「品酒」已經不再是有錢人的權利,在這個美酒當道的年代,我們要如何像 Somm 電影的品酒師,一口就能辨別出「口感」、「年份」、「產地」,甚至預測下一季爆款的酒呢?
情境:

這時候,機器學習與深度學習都是相當好的辦法,但我們要成為好的品酒工程師之前,我們必須學會理解「數據來源」、「產業知識」、「演算法背後的機制」。更多細節與概念,歡迎參考我們過往寫過的文章 — 《猜猜這瓶紅酒多少錢─使用機器學習來做價格預測》。
因此今天筆者會用 Python 來教大家探索性資料分析 (Exploratory Data Analysis ) 的方法,協助讀者可以慢慢接觸上述三種觀念。
Background 小知識時間:
何謂「探索式資料分析」?
探索性資料分析是利用資料視覺化或統計專業等等的方法,來對原始數據集進行理解,有助於後續的假說建立、數據清理 (Data Mining)、模型建置等等。
而深度學習是機器學習的一個分支,較擅長處理影像、圖片與文字的特徵,
像是近期流行的口罩辨識系統、語音辨識功能、網路輿情分析等等,如果有興趣的讀者可以去看看背後的知識與技術應用,文章底下有延伸閱讀可以參考。
任務:
這次會以學習 Python 畫圖工具 pandas, matplotlib, seaborn 為主要內容,並透過 Wine Enthusiast 這個網站的評論數據集,幫助我們做 EDA 的流程,最後也會分享深度學習中的 TextBlob 應用。
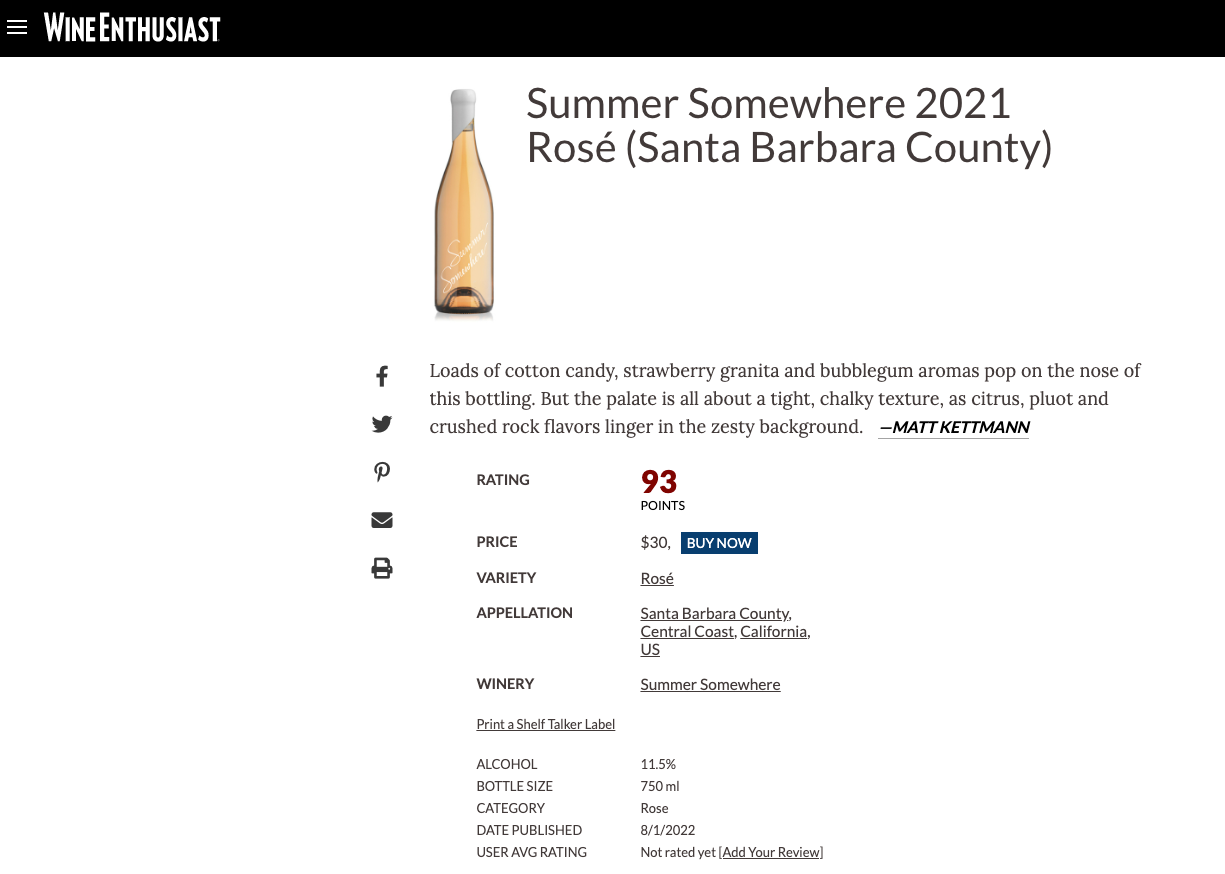
(以下是 Wine Enthusiast 中的一則評論中,可以簡單看出評論內有分數、產地、價格等等的資訊,例如:這瓶酒的分數落在93分、價格是$30美金、酒精濃度是 11.5%,這些資訊都能協助我們後續的預測趨勢。)
預期成效:
藉由 EDA 快速了解數據集以及酒類的相關資訊,並透過 TextBlob 應用去分析評論,最後得到可以辨別葡萄顏色跟甜度的模型。
應用
首先我們必須利用 Kaggle 去了解我們的首要目標與 Dataset 的輪廓,因此看看其他 Kaggle 大神是如何分析也是相當重要的一個過程,有利我們後續的 EDA。
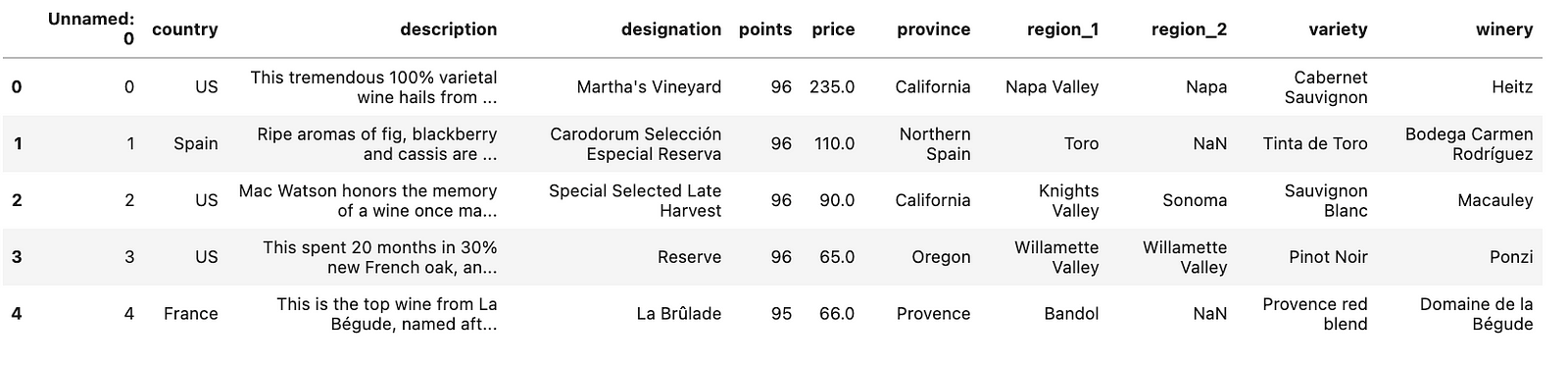
來到 Dataset 我們可以看到由左至右,分別是國家、酒品說明、葡萄的來源、分數、價格、省(酒品產地)、地區 1 、地區 2、酒廠等等。

理解數據集的長相以後,就可以開始透過 Python 畫圖工具,幫助我們快速了解整體的框架與輪廓。
Python 畫圖工具
Pandas basic plot functions:
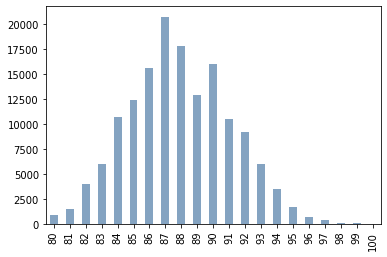
這張 Bar Plot 讓我們知道分數的落點,圖中顯示是 80–100 這個區間。
df_original['points'].value_counts().sort_index().plot.bar(color=(0.2, 0.4, 0.6, 0.6))
matplotlib:
我們也可以透過 matplotlib 並增加 圖片尺寸(figsize) 跟 文字大小(fontsize)來優化我們圖。
import matplotlib as mlt #Using Matplotlib: Change the title fontsize
plot01 = df_original['points'].value_counts().sort_index().plot.bar( figsize = (14,8), fontsize = 16, color=(0.1, 0.3, 0.5, 0.7))
plot01.set_title("Counts of the Wine Points", fontsize = 18)
plot01.set_xlabel("Points", fontsize = 18)
plot01.set_ylabel("Count", fontsize = 18)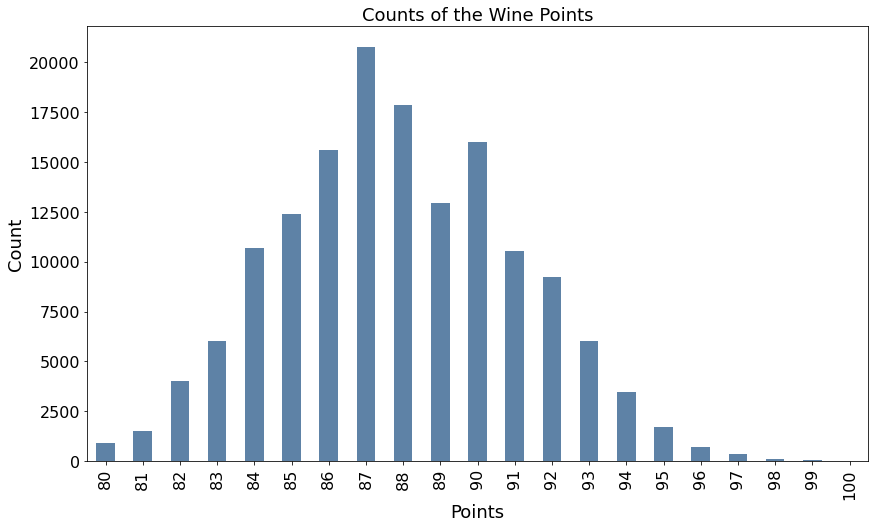
Seaborn packages
如果需要更複雜的圖表可以透過 Seaborn 來協助完成,像是以下就是展示四個國家酒類分數的分佈比例。
import seaborn as sns# Extract wine scores from two countries US and Francedf = df_original[df_original['country'].isin(['US','France', 'Canada', 'Spain'])]g = sns.FacetGrid(df, col = "country", col_wrap = 2)
g.map(sns.kdeplot, "points")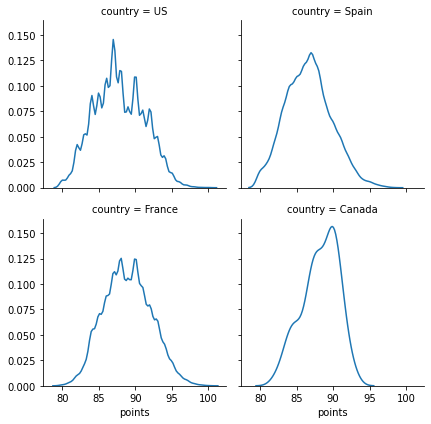
上圖可得知加拿大的酒品分數集中於90分,遠遠超越其他三個國家的比例。
結論:
EDA 我們得到的 points:
- 酒類的評論分數落在 80–100 之間,很少低於或高於這個區域。
- 80% 的酒品分數皆在 83–93 這個區間。
- 四個國家的評論分數的眾數都是 85–92 分。
- 唯有加拿大(Canada) 有更高比例的集中於 90 分的位置。
- 我們可以得知「國家」對於「酒品的分數」有一定的影響力。
透過以上 EDA 的流程能幫助數據工程師更好的理解數據、產業知識,有利後續的顧客溝通與需求的定義,因此 EDA 其實是相當重要的一環。
後續文章預告:
筆者想分享 Python TextBlob 套件能讓我們利用 NLP(Natural language processing)辨識文字評論與情緒,最後達到「分辨不同酒品中葡萄的顏色與甜度」的模型。
以下是辨別紅白酒的結果,主要是透過 Textbolb 去 Parse 重要的文字,再透過領域知識與演算法,來計算出分數,並定義出最終的結果。
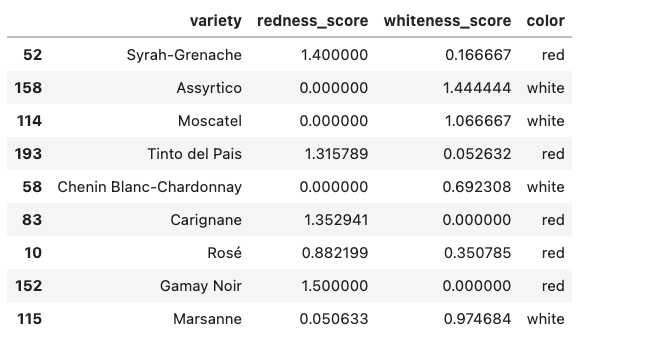
Python TextBlob 更多可以應用的情境:
也可以應用機器學習中的預測與分類的方法,去辨別酒品的好壞,甚至預測新品的分數。
舉例:
- 名詞短語提取(Noun phrase extraction)
- 詞性標記(Part-of-speech tagging)
- 情緒分析(Sentiment analysis)
- 分類(樸素貝葉斯,決策樹)
- 標記化(將文字拆分為單詞和句子)
- 單詞和短語頻率(Word and phrase frequencies)
作者:黃榮晟(臺灣行銷研究特邀作者)、劉加德(臺灣行銷研究特邀編審)、鍾皓軒(臺灣行銷研究有限公司創辦人)
如果喜歡筆者的文章,歡迎拍手跟訂閱讓我們知道。
詳細的程式碼可以參考以下:
補充的 EDA 文章:
EDA for Machine Learning | Exploratory Data Analysis in Python (analyticsvidhya.com)
顧客資料透視(一部曲)-互動式表格【附Python程式碼】. 資料視覺化 (Data… | by 行銷資料科學 | Marketingdatascience | Medium
自然語言處理 (NLP) 與 TextBolb 套件資訊:
TextBlob: Simplified Text Processing — TextBlob 0.16.0 documentation
人工智慧與機器學習-行銷資料科學家必備技能之一. 在第一篇文章當中,我們提到人工智慧(Artificial… | by 李蓓儒 | Marketingdatascience | Medium
參考資料:
wine-deep-learning/README.md at master · zackthoutt/wine-deep-learning · GitHub
