在上一篇文章中,「行銷定價新型態:即時動態定價策略與實作」我們主要講到了動態定價能為企業帶來的好處、常見的動態定價方法,甚至是「結構化」結合「非結構化」資料的動態定價Ridge Regression實做。雖然Ridge Regression已經算是線性迴歸改良後強大的預測模型了,但該模型還是被侷限在「線性模型」的框架中並且只有單一的模型對價格做動態調整。
Ridge Regression優缺點簡述:
優點:使用 L2 正規函式,解決過度擬合(Overfitting)及變數間共線性的問題
缺點:缺少非線性數據上的擬合函式,如此便無法最佳化損失函數

Ridge Regression 等線性模型就像是曠野裡獨來獨往的一匹狼/犬(如圖一),雖有「一夫當關,萬夫莫敵」的作戰氣勢,但在大部分的狀況下,仍無法敵過群體作戰來得厲害!
所以本次文章主要嘗試「三個臭皮匠勝過一個諸葛亮」的精神,以「集成模型」(ensemble models)集成/結合多重預測模型於一身,也就是集眾家之所長,面對「即時動態定價」的預測!
談到「集成模型」,相信大家的第一直覺便是「眼熟能詳」,集多種決策樹所造就的隨機森林(Random forest)。 但集成模型中只能使用隨機森林來做即時動態定價的預測嗎? 難道不能使用其他的集成模型? 該如何判斷呢?
這時候就要回歸到在機器學習中最常論及的偏誤與變異(方差)法則(Bias — variance),如果要降低變異,至少要增加資料集、進行損失函數正規化,乃至利用重複抽樣(Resample)的方式執行之;如果要減少偏誤,至少要挑選複雜的模型並加入有用的特徵值(Feature)。
來看看我們在前一篇文章中做了那幾種:
- 資料集:在有限的時間下,已經蒐集148萬電商平台消費者常用的拍賣資料,其資料數量與真實的市場資料足夠減低變異所造成的誤差。尤其是非結構化的文字資料,一旦資料量不足,損失函數便會有明顯的提昇,例如在本資料集,讀者可以嘗試僅拿1萬筆資料以Ridge Regression進行測試,結果會是RMSLE 偏高的狀態(大於0.5以上),相對148萬筆的資料來說,高上非常多。
- 正規化:已在模型中經使用L2正規化函式,儘可能避免過度擬合造成的誤差。
- 特徵值:已經結合結構化與非結構化的數值資料,已然充分表達每一賣家對商品的意見。
- 模型:複雜的模型,尤其是非線性的模型通常能夠造就良好的預測效果。
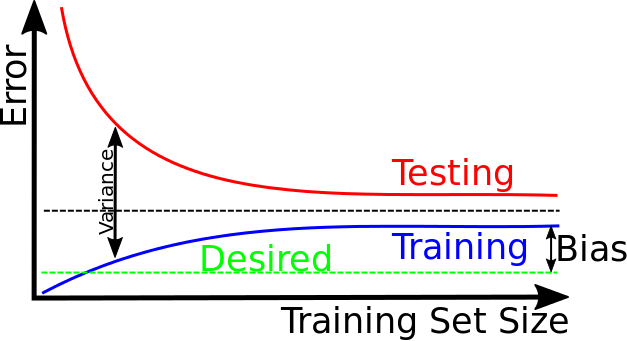
如圖二,當資料集過少時,會發生變異大所造成的誤差,隨著資料集增加且資料內容正確的狀態下,明顯會減少變異所造成的誤差;雖擁龐大且正確的資料集,但要如何優化偏誤所造成的誤差又是一門學問,通常資料科學家會使用複雜的非線性模型,如:集成模型或是深度學習等模型解決偏誤的問題。
基於上述4種準則,在我們面對7萬變數 * 148萬樣本的稀疏矩陣下,就要判斷到底那一種集成模型能夠透過本身的技術來優化偏誤與變異所造成的誤差呢?
