到底啥是詞向量? 那跟人類邏輯啥關係?
詞向量(Word Vector)是什麼?
我們首先以簡單的例子來闡述詞向量概念,讓讀者快速進入詞向量的世界!
詞向量概念與釋例:
當有一個句子為:「鍾皓軒喜歡深度學習,而且人很帥,是萬人迷阿!」
當我們提到「鍾皓軒」這人的相似邏輯用詞,便可藉由詞向量模型,找出鍾皓軒這人相似詞為「深度學習」、「帥」、「萬人迷」。
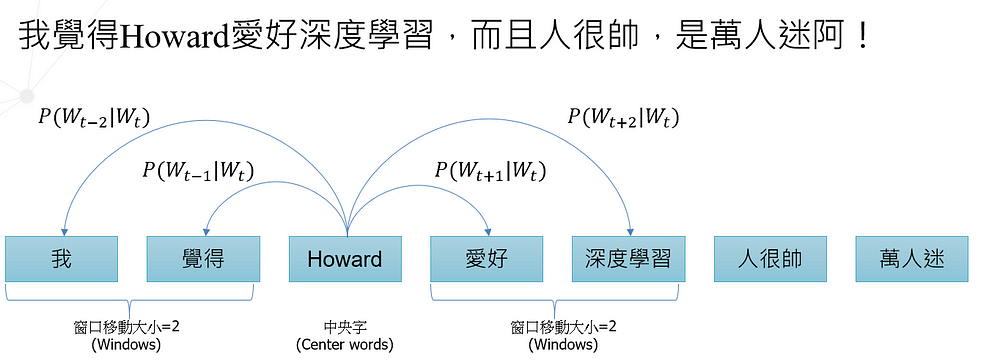
另有一句子為:「我覺得Howard愛好深度學習,而且人很帥,是萬人迷阿!」
這時候模型就會找出鍾皓軒與Howard在「深度學習」、「帥」、「萬人迷」上具有邏輯相似性,於是模型就會告訴我們「鍾皓軒」與「Howard」相似性極高。
從詞向量中抽取人類邏輯性與相似字詞,如何辦到?
一般進行詞向量建模時,會將每個字詞進行切割,變成一個個的字詞(Word),然後字詞在類神經模型中組件成句子,自動學習出句子之間的邏輯性與字詞相關性。
邏輯性,是在人類語言中一種抽象的表達方法,但是我們要建構的量化模型,是無法用抽象的邏輯性來表達的,所以便需要將字詞「邏輯」轉變成數值,對每個字詞嵌入一個個的向量空間(見下圖1範例),而這種方法就是我們稱的「詞向量」(Word Vector),同時這也被稱作「詞嵌入」(Word Embedding)或稱「字詞表示」(Word Representations)。

下面章節開始,會有少量數學來說明詞向量如何建構,如果不想深入了解詞向量如何計算的讀者,可以直接跳到後面的「詞向量的商業應用」章節。

所以… 詞向量具體是怎麼運作的?
接下來,本篇文章將以較數學性的方式來解釋詞向量中常使用的Skip-Gram模型是如何運作的。
Skip-Gram,顧名思義,直接翻譯叫做「跳過圖像化」的解法,也就是以一個中央字詞作為輸入(Wt),來預測它周圍的上下字詞,也就是以Howard為主中央詞起點(跳過中央字),開始預測後面或前面n個上下文字詞,那n個字詞的移動,我們就稱作移動窗口(Windows, 這邊以Wt+n表示移動到中央字以外的幾個字)。
說白點,其實Skip-Gram就是一種「條件機率」在字詞上的應用。
從以下圖2範例來說,讀者可見在Howard這一個字詞的機率條件下,分別計算周遭上下文的字詞機率,進而找出與Howard最適配的字詞。
那… 以類神經模型如何找尋?
