此為系列文第三篇
點此回顧 _第一篇:掌握投資關鍵消息! 從當日熱門新聞預測股票走勢(基本資料處理篇)(附Python程式碼)
點此回顧 _第二篇:透過機器學習預測股市漲跌-進階資料處理

前情提要
在第一篇系列文中,我們對原始資料做了以下五點處理:
- 將所有字母轉為小寫
- 刪除數字、標點符號
- 去除英文字母
- 去除停用詞
- 詞幹提取與詞形還原
接著,在第二篇系列文進行了更進階的資料處理,分別為:
- 還原縮寫字詞
- 運用 TfidfVectorizer 套件解決片語以及連續出現時有特殊含義的字詞
在完成上述之資料處理後,便可以開始建立機器學習模型,而本篇將運用到Logistic Regression、 Random Forest、 Naive Bayes 這三個模型來進行道瓊工業指數的漲跌預測。
查看處理後資料
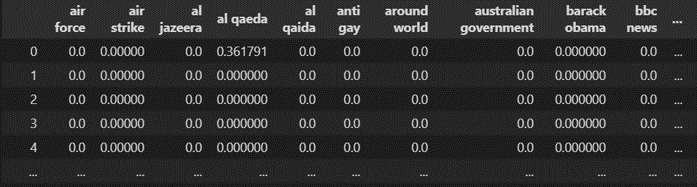
在進入模型簡介與建模流程前,讓我們先來回顧一下上篇文章所處理後的資料,如圖一所示:
模型建置流程
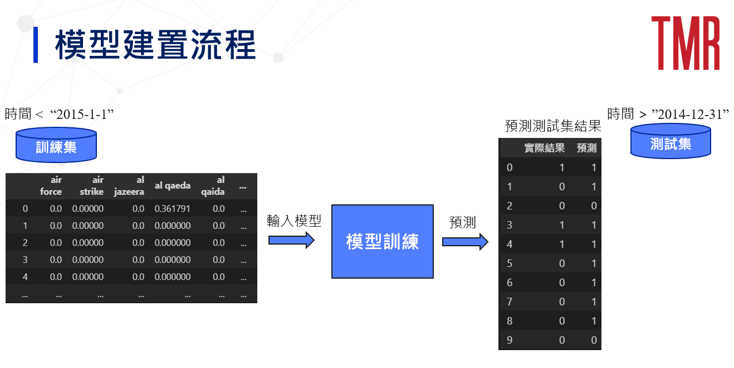
圖二為本篇模型建置之流程,一開始會切分訓練集以及測試集,時間以 2015–1–1為劃分點,接著藉由系列2之資料處理後,就可以進入模型訓練,而最後會利用測試集的資料來進行漲跌的預測。
模型簡介
在此會分別簡介三個模型,藉此協助讀者對將應用之模型建立基礎的概念。
Logistic Regression模型
下述我們先從 Logistic Regression 的簡介入手,讓讀者了解箇中意涵與相關釋例。
Logistic Regression簡介
Logistic Regression 常被用在分類上,像是預測股票漲跌、明日是否下雨等,當我們在預測是否下雨這類的問題時,會以機率的方式作為判斷依據,例如根據現有資料,預測明日約90%的機率會下雨,由於機率介於0%~100%之間,所以不會有超出100%的機率發生(不會預測出150%會下雨的機率)。
將上述觀念套用到 Logistic Regression 上,其是用來解決分類的問題,因此就需要以機率的方式作為輸出,而 Logistic Regression 則透過 sigmoid 函數將結果轉換為機率,讓輸出值介於0~1之間,公式如圖一所示,若想更進一步了解 Logistic Regression 請點此。

Logistic Regression舉例
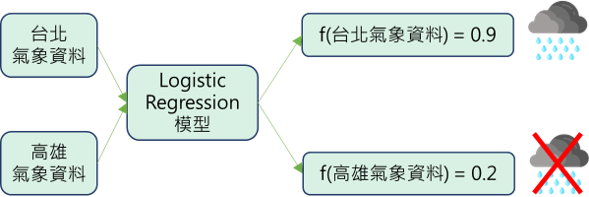
假設我們有台北、高雄今日的氣象資料,像是濕度、風向等等,也有一個可以預測明日是否下雨的 Logistic Regression 模型,如圖四所示。可以看到在經由模型後,台北的輸出值為0.9,所以模型預測台北會下雨的機率就越高;高雄的輸出值為0.2,所以模型預測高雄不會下雨的機率就越高。
Random Forest模型
緊接著來到 Random Forest 的簡介及舉例。
Random Forest簡介
Forest 顧名思義就是森林,而很多棵樹聚集在一起就可以組成森林,在機器學習方面,這些樹就是決策樹,如此聚集的行為,又可稱為集成學習(Ensemble learning),也就是透過結合多個弱學習器(樹),來產生出一個強學習器(森林)。
建立Random Forest的方法是 Bagging(Bootstrap Aggregation):首先,隨機從訓練集中取 K 個樣本,每次取出樣本後皆會放回母體,接著利用取出的 K 個樣本來訓練出 K 個分類器(樹),由於是隨機取樣且取出後會放回的形式,所以訓練出的分類器之間就具有差異性,也不容易發生過擬合,而最後則以多數決的方式,來決定分類結果,若想更進一步了解 Random Forest 的詳細理論,請參考此連結。
Random Forest舉例
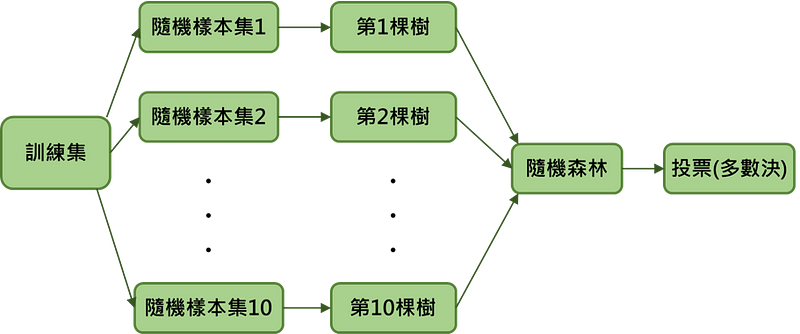
接下來讓我們用一個例子來看看隨機森林建立的過程,如圖五所示:
假設小明今天有100筆客戶的資料,他想利用隨機森林來預測客戶是否購買產品,首先,他先將資料集切成訓練集以及測試集,接著每次抽樣會從訓練集中抽出10筆資料(取後放回),共抽取10次,也就是會建立10棵樹,利用這10棵樹就可以建立隨機森林,而最後預測客戶是否購買產品的結果則由這10棵樹投票決定。
Naive Bayes
最後來到第三個模型 –「Naive Bayes」的簡介及舉例。
Naive Bayes簡介
Naive Bayes 是基於貝氏定理(Bayes’ theorem)以及假設變數之間相互獨立所建立的分類器,常被應用在文字分類領域,例如:垃圾郵件的分類、釣魚網站檢測等。
貝氏定理描述在已知的條件下,某事件的發生機率,舉例來說,假設要判斷病人是否生病,醫生就會根據病人的心跳、症狀等(已知條件)來判斷病人是否生病(某事件的發生機率),貝氏定理公式如圖六所示,若想更進一步理解Naive Bayes 請點此。
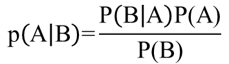
Naive Bayes舉例
小明是一位醫生,他在某天上午收了六位病人,病人的詳細症狀、職業、疾病如圖七所示,而現在來了第七位病人,這位病人是一個症狀為發燒的資料科學家,小明想透過 Naive Bayes 了解他患上流感的機率有多大?
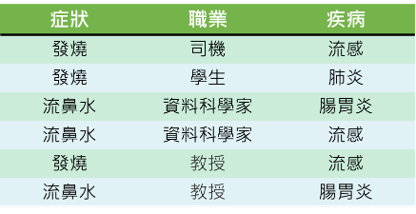
根據貝氏定理,可寫出式(一),而 Naive Bayes 假設變數之間互相獨立,因此又可以整理成式(二),剩下的資訊則可以透過圖五計算出來,如式(三),藉此就可以知道這位病人患上流感的機率為0.66。

調參
調參所指的是調整模型的超參數(Hyperparameter),其用意在於找到一組超參數以提升模型的效能。在此階段會有兩部分的參數需要調整,分別為系列二所提到的 TfidfVectorizer 的參數以及本篇所提到的三個模型的參數。
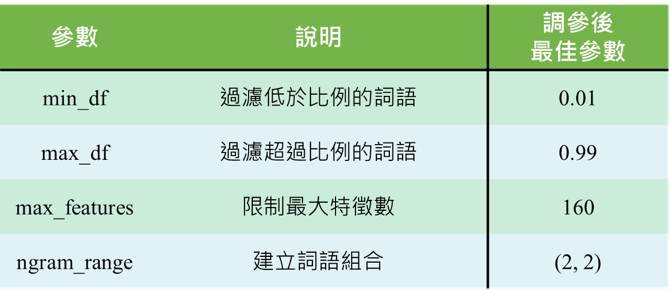
首先,先來看看 TfidfVectorizer 的參數介紹以及調參後的結果,如圖八所示:
接著是上述所介紹三個機器學習模型的調參,在此我們會運用到 scikit-learn 的調參套件來進行調參,步驟如下所示:
- 先利用 RandomizedSearchCV 得到效能尚可的參數,藉此縮小範圍:
RandomizedSearchCV 結合了隨機搜尋超參數以及交叉驗證這兩個方法,也就是從給定的範圍中隨機挑選超參數進行模型訓練,再利用交叉驗證的方式找出平均效果最好的超參數。 - 再利用 GridSearchCV 仔細尋找能使效能最好的超參數:
和 RandomizedSearchCV 不同的是,GridSearchCV 會遍歷給定的範圍,也就是利用排列組合的方式,嘗試每一種組合,再利用交叉驗證的方式找出平均效果最好的超參數。
看完調參步驟後,就來看看各模型的參數介紹以及調參後的結果。
Logistic Regression 參數介紹及調參結果
如圖九所示:

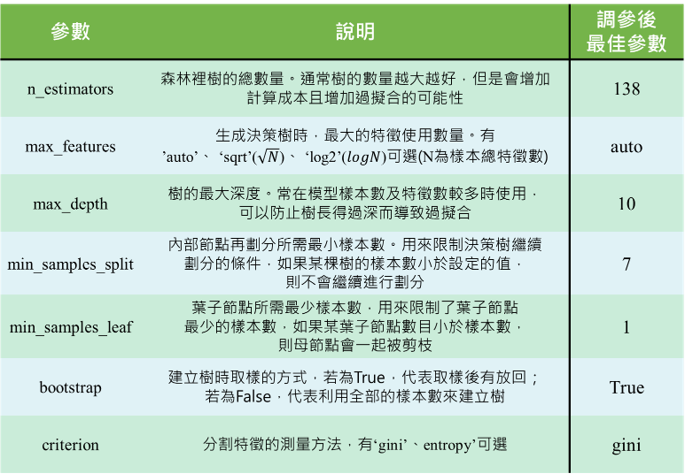
Random Forest 參數介紹及調參結果
如圖十所示:
Naive Bayes 參數介紹及調參結果
如圖十一所示:

預測結果
以下為三個模型在訓練集和測試集的準確率(accuracy)的分析:
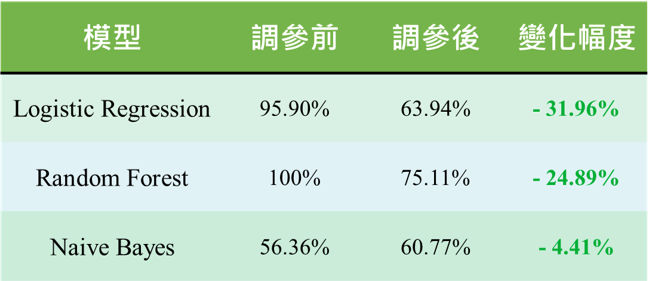
訓練集結果
如圖十二所示:
測試集結果
如圖十三所示:
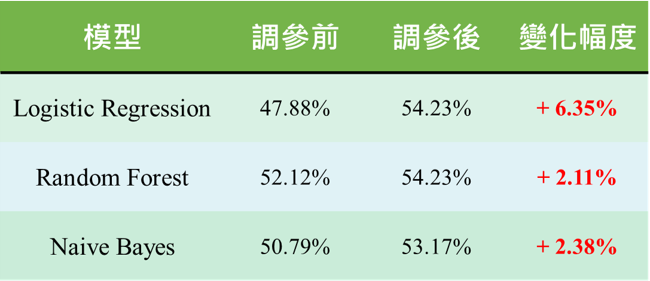
- Logistic Regression:雖然在調參後訓練集的準確率下降,但是測試集上升的幅度最多,甚至是表現最好的模型。
- Random Forest:調參前訓練集的準確率為100%,測試集卻只有52.12%,有可能是樣本數太少(約1600筆)而產生過擬合,不過在調參後有解決這項問題。
- Naive Bayes:在調參過後準確率微幅上升。
- 三個模型在測試集的準確率皆有上升,而其中又以 Logistic Regression 上升的幅度最大。
程式碼來源:臺灣行銷研究Github
我們從準確率的角度理解了本文章所有模型的好壞,那… 預測出來的「報酬率」呢?
以上就是本篇機器學習建模的內容,雖然三個模型的準確率皆不是相當優異,不過在下一篇文章中,我們會帶入實際的數字,看模型的報酬率是否有比隨機買賣還要佳,有興趣的讀者千萬不要錯過!
作者:蔡尚宏(臺灣行銷研究特邀作者)、劉睿哲(臺灣行銷研究特邀作者)、鄭晴文(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究有限公司創辦人)
參考資料
[資料分析&機器學習] 第3.3講:線性分類-邏輯斯回歸(Logistic Regression) 介紹
通俗地說邏輯回歸【Logistic regression】算法(二)Learning Model
Random Forest
Python機器學習實踐:隨機森林算法訓練及調參
樸素貝葉斯分類器的應用 Naive Bayes classifier
機器學習演算法(二): 樸素貝葉斯(Naive Bayes)
scikit learn 官方文件:
Logistic Regression、 Random Forest 、 Naive Bayes、RandomizedSearchCV、GridSearchCV