就讓我們開始來檢視2001年的隨機森林、2014年被提出的XGBoost 與 2016年被提出的LightGBM,共三種熱門的模型,進而挑選出適合我們分析的模型。
隨機森林
隨機森林的中心思想是「Bagging」方法,它將自身的決策樹獨立出來,並進行重複抽樣的方法,讓每一顆樹都在不同的樣本基底下進行獨立訓練(亦可使用不同特徵值訓練),然後綜合其預測結果,如此便能夠有效降低「變異」所造成的誤差。這就像是戰場上生長環境不同的將軍共同攻打一座城池,且有效從各自經驗的綜整下,打下城池。所以總結來說,隨機森林對於降低變異能達到不錯的效果,但是對於降低偏誤則是有限的。
Boosting
說明 XGBoost 與 LightGBM前,先要解說其中心思想「 Boosting」,除了重複抽樣的技法外,它還將決策樹每個學習到的參數,修正之前決策樹所學習到的偏誤,也就是說,Boosting的決策樹不在是各自獨立學習,而是擁有經驗上的傳承,在一同面對模型的訓練。這就像是戰場上生長環境不同的將軍共同攻打一座城池,且彼此學習攻城經驗,透過經驗傳承與累積,乃至攻城成功,如此作法比起Bagging來說,更像是人與人之間的經驗傳承。所以這樣能夠造就「低偏誤」與「低變異」。在實務上來說,最新的Boosting的方法也易於將其損失函數加入正規化函式,讓變異所造成的誤差更有可控性!總體來說,相較Bagging的方法,我們能說Boosting更勝一籌!(如欲深度了解Boosting與Bagging的比較,可參考這篇論文)。
既然Boosting方法中的 XGBoost 與 LightGBM 都是基於Boosting的方法,那這兩種方法又有何種差異?
XGBoost
全名為Extreme Gradient Boosting,2014年由華盛頓大學的陳天奇所發表,其具靈活且移植性高的特點,進而能有效率且精準的處理我們面臨稀疏矩陣這種接近4900萬維度的資料集。陳天奇與隊友一起贏得了Higgs Machine Learning Challenge後,該演算法便聲名大噪,也有不少的資料科學團隊結合XGBoost到自身的模型後,獲得冠軍。
如欲深入瞭解XGBoost的演算法與調參說明,在此附上2份不錯的參考文:
LightGBM
全名為Light Gradient Boosting Machine,2016年由微軟所發表,為的是解決商業界需要快速建模的需求(Light意指快速),所以該模型的效率相對XGBoost來說都快上2–10倍;記憶體也相對Numpy, Pandas等套件還要來得更加節省,不過這種「空間換時間」的作法也犧牲了一定的準確性。簡而言之,LightGBM就是一種快而輕巧的tree boosting模型。
如欲深入瞭解LightGBM的演算法、直方圖算法與調參說明,在此附上4份不錯的參考文:

如圖三,集成模型有如英雄、美女與劇情電影的完美結合(不同tree boosting模型的結合與傳承),有著創造票房佳績的可能性(降低損失函數數值的可能性)
即時動態定價 2 — Python集成模型實戰去!
簡述完了理論,終於來到了實戰即時動態定價2的集成模型實做,本次實戰主要以有效率的LightGBM進行機器學習,並展現「集成模型2.0」1+1大於2的效果。
有關於資料敘述、預測目的、變數解釋等先導說明,請讀者參考第一篇 — 行銷定價新型態:即時動態定價策略與實做(附實現程式碼),便不在此重述。
集成模型 — LightGBM快速建模
下述是典型的LightGBM建模,以增加訓練速度為例,我們在learning rate特別調高、bagging fraction(每次迭代中,從樣本中抽取多少比例進行訓練)僅挑選0.5與使用7核心訓練,以求快速建模。
訓練後所測試的結果為RMSLE = 0.4519
相對Ridge Regression的 RMSLE 來說還要低上 0.0158(降低了 3.37%)
如果要講求更低的損失函數,建議讀者可以嘗試:
- 將learning rate調低
- bagging fraction調升
- max_bin調高
- 將boosting的方法以dart來嘗試
需要注意的是,為講求精準度,訓練的速度就會變得非常慢,這是讀者要仔細考量的
集成模型 2.0
簡簡單單,我們已經將最基礎的LightGBM完成了! 相信這時候讀者一定又產生一個很直覺的疑問:「那… 能不能來個集成再集成」,也就是不同參數之間的集成模型相互結合,變成「集成模型2.0」?
當然可以!
最簡易方法是:
- 創建不同參數的集成模型。
- 然後將不同集成模型RMSLE的數值高低,以人工或比例分配 1 的權數給予各自的預測值,然後加總。
- 結束!
嗯?! Are you kidding me? 這麼簡單? 沒錯,就是這麼簡單!

集成模型竟然能這麼「簡單」的結合在一起! 真的有效果嗎?!