我們將詞向量模型最基礎的skip-Gram模型中Naive Softmax到較為進階的Negative sampling方法,帶大家一覽詞向量模型的奧秘。
Naive Softmax
我們先來以Naive Softmax的方法,將每一個做skip-Gram字詞列為獨立的連乘式,形成一損失函數評估式(L),然後會再以W對L進行偏微分,協助類神經模型以梯度降階法(Gradient Descent)找出連乘式中機率連乘後最高的數值。
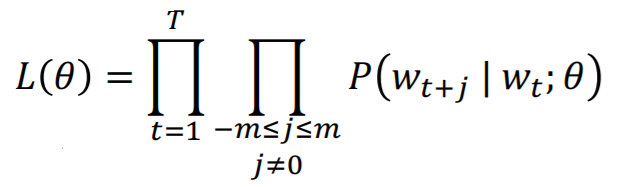
不過,機器學習與資料科學家,總是喜歡將損失函數換個方向,讓他變得好計算且越小越好。為了好計算,可特別取log,將連乘轉換成加總式;而為了將損失函數變成越小越好的形式,則會加上負號,主要因為條件機率取log出來的數值皆為負數,
- 如果是機率是0.9,則log(0.9) = -0.105
- 但如果是機率是0.1,則log(0.1) = -2.3
那直覺上我們當然希望log裡面的機率越大越好,則log外就應該加上負號,原本數值大的log(0.9),就變成損失函數小的數值,那透過Gradient Descent,就可試圖降低log(0.1)的損失函數數值,也就是提高log內的條件機率,找到與中央字(Wt)最匹配上下文的字詞。
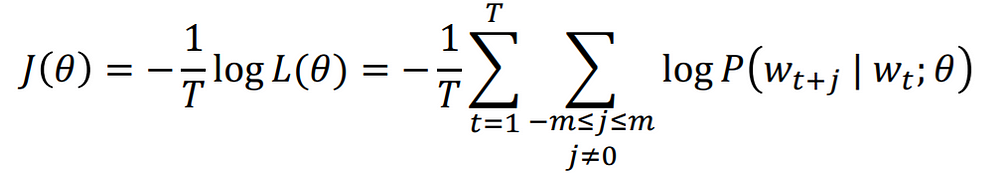
最後針對條件機率P(Wt+j|Wt),使用softmax,會使用softmax的原因主要在於我們想看中央字的詞向量(vc)與其中一個上下文字詞的詞向量(uo)彼此向量內積(下圖分子),對於中央字的詞向量(vc)與所有上下文字詞的詞向量(uw)內積總和後(下圖分母),相除的機率。
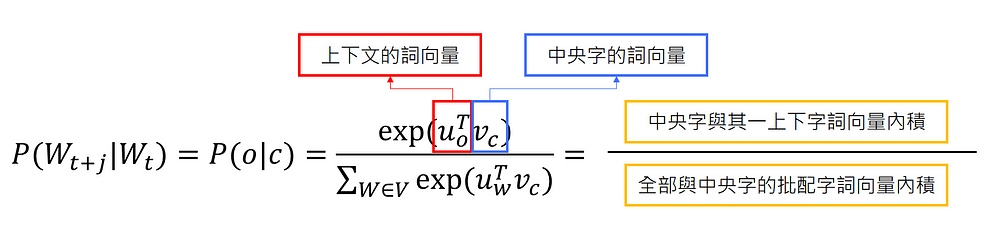
更簡單來說,就是看:
1. 分子:「中央字」與「哪一個上下文字詞」的搭配在
2. 分母:「全部批配字詞中」,機率的大小
機率越大,就代表「中央字」與「該上下文字詞」相關邏輯性越強,也就是「容易一起出現」的概念。
總結以上算法,便是將條件機率P(Wt+j|Wt)裡面計算向量後,套入Softmax中,進而求出「中央字」與最批配「上下文字詞」的機率。這樣的作法我們就稱Naive Softmax法。
但是Naive Softmax法如果套用到百萬甚至千萬字詞的詞集(Corpus),將會耗非常多的運算資源與時間,如果移動窗口(Window size)又設定的特別多,Softmax分母的加總式在計算上也更加吃不消,所以Google的Mikolov大神與其他同事一同在2013年發表了一篇採用Negative Sampling,一種更有效率方法來進行詞向量計算。
如欲更深入且完整了解詞向量的讀者,請參考Mikolov et al. 2013年對於Skip-Gram算法所發表的論文Distributed Representations of Words and Phrases and their Compositionality。
