在系列2 — 好奇自己FB的互動性指標嗎?!用Selenium爬蟲-搞定貼文按讚數、留言數、分享數中,我們透過爬取留言數 、讚數、分享數等指標來了解FB粉專的互動情形,然而想要打造絕佳的內容行銷策略,只有這些資訊足夠嗎?
想知道在FB中哪些內容獲得最多回響,以及什麼樣的內容才會吸引人們主動按讚分享嗎?
想收集不同產業的話題,再創造新的發燒熱題嗎?
想藉由FB主流社群平台了解現在時下的流行議題嗎 ?
這一系列的FB爬蟲文章,分享了我們在動態網頁上爬蟲的成果,讓大家了解如何藉由爬取網路資訊,挖掘背後潛在的輿情價值。
而本篇文章將為您介紹如何抓取FB文章內容與文章時間,並從中找出可運用的各項關鍵資訊。
為何「文章內容」及「文章時間」很重要呢?
這些資訊對於企業來說可說是重要的輿情資料,舉例來說:如果企業品牌下有消費者自主創建粉絲團或其他討論區在議論、評價您的品牌與產品使用狀況,相信他們討論的內容對企業來說是相當重要的資產;亦或者消費者們在一個產業類別(如:汽車)的粉絲團內討論不同廠牌的商品。這些意見與看法可以幫助我們更了解消費者的心思,將目標客群描繪的更加清晰,又或者可以作為產品改善、產品開發、產品新議題發想…等的創意來源。
接著就讓我們一同來看看如何操作吧!
文章內容抓取
藉由抓取不同的文章內容可以幫助我們了解什麼樣的主題、用詞能夠獲得較多的按讚、回覆,以及時下消費者在討論些什麼,對於企業的各項經營都是非常重要的參考依據。
上面我們提到粉絲團內的貼文內容可以幫助企業真正的了解消費者對於企業產品的想法,比如:一項新產品推出後在消費者之間的評價如何,或者品牌定位在消費者心中是否與原先企業所設立的定位相同;若是在特定產品類別的粉絲團,甚至可以幫助我們了解競爭對手的品牌定位與消費者對於該品牌的觀點,從中找到市場上豐腴的藍海。
程式解說
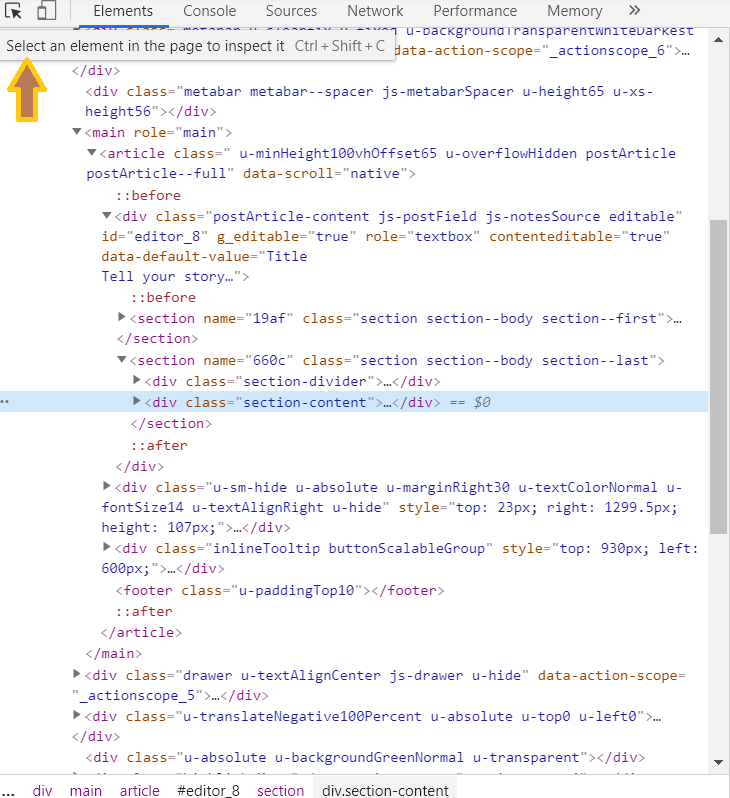
以下我們以教育部粉絲團為例。在進行爬蟲時,我們需要查看網頁內元素以了解該文章的組成內容,按F12或使用crtl + shift+i ,便可以看到以下視窗(圖一),接者點選 左上角滑鼠圖示的選項,並將滑鼠移動到想要抓取的地方,就可以看到該元素的組成囉 !
