 喜愛資源及Q13.喜愛課程來進行分析,以下分別為Q12、Q13的題目設定:
Q12. Who/what are your favorite media sources that report on data science topics? (Select all that apply) — Selected Choice
Q13. On which platforms have you begun or completed data science courses? (Select all that apply) — Selected Choice
1. 喜愛資源資料預處理
我們繼續使用相同的方法計算Q12. 喜愛資源複選題的選擇數量 (如下圖一)。
# 取出Q12的資料
lst = []
for i in multiple_choice.columns:
if i[:3] == 'Q12':
lst.append(i)
source = multiple_choice[lst].iloc[1:,]# 取出Q12多選題的選項
choose = multiple_choice[lst].iloc[0].apply(lambda x: ''.join(x.split('-')[2:]).replace(' ',''))# 統計各選項選擇數量
source_df = pd.DataFrame()
source_df['choice'] = list(choose.values)source_df['value'] = list(map(lambda i: len(source.iloc[:,i].dropna()), list(range(source.shape[1]))))source_df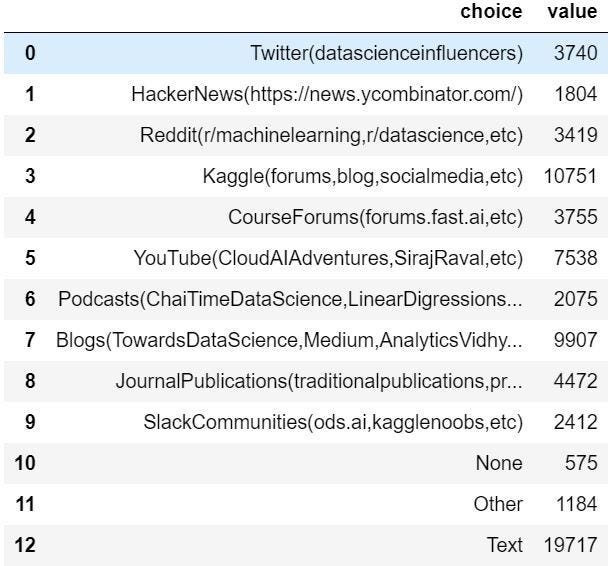
2. 喜愛課程資料預處理
還有Q13. 喜愛課程複選題的選擇數量的資料整理 (如下圖二)。
# 取出Q13的資料
lst = []
for i in multiple_choice.columns:
if i[:3] == 'Q13':
lst.append(i)
course = multiple_choice[lst].iloc[1:,]# 取出Q13多選題的選項
choose = multiple_choice[lst].iloc[0].apply(lambda x: ''.join(x.split('-')[2:]).replace(' ',''))# 統計各選項選擇數量
course_df = pd.DataFrame()