Negative Sampling
基本概念與Naive Softmax及其相似,首先我們在損失函數上一樣看到,主要還是最大化「中央字」與「上下文字詞」的詞向量內積的機率,並最小化「中央字」與「非上下文的隨機字詞」的詞向量內積的機率,如方程式4所示。

Sigmoid function,也是羅吉斯迴歸中使用的函數,本處利用Sigmoid function來計算詞向量內積的機率,如方程式 5所示。
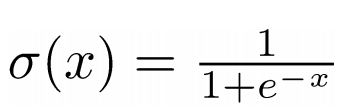
Sigmoid function的input如果加負號,便是如此形式,本處加負號主要是要最小化「中央字」與「隨機字詞」的詞向量內積與機率如方程式6所示。
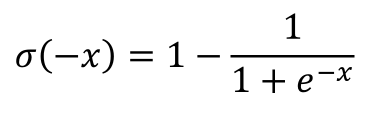
還是聽不太懂嗎?讓我們簡單舉例給您看:
假設中央字與上下文個別的詞向量僅有1x1的維度,且機器學習前的中央字與上下文的詞向量內積是1.21,與隨機字詞的詞向量內積為1.08中央字與上下文一起出現的機率 = 1/(1+np.exp(-1.21)) = 0.77
中央字與隨機字詞一起出現的機率 = 1/(1+np.exp(-1.08)) = 0.74那損失函數的數值就是:
-np.log(1/(1+np.exp(-1.21)))-np.log(1-1/(1+np.exp(-1.08))) = 1.633經訓練,假設中央字與相關上下文的詞向量內積是2.7,與隨機字詞的詞向量內積為0.4
中央字與上下文一起出現的機率 = 1/(1+np.exp(-1.21)) = 0.94
中央字與隨機字詞一起出現的機率 = 1/(1+np.exp(-0.4)) = 0.60那損失函數的數值就是:
-np.log(1/(1+np.exp(-2.7)))-np.log(1-1/(1+np.exp(-0.4))) = 0.848從上述簡例,我們確實可以看到該損失函數在「中央字與上下文的詞向量內積」越大且「中央字與隨機字詞詞向量內積」越小的狀況下,損失函數便會越小。
更簡單來說,Negative Sampling主要在剔除中央字不常出現的「隨機字詞」,然後強化中央字常出現的「上下文」的邏輯關係,更精準找出每一個字詞與上下文的關係。
所以Negative Sampling真的有比較好嗎?
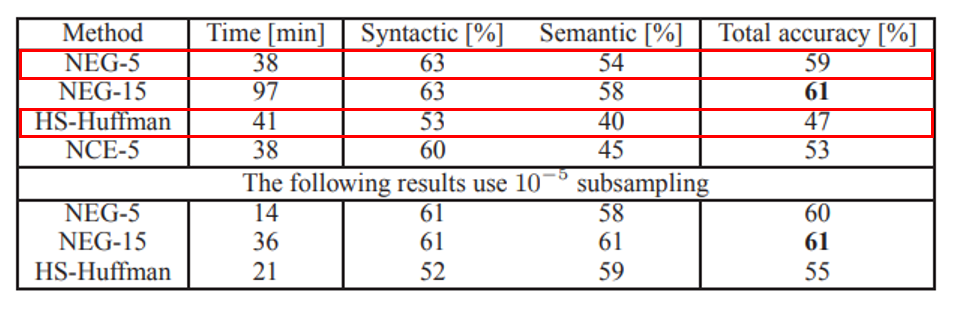
從Mikolov et al. 在2013年在論文中做的實驗中來看,我們看到使用Negative Sampling(NEG-5)與 2005年改良Naive Softmax訓練效率的Hierarchical Softmax(HS-Huffman)的結果而言,Negative Sampling訓練速度更有效率,且準確度、邏輯語意性達更好的效果(如下表1)。
那麼本篇文章就嘗試以Negative Sampling的方法來進行測試。
如何實做詞向量的商業應用?