以教育部這篇文為例,透過此種方法對比之下,就可看到文章內的組成元素(圖二),找到想要的元素後,將Chrome drive 內的網頁元素放入Beautifulsoup 內進行解析,再根據上述兩個步驟查詢到想要的元素並進行提取。
# 將網頁元素放入Beautifulsoup
soup = Soup(driver.page_source,”html.parser”)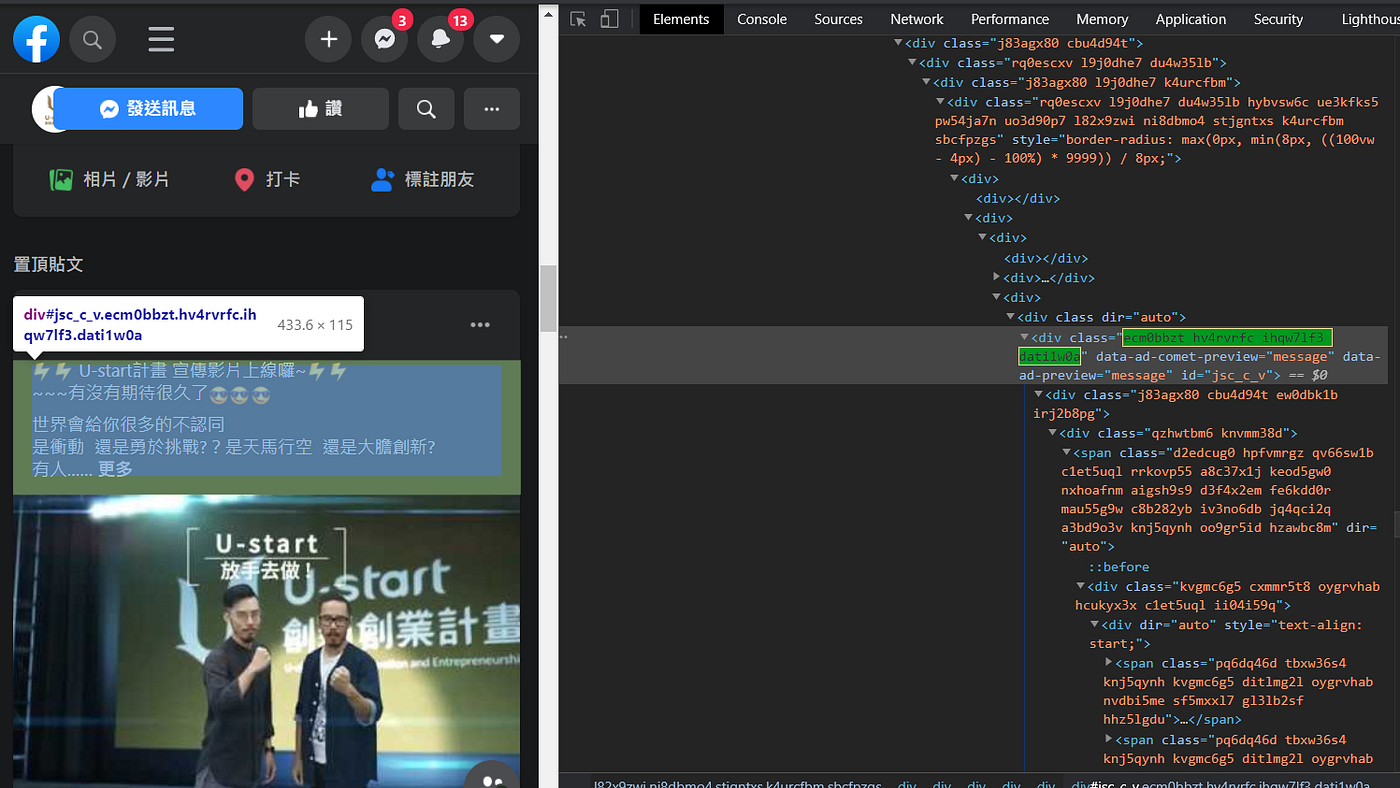
在圖二中可以看到文章的所有文字被包在綠色標籤中,而我們就需將包含著所有文字的網頁元素抓取出來,才可以更進一步的抓取底下的所有文字,如下所示:
網頁元素 :
<div class="ecm0bbzt hv4rvrfc ihqw7lf3 dati1w0a">接者我們就可以使用Beautifulsoup的套件 find 抓取上述所有文字的class name ,並使用.text 就可以將該元素內的所有文字提取出來,也就是該篇文章的文字內容,程式碼如下:
程式碼解說:
使用方法 soup .find(class_ = ‘想抓取元素 的 classname’)
.find : 可以抓取符合的第一個元素
.find_all : 可以抓取所有符合的元素,用法與 find相同
程式碼 :
# 抓取文章內所有文字
soup.find(class_ =’ecm0bbzt hv4rvrfc ihqw7lf3 dati1w0a’).text
文章時間抓取
文章時間可以幫助我們篩選需要的資料,現今網路潮流變遷快速,使得這些高價值的資料具有時效性。
以行銷活動來說,若是我們想了解9月份的行銷活動反應如何,就需抓取9月以後的貼文,又好比Apple每年秋季便會發表新產品,在快接近產品發表會前消費者們便會開始討論起今年的新產品,我們同樣可以從這段期間討論內容中理解消費者的期望與需求。