course_df['choice'] = list(choose.values)course_df['value'] = list(map(lambda i: len(course.iloc[:,i].dropna()), list(range(course.shape[1]))))course_df['choice'] = course_df['choice'].replace('KaggleCourses(i.e.KaggleLearn)','KaggleCourses')course_df['choice'] = course_df['choice'].replace('UniversityCourses(resultinginauniversitydegree)','UniversityCourses')course_df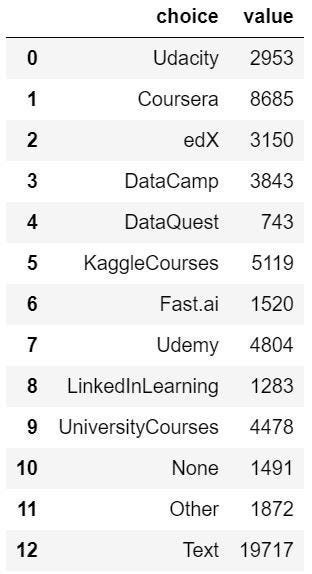
3. 喜愛資源資料視覺化
接著一樣使用plotly套件,這次使用圓餅圖來呈現(如下圖三)。
# 圖表繪製
import plotly.express as px
fig = px.pie(source_df.iloc[:-3,], values='value', names='choice', title='Media Sources Selected',
color_discrete_sequence=px.colors.sequential.Sunsetdark)
fig.update_traces(textposition='inside')
fig.show()# 自動儲存
pyplt(fig, filename ='Media Sources Selected.html')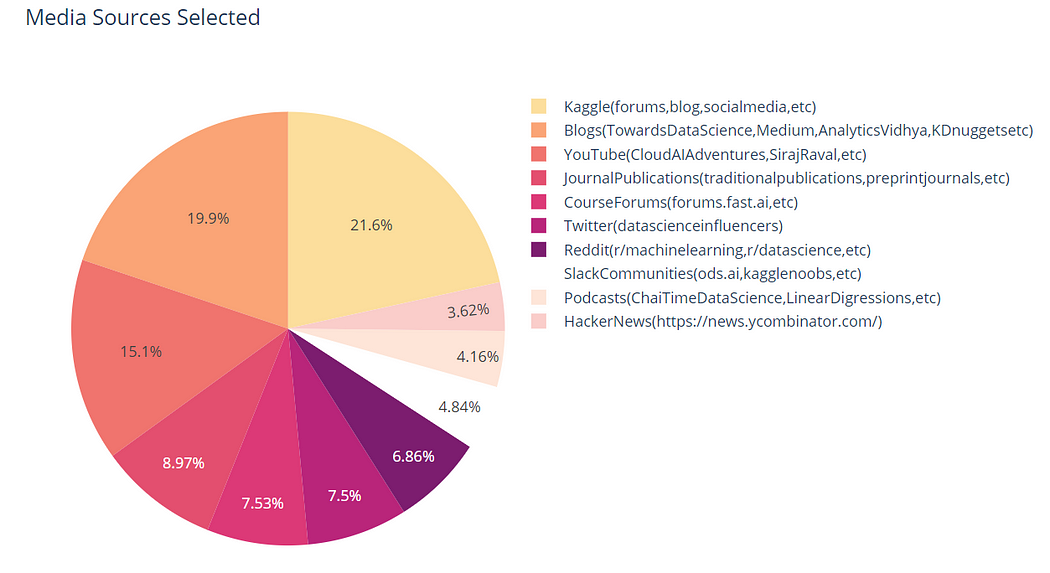
4. 喜愛課程資料視覺化
使用一樣的方法繪製喜愛課程圓餅圖 (如下圖四)。
# 圖表繪製
import plotly.express as px
fig = px.pie(course_df.iloc[:-3,], values='value', names='choice',
title='Data Science Courses Selected',
color_discrete_sequence=px.colors.sequential.Mint)
fig.update_traces(textposition='inside', textinfo='percent+label')
fig.show()# 自動儲存
pyplt(fig, filename ='Data Science Courses Selected.html')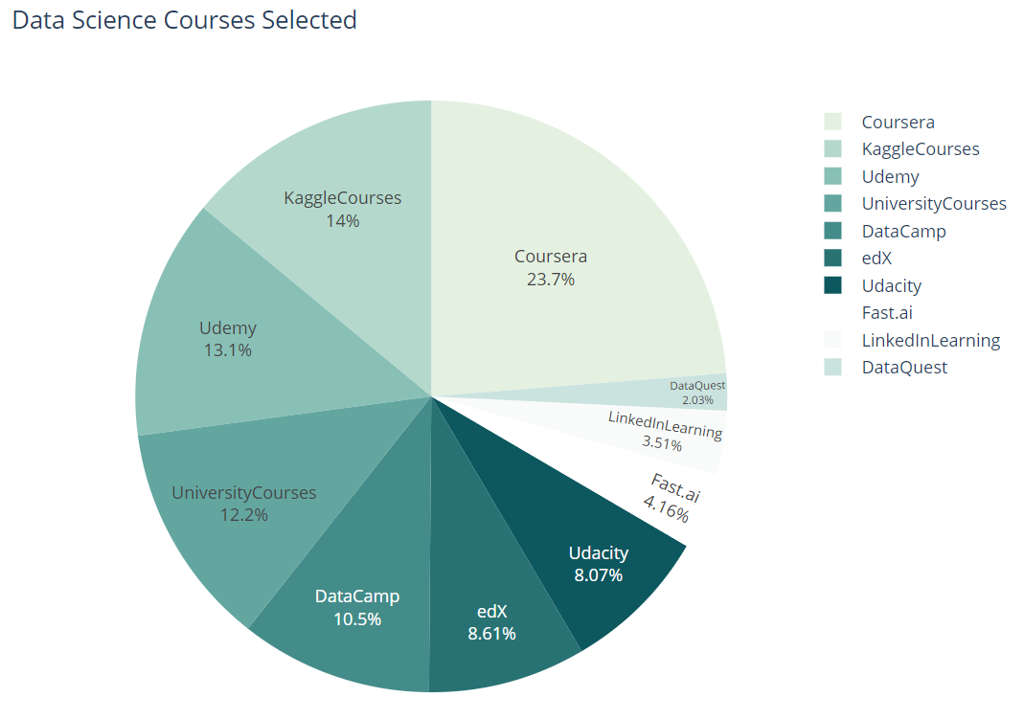
5. 分析
從以上兩個圓餅圖,可以得到最受喜愛的media sources前三名:
- Kaggle (forums, blog, social media, etc.)
- Blogs (TowardsDataScience, Medium, AnalyticsVidhya, KDnuggets, etc.)
- YouTube (CloudAIAdventures, SirajRaval, etc.)
Kaggle是一個資源豐富且非常容易上手的資料科學平台,可以找到許多結構完整、多元的資料集方便做使用,此外許多資料科學家會以notebook的方式呈現資料分析細節,非常適合初學者來做臨摹參考。
在Blogs的部分,以我自身的經驗非常推薦Medium平台,現在有許多臺灣或國外的資料從業人員在Medium上分享自己的資料分析經驗,同常這些文章撰寫的時間也在近幾年間,所以可以得到非常新的資訊!
Youtube上的資源也非常的充足,其中我最推薦的是台大李宏毅教授的機器學習課程! 有非常詳細且易懂的教學,非常適合初學者來入門。
此外,最受喜愛的data science courses前三名分別為:
此三個平台上都有豐富的資料科學課程,大家都可以點選上面的連結瀏覽一下,其中我自己觀看過Udemy的Machine learning A-Z課程,在Python及R的機器學習基礎上有很詳細的介紹,也推薦給大家。
來幫大家結論一下~
根據此份Kaggle資料集的分析結果,我們來逐一回答一開始提出的問題:
- 資料科學家主要工作內容有哪些?
分別為「分析並了解資料對產品或企業決策的影響、探索機器學習應用領域、改善現有的機器學習模型」簡單地來說,只要掌握好數理、資訊科學、應用領域三方面的技能,資料科學家的工作絕對難不倒你! - 資料科學家會使用哪種程式語言?
Python近乎完勝所有工作領域,因此會建議新手從Python開始學起。而各個程式語言的功能也有所不同,可以根據資料處理的需求來選擇最適合的工具。此外,也非常推薦學習R語言,在資料分析中的統計分析及視覺化上可以大大助您一臂之力! - 如果要深入資料科學,可以透過什麼資源來了解呢?
首先,我建議可以從Udemy的Machine learning A-Z課程來入門。在了解Python的基礎後,推薦觀看台大李宏毅教授的機器學習課程,也可以根據自己的需求或有興趣的領域,在Coursera、KaggleCourses或Udemy平台上選擇最適合的課程!
Plotly套件補充資訊!

簡單講解一下Plotly套件的五大特色:
- Dynamic & Interactive
- Open-source plotting library
- Supports over 40 unique chart types
- Covering a wide range of statistical, financial, geographic, scientific, and 3-dimensional use-cases
- Support for Python and R
Plotly在資料視覺化上是非常好的輔助工具,「動態繪圖」是它與其他繪圖套件最不同的地方,此外plotly可以繪製出各種不同的圖表,以下我們繼續使用Kaggle的資料集為例,視覺化分析資料科學家的薪水,來展示plotly的強大威力!
1. 資料預處理
取出我們所需的資料,分別為Q3.國籍、Q5.職業及Q10.薪水 (如下圖五)。
# 抓取Q3、Q5、Q5,並去除空值及符號
world_salary = multiple_choice[['Q3','Q5','Q10']].iloc[1:,:]
world_salary = world_salary.dropna()
world_salary['Q10'] = world_salary['Q10'].str.replace('$','', regex=False)
world_salary['Q10'] = world_salary['Q10'].str.replace(',','', regex=False)
world_salary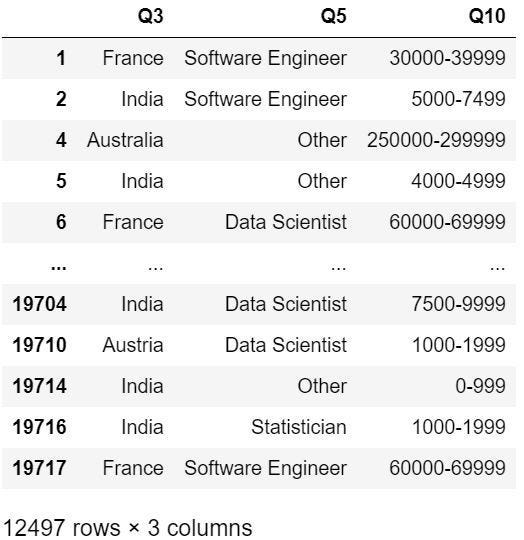
由於Q10.薪水蒐集的資料,是以「區間」來表示的,因此我們使用區間的中間值來代表 (如下圖六的 ‘salary’)。
# 薪水的上、下區間
world_salary['salary_lower_bound'] = pd.to_numeric(world_salary['Q10'].str.split('-', expand=True)[0], errors='coerce')world_salary['salary_upper_bound'] = pd.to_numeric(world_salary['Q10'].str.split('-', expand=True)[1], errors='coerce') + 1# 取上、下區間中間值
world_salary['salary'] = (world_salary['salary_upper_bound'] + world_salary['salary_lower_bound'])/2# 更改column names
world_salary.columns = ['country', 'job', 'salary_range', 'salary_lower_bound', 'salary_upper_bound', 'salary']world_salary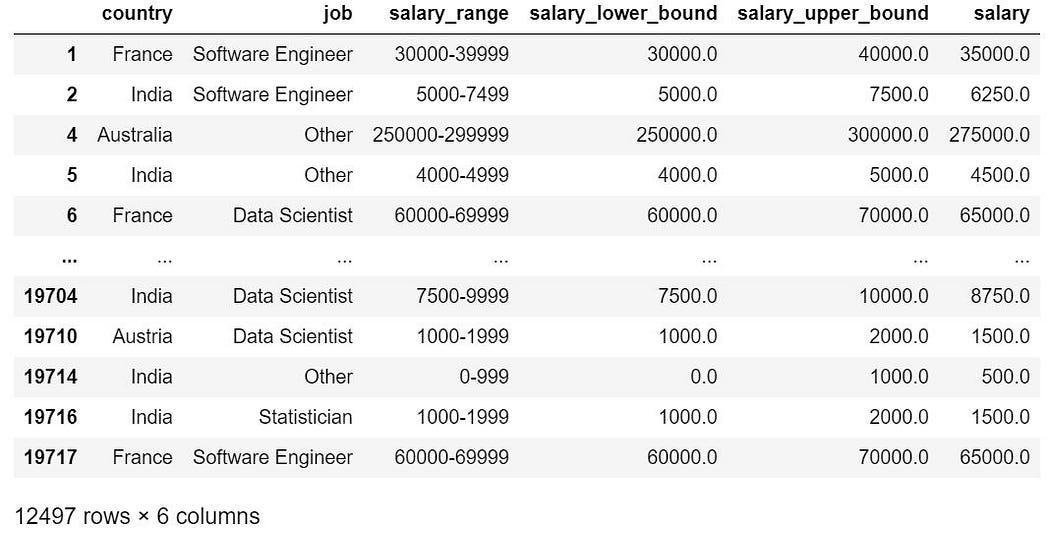
計算每個國家的資料科學家平均薪水,由於後續要和另一個dataframe合併,因此對幾個國家名稱的編碼做調整,如:’United States of America’ 改成 ’United States’ (下圖七)。
# 取出資料科學家的資料
world_salary_ds = world_salary[world_salary['job'] == 'Data Scientist']# 計算國家的平均薪水
country_salary_ds = pd.DataFrame(world_salary_ds.groupby('country')['salary'].mean().astype('int'))country_salary_ds = country_salary_ds.reset_index()
country_salary_ds = country_salary_ds.sort_values(by = 'salary', ascending = False).reset_index(drop = True)# 更改國家名稱
country_salary_ds['country'] = country_salary_ds['country'].str.replace('United States of America','United States')country_salary_ds['country'] = country_salary_ds['country'].str.replace('United Kingdom of Great Britain.*','United Kingdom')country_salary_ds['country'] = country_salary_ds['country'].str.replace('Iran, Islamic Republic.*','Iran')country_salary_ds['country'] = country_salary_ds['country'].str.replace('South Korea','Korea, Rep.')country_salary_ds['country'] = country_salary_ds['country'].str.replace('Republic of Korea','Korea, Dem. Rep.')country_salary_ds['country'] = country_salary_ds['country'].str.replace('Hong Kong (S.A.R.)','Hong Kong, China')country_salary_ds['country'] = country_salary_ds['country'].str.replace('Viet Nam','Vietnam')country_salary_ds.head(10)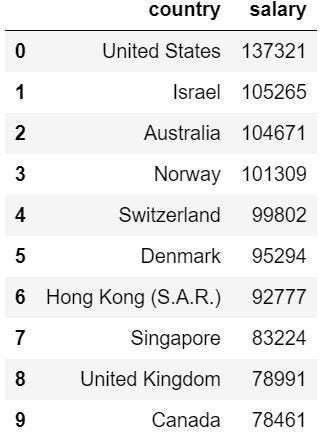
將國家的country code也加入dataframe中,以做後續繪圖的參考 (如下圖八)。
#加入country code
import plotly.express as px
df = px.data.gapminder().query("year == 2007")[['country','continent','iso_alpha']]country_salary_merge_ds = pd.merge(country_salary_ds, df, on = 'country')# 將缺少的國家加入
country_salary_merge_ds = country_salary_merge_ds.append({'country':'Russia','salary':28000,'continent':'Europe','iso_alpha':'RUS'},ignore_index=True)country_salary_merge_ds = country_salary_merge_ds.append({'country':'Ukraine','salary':29102,'continent':'Europe','iso_alpha':'UKR'},ignore_index=True)country_salary_merge_ds = country_salary_merge_ds.append({'country':'Belarus','salary':27568,'continent':'Europe','iso_alpha':'BLR'},ignore_index=True)country_salary_merge_ds.head(10)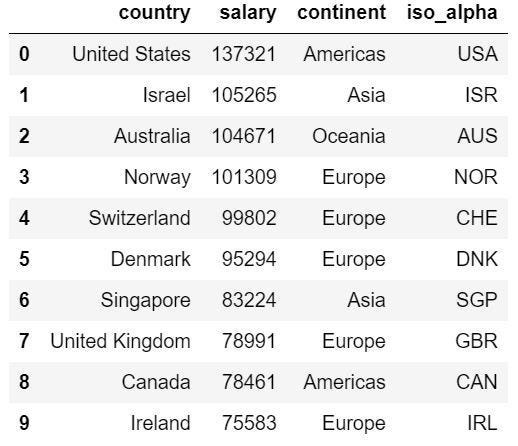
2. 資料視覺化
我們使用plotly套件,針對每個國家的資料科學家平均薪水,繪製出geo圖表。此圖使用圓圈大小以及顏色來比較平均薪水的高低,並且在世界地圖上標上此國家的資料科學家平均薪水比例 (如下影一)。
# 圖表繪製
import plotly.express as px
fig = px.scatter_geo(country_salary_merge_ds, locations="iso_alpha",
size="salary", color="salary", hover_name="country",
projection="natural earth",
title = 'Average Data Scientists Salary For Every Countries')
fig.show()# 自動儲存
pyplt(fig, filename ='Average Data Scientists Salary For Every Countries.html')從上述我們所繪製的圖表中 (影一),可以體驗到plotly的動態圖表功能,我們可以簡單地使用滑鼠滾輪來放大縮小,或是使用鼠標來旋轉地圖,此外當鼠標移動到國家上,就能夠看見這個國家的平均薪資。
藉由實際操作程式碼來繪製圖表,來動手體驗plotly套件的強大繪圖功能吧! 希望您喜歡這次如何成為資料科學家的資料分析及Plotly的繪圖介紹,也可以按個拍手給我一點小鼓勵喔~
我們,下次見!
作者:許喬雅(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究有限公司創辦人)