首先,讓我們先從實做開始!我們先開啟main.py,載入skip_model.py,接著將您自己想要訓練的資料整理成下表2格式。
PS:本次資料雖為臺灣某彩妝平台公開資料,但本次因文章著作權問題不開放給讀者下載,讀者可拿自己的資料來實做。
這是本次文章的Pytorch + Python 3 codes:
PS:類神經模型皆使用Pytorch進行實做,如讀者為Pytorch新手,很建議到yunjey 大神的 github自學 Pytorch 0–1。
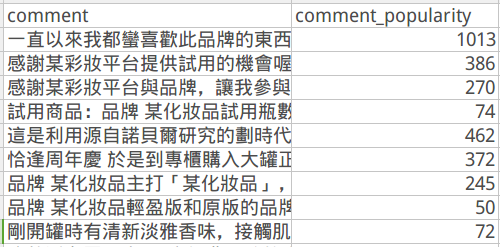
資料欄位解釋:
- comment:評論者對某牌面膜之評論。
- comment_popularity:該評論所帶來的頁面點擊次數。
執行SkipGram function,為skip-Gram訓練前做前處理,如下圖3所示。

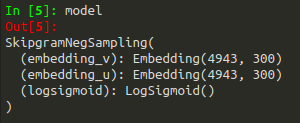
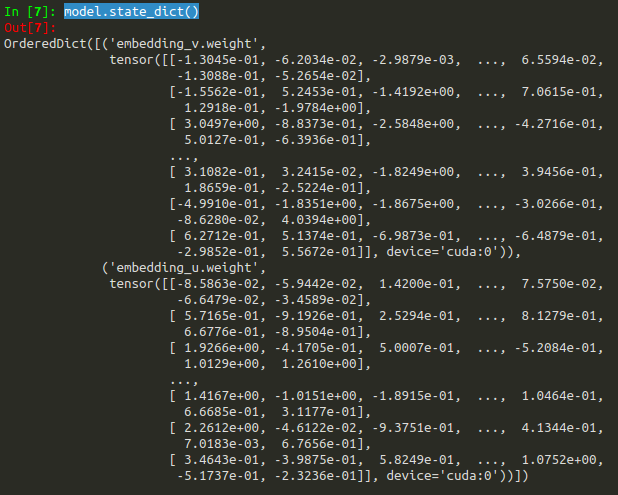
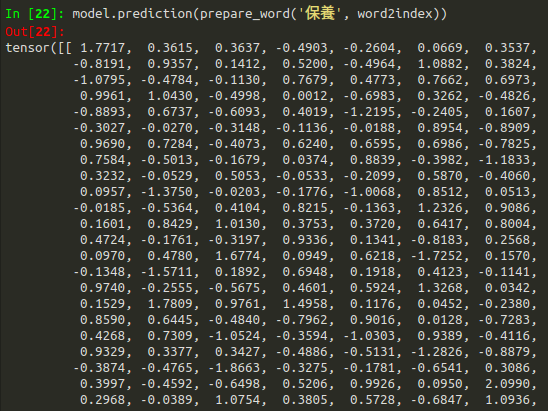
接著在main.py中一路執行到model.state_dict(),就可以看到我們模型中,中央字與上下文詞向量的維度與權重啦!中央字與上下文權重維度為4943 *300,如下圖4所示。
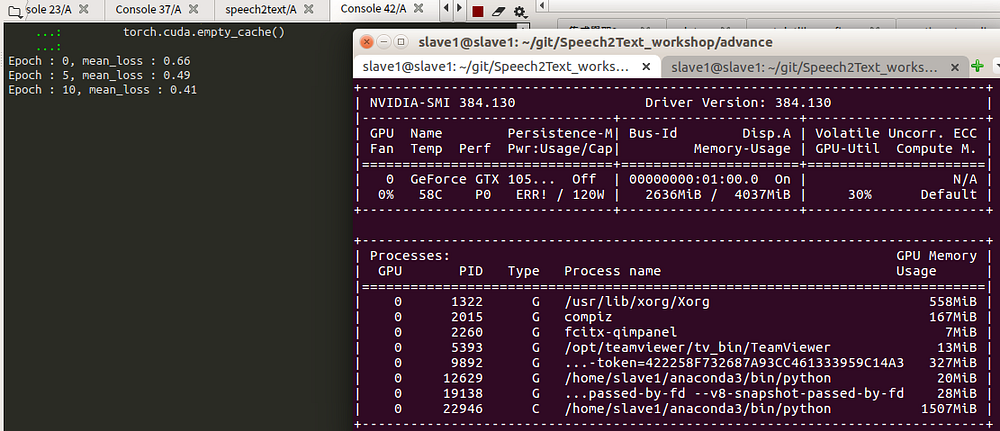
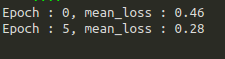
經過training後,強烈建議使用GPU,訓練過程,建議使用GPU運作,否則CPU相對慢5–10倍的速度。最後我們將的損失函數數值落在0.28一個不錯的數值,然後詞向量模型就完成了! 如下圖6所示。
呼~訓練完了!然後呢?
