常有在使用 Netflix 看自己有興趣的影集、動漫或者是電影嗎?
是不是常常收到一些你可能有興趣的影片呢?
好奇 Netflix 背後是怎麼推薦你新的影片嗎?

購物籃分析 v.s 矩陣分解分析 兩個核心內容哪裡不同呢?
購物籃分析:
以「產品」為核心,舉例:大家耳熟能詳「啤酒與尿布」例子,去超市買尿布的新手父親,會順便買幾瓶啤酒,因此將兩個產品擺在一起增加銷量。
矩陣分解分析:
以「消費者」為核心,舉例:Netflix 針對「每個不同使用者」曾經觀看過的影片去分析後,製造一份專屬的推薦影片清單,好讓使用者繼續訂閱 Netflix 觀看下去!
本次系列文章將會跟各位分享 Netflix 推薦影片系統的核心套件如何運用在商務資料結構上
情境主題概要說明:
1. 資料來源:以某零售商品平台的匿名銷售資料。
2. 數據筆數:2016~2019年的資料,筆數大約30萬筆資料。
3. 如何分析:使用spotlight-master套件,根據消費者的購買商品情況去預測未來「該消費者」會對哪些產品較有興趣且替公司帶來較多利潤,並按照預測利潤大小的順序給予產品推薦。
4. 如何呈現:將會針對「每個消費者」列出一份專屬的推薦產品清單。
在執行核心程式碼前,都必須得安裝且引入我們所需要使用的套件,然而本次套件安裝較複雜,為了避免大家之後在引入套件時失敗的問題,以下跟各位示範如何處理!
(一)預先處理步驟
Step 1 : 點擊此鏈結前往下載環境套件檔案(spotlight-master)。
Step 2 : 將環境套件放置在大家之後要執行程式碼的同一個資料夾中,如圖2示範。
Step 3 : 開啟程式碼檔案 改變執行資料夾的位置,如圖3示範。

Step 4 : 確認是否成功引入套件,如圖4示範。

此處若在引入「torch」套件失敗的朋友們,可能是尚未下載 Visual C++的原因,可以點擊鏈結前往下載。
以上就完成預先處理步驟了唷!接下來就開始進入資料結構處理的內容吧!
(二)資料結構處理
首先,使用 pandas 套件的功能將本次將使用的商務資料sales_data.csv(點擊鏈結下載檔案)讀取進來,如程式碼1所示。
程式碼1:
data = pd.read_csv('sales_data.csv')產出如圖5:
「sales_data.csv」內容,如圖5所示。
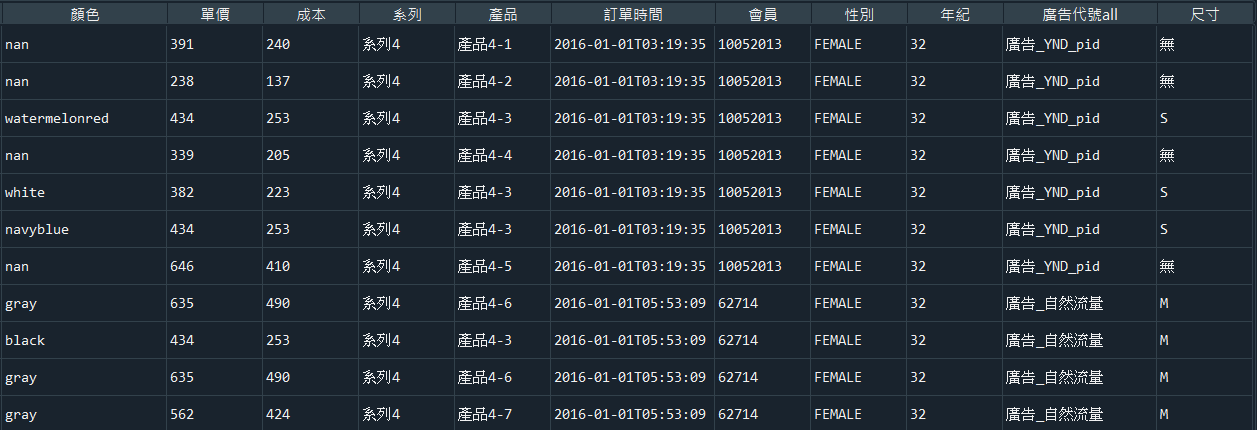
大家可以檢查看看讀取進來後的資料是不是少了一個非常關鍵的欄位(column)呢?
沒錯!就是「利潤」!
現在我們利用讀取進來的資料中的單價欄位減去成本欄位將會得到非常核心的欄位「利潤」,並且只取出接下來會使用到的欄位,如程式碼2所示。
取出欄位意義說明:
- 會員:未來將會針對每個會員的消費紀錄分析。
- 利潤:關鍵的分析要素,判斷優先推薦產品的指標。
- 產品:分析後所要推薦的產品。
- 訂單時間:擷取所要分析的資料時間區段。
程式碼2:
# 新增利潤
data['利潤'] = data['單價'] - data['成本']
# 取出所需的資料內容
data_new = data[['會員','利潤','產品','訂單時間']]
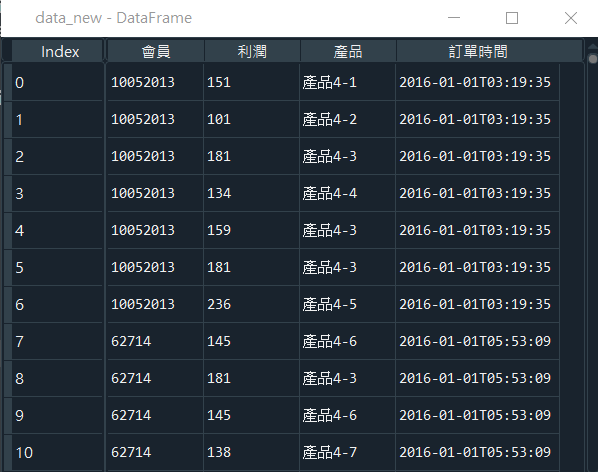
產出如圖6:
已經取好所需欄位的資料集(data_new),如圖6所示。
進行矩陣分解的方法的前提:
要將資料的形式轉換成套件能夠執行的形式(包括欄位名稱)。
套件所需形式為三個欄位的資料集,欄位分別的名稱為「user」、「rating」以及「item」,因此我們先將欄位名稱更改為與套件所需的相對應名稱,如程式碼3所示。
程式碼3:
# 對應之後function相對名稱
# 會員:user 、 利潤:rating 、 產品:item
data_new.columns = ['user' , 'rating' , 'item','訂單時間']
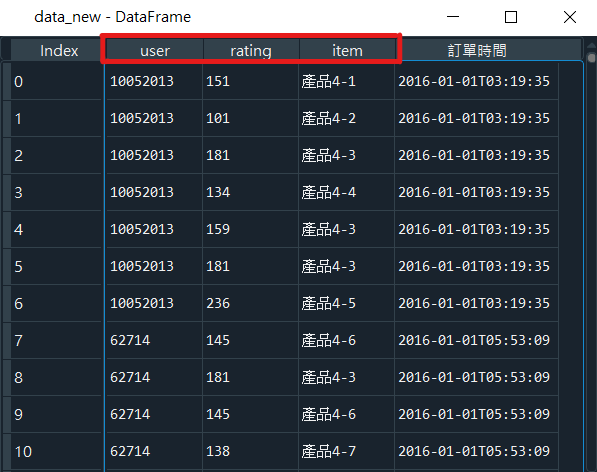
產出如圖7:
更改欄位名稱後的資料集(data_new),如圖7所示。
大家是否疑惑為何訂單時間的欄位還沒派上用場呢?
不用擔心,現在就要來擷取所要分析的時間區段囉!
由於原始資料中的訂單時間欄位資料中有多了一個"T"的英文字母,無法將內容轉成 datetime 形式供我們擷取時間區段內的資料,所以接下來把字母去掉後,將「訂單時間」的內容轉換成 datetime 形式,如程式碼4所示。
程式碼4:
# 把訂單時間中的 "T" 去掉
data_new['訂單時間'] = data_new['訂單時間'].str.replace('T',' ')
# 將訂單時間改成datetime形式
data_new['訂單時間'] = pd.to_datetime(data_new['訂單時間'])
產出如圖8:
訂單時間成功轉換成datetime形式後的資料集(data_new),如圖8所示。
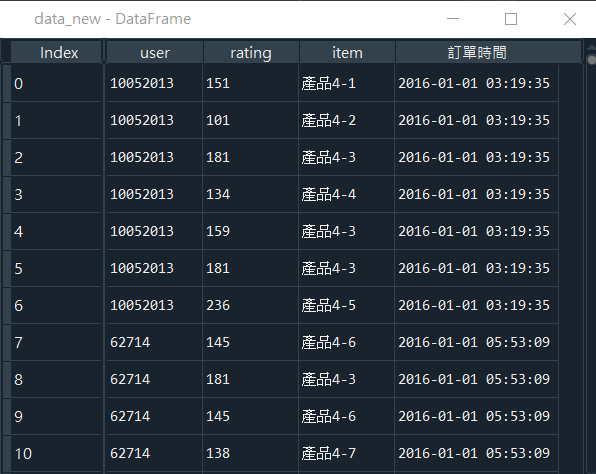
調整完欄位型態後就要開始設立時間區段的起始時間以及結束時間,才能使後續的資料成功擷取,本次分析所擷取的時段為2019年1月1日0時0分0秒到2019年11月1日0時0分0秒(24小時制),如程式碼5所示。
程式碼5:
# 設立選取資料起始時間 (2019年 1月 1日)
begin = datetime(2019, 1, 1)
# 設立選取資料結束時間 (2019年 11月 1日)
end = datetime(2019, 11, 1)
產出如圖9:
起始時間與結束時間的型態與內容,如圖9所示。

接下來將使用上述設定好的條件(2019年1月1日0時0分0秒到2019年11月1日0時0分0秒)把資料擷取出來。因為後續不會再使用到訂單時間的欄位,擷取完後再將該欄位刪除,如程式碼6所示。
程式碼6:
# 選取資料 ( 結束時間之前 )
data_new = data_new[data_new['訂單時間'] <= end]
# 選取資料 ( 開始時間之後 )
data_new = data_new [data_new ['訂單時間'] >= begin]
del data_new['訂單時間']
產出如圖10:
2019年1月1日到2019年11月1日的資料集(data_new),如圖10所示。
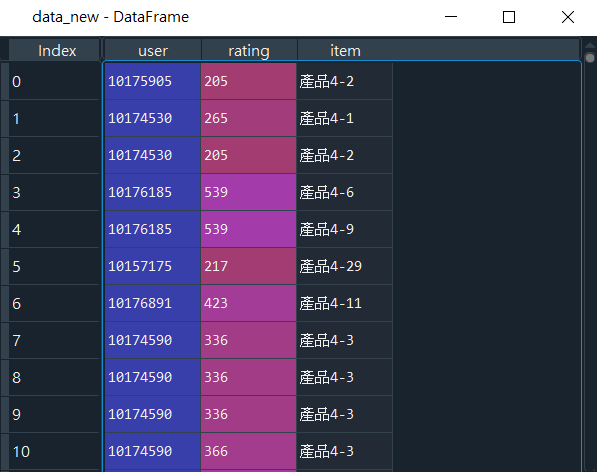
目前我們已經將後續分析所要求的資料內容已經整理好80%囉!
那剩下的20%是甚麼呢?那就是替每個產品以及會員進行編號!
是不是心中有個疑問:「會員跟產品不是已經都有各自的專屬名稱了嗎?為何還要特別再編號一次呢?」
(三)編號方式
讓我來向大家說明,由於之後分析模型的運算過程中只會認數字,因此產品的名稱要重新以0開始編號起,然而會員也是數字,卻也要編號的原因是:分析模型中會進行欄位的交互分析,電腦運算的判定會將會員編號「10175905」誤判為第10175905個會員,這樣會導致整個交互分析的量會相當地龐大,電腦在跑模型時會負荷不來!!
解決問題的方法一樣是重新以0開始編號,接下來就要將會員(user)的欄位和產品(item)的欄位改為重新編號的狀態。
現在要將產品重新編號(欄位名稱:item_id)並且建立一個與原本產品相對應的對照表清單(舉例:產品4–2對應到0、產品4–1對應到1、產品4–6對應到3),並將清單輸出成一個名為 pd_index 的csv檔案,如程式碼7所示。
程式碼7:
# 建立產品id清單
pd_index = pd.DataFrame({'item':data_new['item'].unique().tolist()})
pd_index['item_id'] = pd_index.index
pd_index.to_csv('pd_index.csv',index=False,encoding='utf-8-sig')
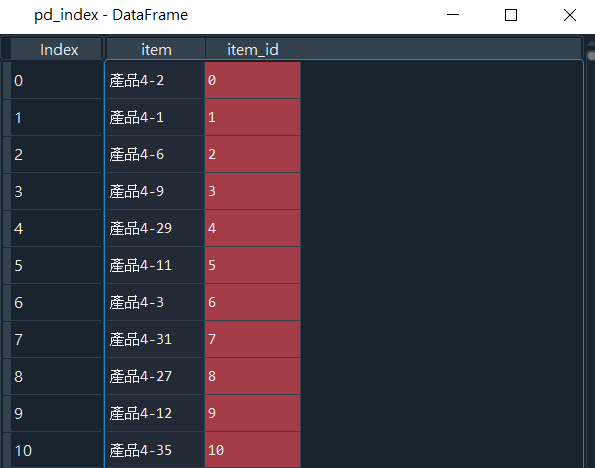
產出如圖11:
「產品」相對應的對照表清單,如圖11所示。
以下也是與產品清單一樣的操作方式,將會員重新編號(欄位名稱:user_id),並且建立一個與原本會員相對應的對照表清單(舉例:編號10175905對應到0、編號10174530對應到1、產品10176185對應到3),並將清單輸出一個名為 user_index 的csv檔案,如程式碼8所示。
程式碼8:
# 建立會員id清單
user_index = pd.DataFrame({'user':data_new['user'].unique().tolist()})
user_index['user_id'] = user_index.index
user_index.to_csv('user_index.csv',index=False)
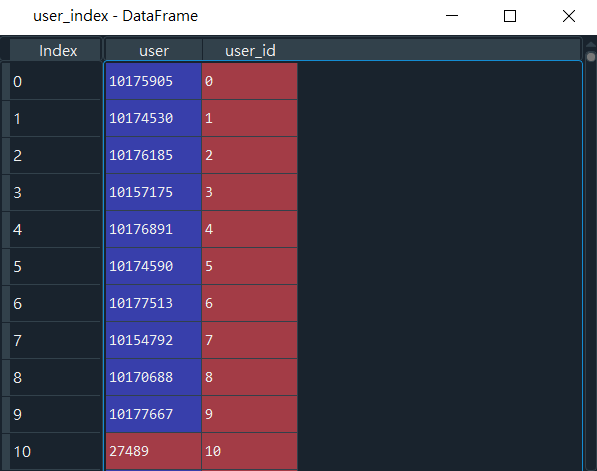
產出如圖12:
「會員」相對應的對照表清單,如圖12所示。