而抓取往文章時間的作法與文章內容大同小異:
- 查看網頁內元素
- 找到文章時間的class name
- 如果無 class name 或有許多相同的class name 可用屬性定位
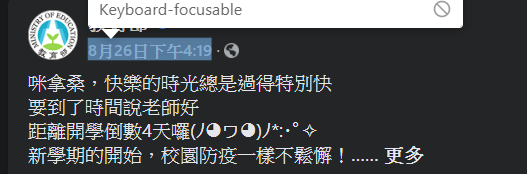
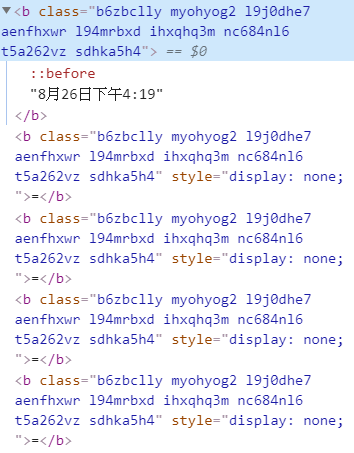
圖五中的元素為時間的class name,但同時也注意到網頁內常常有許多相同的class name,因此藉由此查詢方法是無法達到精準定位的。這時我們必須往上一階層找到位於每篇文章中的時間才有的class name ,以達到精準的定位,圖六中可看到這是每一個文章都有一個時間位置的class name,這就是我們要的元素。
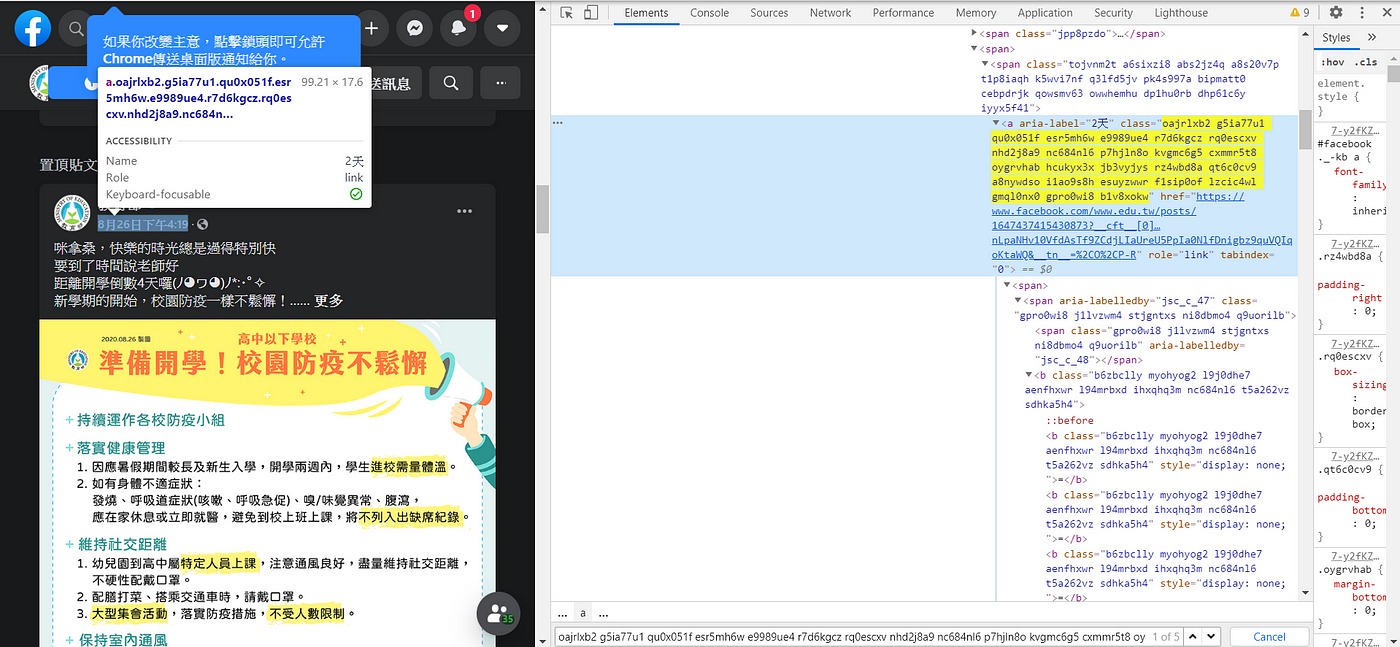
網頁元素:
<a aria-label ="2天" class="oajrlxb2 g5ia77u1 qu0x051f esr5mh6w e9989ue4 r7d6kgcz rq0escxv nhd2j8a9 nc684nl6 p7hjln8o kvgmc6g5 cxmmr5t8 oygrvhab hcukyx3x jb3vyjys rz4wbd8a qt6c0cv9 a8nywdso i1ao9s8h esuyzwwr f1sip0of lzcic4wl gmql0nx0 gpro0wi8 b1v8xokw" href="https://www.facebook.com/www.edu.tw/posts/1647437415430873?__cft__[0]=AZUjZWq8K6YJOhn8500VIHK_-YgS7roPcEmQxfrPrG-rcOB_xlWOKXyOpcOtyHPElmF6MoY8C87XgMPrkw4t8ckixRUrXVTXx-YXFaG1kK1Aik0Vc6azVenLpaNHv10VfdAsTf9ZCdjLIaUreU5PpIa0NlfDnigbz9quVQIqoKtaWQ&__tn__=%2CO%2CP-R" role="link" tabindex="0">程式碼 :
成功提取網頁元素後,便使用 find 進行內容提取,看到這麼長的元素不用害怕,我們要抓取的為網頁下的時間型態為 “ 文字 “,所以透過class name 找到這個元素,再透過 .text 方式取出裡面的文字即可。
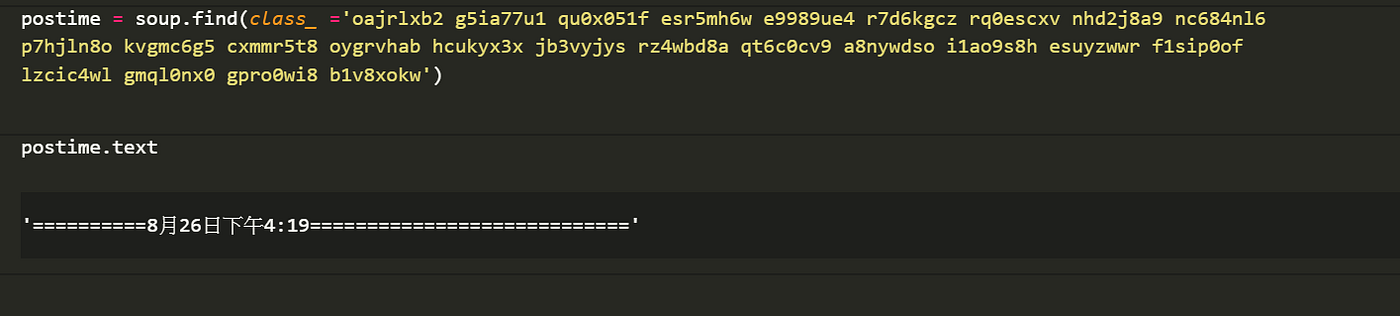
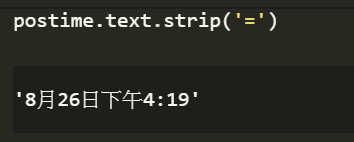
雖然將時間內容抓取出來了,但可以看到在時間上面有了許多的 = ,要將這些多餘的=刪除掉可以使用 .strip,使用方法如下,在括號內輸入想要刪除的符號即可。
我們可以透過爬取的內容搭配時間點及前面文章所提及的讚數、留言數…等。進一步分析消費者們對於什麼樣的文章、題材感興趣,作為行銷活動的發想主軸及文案的撰寫方式及關鍵字詞應用。這次FB爬蟲分享就到這裡告一段落,希望大家都可以順利抓取到自己想要的資料!
作者:陳俊凱(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究有限公司創辦人)
如果這篇文章對您有幫助,就太棒了 ! !
趕快追蹤我們,別錯過後續更多相關的精彩內容~
以下為相關文章連結:
1. FB 爬蟲可以更簡單-用Selenium自動登入FB-系列1(附Python程式碼)
2.好奇自己FB的互動性指標嗎?!用Selenium爬蟲-搞定貼文按讚數、留言數、分享數-系列2(附Python程式碼)
如果在本次系列有不懂的地方,可點擊前往觀看更多爬蟲技巧以及不同社群平台的教學~