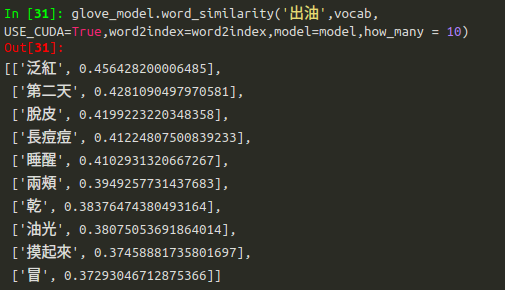
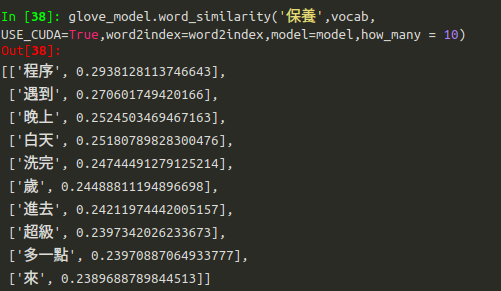
就到關鍵處啦!我們透過其他監督式機器學習模型找出會影響頁面點擊次數的關鍵字 — 「滋潤」與「出油」,便可使用word_similarity function,找出與其邏輯性相似的字詞!每一個字詞都有他的詞向量如下圖8所示。
找出關鍵字的相關性邏輯字詞,以數學上來說,利用cosine similarity(範圍0到1)去尋找每個字詞之間最近的距離,數值越接近0,代表相關性邏輯越強如下圖9所示。
結果很酷,但還是沒回答到商業應用的層面阿?
這時候讀者可以先花個5分鐘想想,如果您是「行銷資料科學家」,千辛萬苦得到了這款面膜的關鍵字詞與上下文字詞的邏輯性之後,您會怎樣應用到商業上?
在實際商業應用上,我們在本篇將闡述3種應用模式:
- 新產品開發之策略
我們來看關鍵字「出油」,這品牌主要都在強打滋潤跟保溼,但產品沒強調的特徵 — 「出油」竟然會影響到頁面點擊次數的高低。我們發現出油的相關性邏輯字詞為「泛紅」、「第二天(隔天)」、「脫皮」、「長痘痘」等。結合面膜知識領域專家(domain knowledge expert)與產品開發者的研討後,這資訊對他們來說是非常重要的情報,主因在於他們更加清楚這些評論者(也就是可能的消費者)特徵具有臉部泛紅、特關心第二天油性肌膚的狀況與脫皮,讓產品開發部與行銷部認知到,他們可將本款面膜用料成份進行細調,便可推出另一款專門針對油性泛紅皮膚的產品,進而滿足自家的消費者對「油性膚質的需求」。 - 行銷宣傳
在行銷宣傳與訴求上,針對「出油」,很清楚的可看出業者們應該往「泛紅」、「隔天的效果」、「改善脫皮」概念出發,直接打中該品牌消費者的特徵,增加產品頁面的點擊次數。 - 找到對的寫手
我們再看對這款產品的關鍵字「保養」。拿到一款面膜,最關鍵的就是如何使用,放到面膜產品,就是如何進行「保養」。在保養方面,我們看到,如「程序、晚上、白天」等關鍵字詞,皆是相關的邏輯性字詞,且透過機器學習判斷出來,對頁面點擊次數具有影響,於是我們就可以從該平台的寫手Pool中抓出適合撰寫這些文章的寫手,增加文章點擊次數。
這樣做…阿是真的有效果喔?
有沒有效果,測試一下就可以知道! 我們結合上述所提的選項2與3 -「找到對的寫手與行銷宣傳」,實際將本次機器學習挑選字詞的方法應用到某一期間的行銷宣傳上,也就是針對關鍵字直接找對應的寫手進行行銷文案宣傳,我們總共提出3種作法比較之:
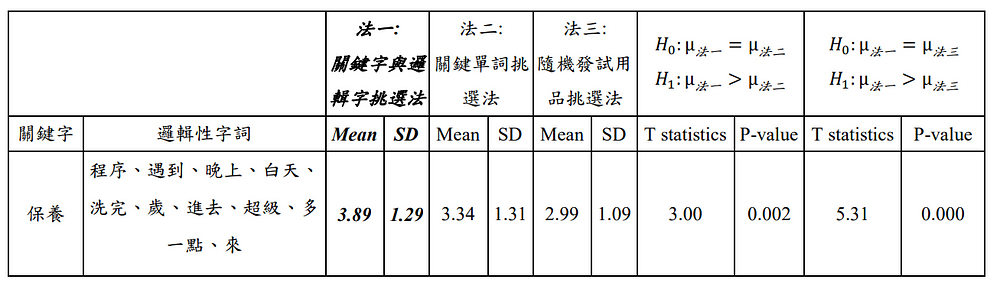
- 方法一:「關鍵字與邏輯字挑選法」來挑選寫手,本法根據提到的關鍵字與其相關的邏輯性字詞找尋寫手,例如:我們上述利用機器學習挑選出「保養」是很重要的因素,那也將該相關的邏輯性字詞-「程序、遇到、白天」等考量進去,挑選寫手。
- 方法二:「關鍵單詞挑選法」來挑選寫手,也就是根據我們使用的監督式學習的機器學習模型選出的單字進行寫手挑選,例如:我們上述利用機器學習挑選出「保養」是很重要的因素,那就依照這個單詞狀況,挑選寫手。
- 方法三:「隨機發試用品挑選法」來挑選寫手,這也是廠商根本在沒有data evidence based狀況下最常做的事情,簡單來說,就是看到誰,就發試用品,看誰來寫…
要做「行銷資料科學」上更嚴謹且嚴格的測試,我們規定所提的方法一的頁面點擊次數分佈要在100次的測試裡面,總共有95次的平均頁面點擊次數是大於方法一與方法二的頁面點擊次數分佈。