透過前兩個步驟將清單都整理好之後,即可使用 merge 的方式,依照清單上相對應的編號新增在尚未重新編號欄位內容的資料集(data_new)中,如程式碼9所示。
程式碼9:
# merge到data_new上
data_new = pd.merge(data_new,pd_index, on = ['item'], how='left')
data_new = pd.merge(data_new,user_index, on = ['user'], how='left')
產出如圖13:
已結合重新編號後欄位(item_id、user_id)的資料集(data_new),如圖13所示。
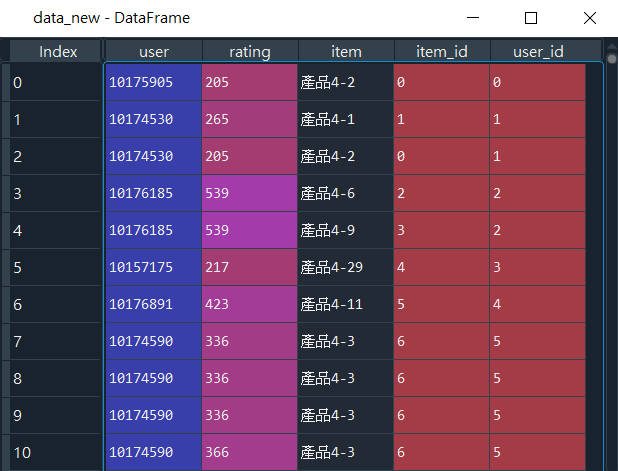
最後!我們將分析模型所需要的資料型態的內容取出來,欄位名稱分別為「rating、user_id、item_id」,並且把資料集取名為data_core,同時也輸出成一份csv檔,如程式碼10所示。
程式碼10:
# 分析模型所需資料集型態 - data_core
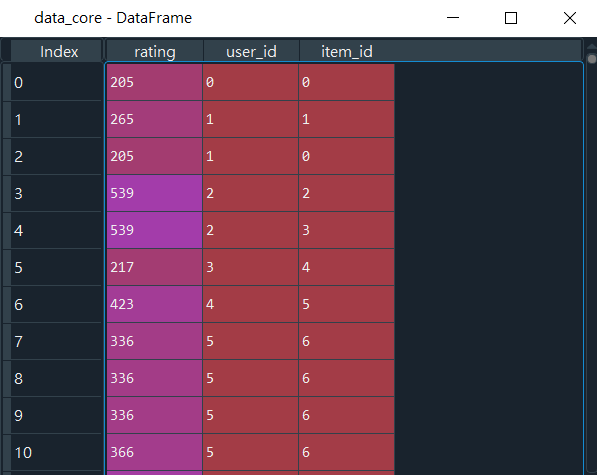
data_core = data_new[['rating','user_id','item_id']]
data_core.to_csv('data_core.csv',index=False)
產出如圖14:
矩陣分解分析模型所需資料集(data_core),如圖14所示。
恭喜大家都完成到這一步,以上步驟已經將商務資料結構都處理完成了!給自己一個拍手!如果覺得這篇文章有帶給您收穫也請給我一些拍手(頁面左側有拍手icon)~
下一篇文章將會和各位分享如何運用本篇整理好的商務資料集透過「矩陣分解模型」運行出來的結果,可以針對「每位消費者」推薦其有興趣且對公司有最大利益的產品,使公司的利益最大化!
想要了解上述所說得的內容嗎?請記得給我拍手,讓我們有無窮的動力!
請點擊下方系列文章連結了解更多!
Thinking smarter makes you work smarter!
如果你喜歡我的文章的話,請給我一點拍手~
如果想要知道更多相關知識的話,follow 我~
程式碼:矩陣分解推薦系統 — Python實戰:商務資料結構整理
作者:張友志 (臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究有限公司創辦人)