所以… 集成模型2.0真的有效果嗎? 沒有效果的話,這章節就不會出現啦XD
先讓我們來隨性在創建一個LightGBM模型。結果顯示(如圖四):
訓練後所測試的結果為RMSLE = 0.4637
相對Ridge Regression的 RMSLE 來說還要低上 0.0040(降低了0.85%)
想不到隨性調整參數的集成模型還能超越Ridge Regression,可見LightGBM模型的強大阿!
最後,讓我們將一個Ridge Regression + 兩個LightGBM來進行預測!(哈!真的是三個臭皮匠)看看能不能夠勝過諸葛亮!
很明顯的,將所有模型創接起來後(如圖五):
測試的結果為RMSLE = 0.4428
相對Ridge Regression的 RMSLE 來說還要低上 0.0248(降低了5.31%)
效果相當好! 可見集成模型2.0真的是更有效果!
所以…降低損失函數於商業來說…起到啥作用?
前述我們一直在想辦法降低損失函數,那這件事情對於商業上來說,除了上篇文章提到的「不產生割喉式競爭」外,還有何種意涵?
讀者可以想像,如果這一份資料集包含的均是「已成交」的資料,而非單純的賣家拍賣價格(未成交的價格),對於電商平台可說是意義非凡。言下之意,如果能夠操縱賣家價格與市場銷售價格相似,該產品被銷售掉的機率也就越大,轉換率也會隨之提高。
讓我們以一個假設性案例來說明。首先,讓我們假設以下條件
- 電商平台的每賣出一見商品的抽傭費用=10%(selling_fee)。
- 我們將預測值與真實值相減後取絕對值,然後以log1p的方式轉換之(假設買賣狀態的分配是屬於遞減式遞增的對數分配,以示價錢越低差距約低,越容易購買,差距越大,越不易購買)。
- 而今經濟狀況良好,便以「log1p差距閥值」= 2 為考量(log_selling_threshold),代表log1p轉換出來後的差距值如果低於2的話,消費者就行購買。
- 這僅是一個月的時間資料。
- 最後,拿Ridge regression與集成模型2.0的預測結果來比較吧!
比較的結果發現(如圖六):
使用集成模型2.0的營收有157,032美元 = 新台幣 4,586,890元
使用Ridge regression的營收僅有149,124美元 = 新台幣 4,355,913元
兩者營收差距換算新台幣,竟高達新台幣230,976元
新台幣230,976元!
新台幣230,976元!
新台幣230,976元!
因為很重要,所以說三遍!
讀者在想想,如果這僅是一個月的營收,那一年(如果經濟環境等因素不變的狀況下),就相當於少賺新台幣 2,771,719 元
所以,從實證結果就可以發現為甚麼行銷資料科學家要想辦法以機器學習模型搭配偏誤與變異(方差),產出更低的損失函式數值,以創造企業更高的營收。

再者,從損失函數的角度來看,從Ridge regression轉換到集成模型2.0的 RMSLE 每1%就差了43,484 元新台幣!所以如果讀者以營收的角度來想機器學習及損失函數,就會發現好的模型與低的損失函式數值真的是必不可缺的。
敬請期待! 即時動態定價 — CNN
走筆至此,我相信讀者一定會詢問幾個問題:
問題1:「雖然模型成效不錯!但是這個… 4900萬維度的資料量… 真的很耗電腦效能,而且使用TF-IDF方法的結果會造成維度過大的稀疏矩陣,讓模型非常吃力…也有讀者詢問另一種方法TF-PDF方法或許可以獲得更好的效益?! 但讀者可以跳脫上述思維,想想有沒有更好的特徵值表達法? 例如利用正負向量來表示字詞特徵值? 或者能用GPU來訓練? 亦或者能搭配最近潮到出水的類神經網路來做呢? 」
問題2:「有沒有可能使用XGBoost來做? 跟LightGBM效能差多少? 所費時間? 損失函數表現狀況?」
問題3:「這些集成模型有沒有可能讓我知道,是哪幾個特徵值影響到營收?」
答案是有的! 往後文章將依問題順序,嘗試如何使用 CNN + Pytorch + word embedding建制出即時動態定價的類神經模型、介紹XGBoost與LightGBM的差別以及如何擷取重要特徵值!
往後的文章都會持續在行銷資料科學粉絲專頁上發表喔!
再請大家多多follow我們的粉絲專頁:行銷資料科學
Enjoy Marketing Data Science!
作者:鍾皓軒(臺灣行銷研究有限公司 創辦人)