以統計術語來說,我們採雙樣本t檢定(採單尾檢定),藉不同方法的樣本平均差進行統計檢定,並假設方法一的成效要顯著大於方法二與方法三(p-value<.05),最後因為評論趨有右偏分佈之狀況,我們又在進行了log transformation,儘量將數值轉換成常態分佈,以便符合雙樣本t檢定常態分佈之基本假設。
結果顯示:
使用法三相較於其他兩法來說,頁面點擊次數顯著要大於其他兩法。如下圖10所示。
看起來是有效果了! 那我最care的營收呢?
由於我們對該品牌頁面點擊次數轉換率不甚清楚… 但還是讓我們來假設一下數字吧!
先來看一下三種方法下,每篇貼文的平均點擊是:
方法一:np.exp(3.89) = 48.910886523731889
方法二:np.exp(3.34) = 28.219126705408609
方法三:np.exp(2.99) = 19.885682491564729讓我們假設點擊轉換率是2%。而這段期間內,每種方法各選擇300個寫手進行行銷宣傳,於是賣出的產品件數各是:
方法一:48.910886523731889 * 0.02 * 100 = 98組面膜
方法二:28.219126705408609 * 0.02 * 100 = 56組面膜
方法三:19.885682491564729 * 0.02 * 100 = 40組面膜每件面膜定價$2,190,這樣營收就是:
方法一:98組面膜 * 2190 = $214,620元新台幣
方法二:56組面膜 * 2190 = $122,640元新台幣
方法三:40組面膜 * 2190 = $87,600元新台幣這時候我們得出幾個結論:
- 方法一(我們提出的方法),比起方法二結合方法三的加總來說,一週內還可以多賺$4,380。
- 方法一(我們提出的方法),比起方法二,一週內還可以多賺$91,980
- 方法一(我們提出的方法),比起方法三,一週內還可以多賺$127,020
- 方法一比較起廠商直覺式的方法三(試用品隨機灑),簡單估算下來,光一個月就可以多賺上$508,080(這還不包含原先時間對頁面點擊次數的累積營收)。
- 方法一節省約23倍人工分析時間,也就是說,方法一完全可一週一次排程自動化(約2–3小時)進行機器學習,更加節省銷分析人員在分析評論與挑選寫手的時間成本(約花2–3天),達到精準行銷與機器學習輔助之真正效果。
- 如果將方法一對不同產品進行分析,有很大的機率可以得出與本面膜產品同樣的效果。
從上述案例,我們可以充分了解
如同我們在有效提昇決策品質─資料導向決策所提,利用詞向量模型(非監督式學習)結合機器學習所預測出來的關鍵字(監督式學習)引導下,所產生的「資料導向決策」相較較「直覺決策」普遍來說還要更好!
讀者可能又有幾個疑問:
- 在預測價格、預測銷售等精準行銷之應用上,有其他用途嗎?
- 我如果想要檢視競爭者與自家產品外部環境狀況,可以使用這種方法嗎?好處是?
- 剛剛文章說的會影響點擊次數的關鍵字如何透過機器學習找尋的?
- 可否作為監督式學習 — 類神經模型輸入變數(input)的特徵值(features)? 讓類神經模型能透過字詞邏輯性的關聯,對損失函數達更快收斂之效果?
- 亦或者讀者還想知道其他想知道的疑問?都可以留言提出喔。
上述疑問,我們都會逐步在行銷資料科學專頁上進行文章發表,如果讀者也特別對上述某一主題有興趣,可以於本文留言或者分享您的見解,我們會考量先行發表該篇文章喔!
作者:鍾皓軒(臺灣行銷研究有限公司 共同創辦人)
參考資料:
