此為系列文第二篇
點此回顧 第一篇:透過機器學習預測股市漲跌-基本資料處理
程式碼來源:臺灣行銷研究Github
前情提要
消息面對投資者來說可謂重中之重,任何一微小的風吹草動皆不能放過。無奈的是,大部分投資者無法花費大量時間瀏覽所有可能帶來價格影響的新聞。有鑑於此,筆者因此希望能透過機器學習以資料科學的角度掌握新聞標題對大盤的走向。以下筆者將使用Reddit World News當日前25名熱門的新聞標題作為示範處理資料。
資料處理
於系列文第一篇中,我們已經對原始資料分別做了以下五點處理
- 將所有字母轉為小寫
- 刪除數字、標點符號
- 去除英文字母
- 去除停用詞
- 詞幹提取與詞形還原
上述處理步驟已大致將原始資料整理乾淨,但在將字詞以個別獨立的狀態切分後,可能會忽略處理縮寫的情況,例如:United States 簡寫為 U.S.; 也可能忽略片語或是連續出現時有特殊含意,例如:nuclear power、United States 等字詞之處理。下文將深入描寫如何運用縮寫還原技巧、n-gram 切字方法來處理上述特殊情形,並應用 Scikit-learn 套件底下之 TfidfVectorizer 函數處理原始資料。
縮寫字詞的處理
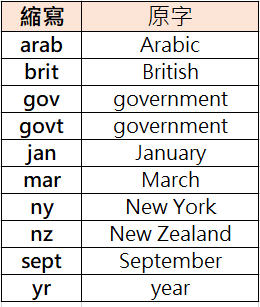
針對原始資料某些字詞以縮寫形式呈現,如 United States 簡寫為 U.S. 之情形,我們必需將這些縮寫還原回其原本型態才能在後續建立模型階段取得更好的表現。此處筆者參照 Oxford English Dictionary 所提供之縮寫表與原始資料對比,最終整理出原始資料中所出現過的縮寫字詞轉換表並加以對照還原,如圖一所示。
片語 & 連續出現時產生特殊含義之詞彙的處理
針對此類情況,筆者採用 n-gram 作為解決方式。
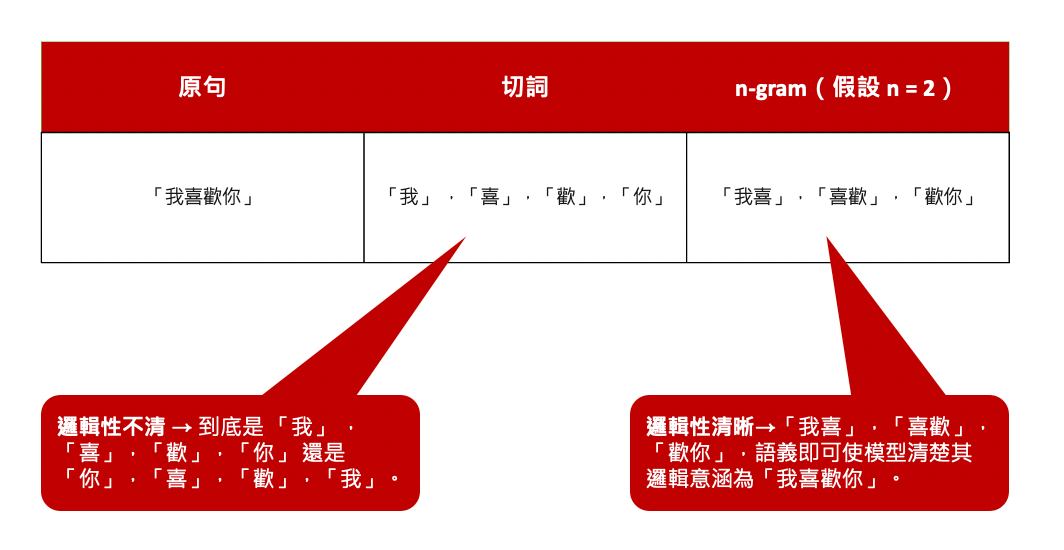
n-gram 是一種在進行 nlp (自然語言處理)時經常使用到的處理方法。簡單來說,n-gram 是一種將句子以不同長度切分為各個字詞的方法,n 即代表每次的切分長度。例如 「我喜歡資料科學」 在 n = 1 的情形下會切分為 「我」 ,「喜」,「歡」,「你」……以一個字為單位的形式; 假設 n = 2 ,即會切分為「我喜」,「喜歡」,「歡你」,……的形式,以此類推。除此之外,一般在進行資料分析時,遇到如「我喜歡你」 此種因順序不同而具不同意義之句子時往往無法判讀其真實語意,而運用 n-gram 即可透過 「我喜」,「喜歡」 等不同欄位來釐清原句語意。往後我們遇到原始資料中有四字成語、三字聯詞或兩字片語的情形,也可以分別利用 4-gram 、3-gram、2-gram 將這些詞彙切分出來,如圖二所示。
TfidfVectorizer套件
上述我們已完成建立機器學習模型前所需之資料清洗。接下來,我們必須從原始資料中所切分之所有字詞挑選出較具有顯著意義的字詞,減輕一些過於氾濫或過於稀少的字詞權重,並加強具顯著意義字詞的權重以試圖增益機器學習模型的預測準確性。此處我們使用 Scikit-learn 套件底下之TfidfVectorizer 函數為我們進行字詞權重的分配。TfidfVectorizer 是一個基於 Tfidf 指標所開發出的字詞處理函數; 而 Tfidf 則是一種考量各字詞在原始資料中的密度、稀少性、頻率後將字詞給予權重評分的一個指標,具體公式如圖三所示。
(如想了解更多 Tfidf 的應用,可以參考此篇文章:行銷定價新型態:即時動態定價策略與實做(附實現程式碼)

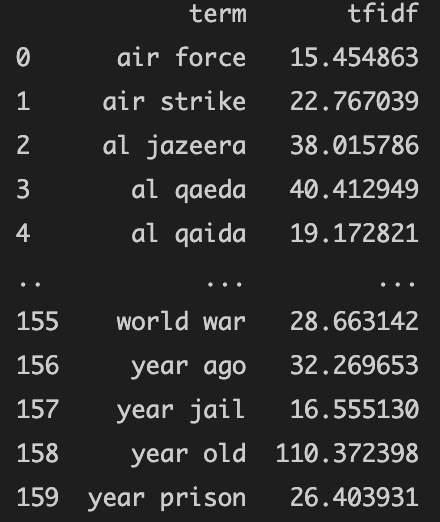
TfidfVectorizer 能讓我們輕鬆將原始資料進行 Tfidf 指標評分。好消息是,TfidfVectorizer 除卻能夠調配 Tfidf 權重過高或過低之字詞,也支援一併進行 n-gram 處理。因此我們只要使用 TfidfVectorizer 即可將原始資料以快速地將原始資料進行 n-gram 處理並給予各字詞 Tfidf 的權重分數,如圖四所示。

至此,我們已將所有資料處理步驟完成,如圖五、六所示!
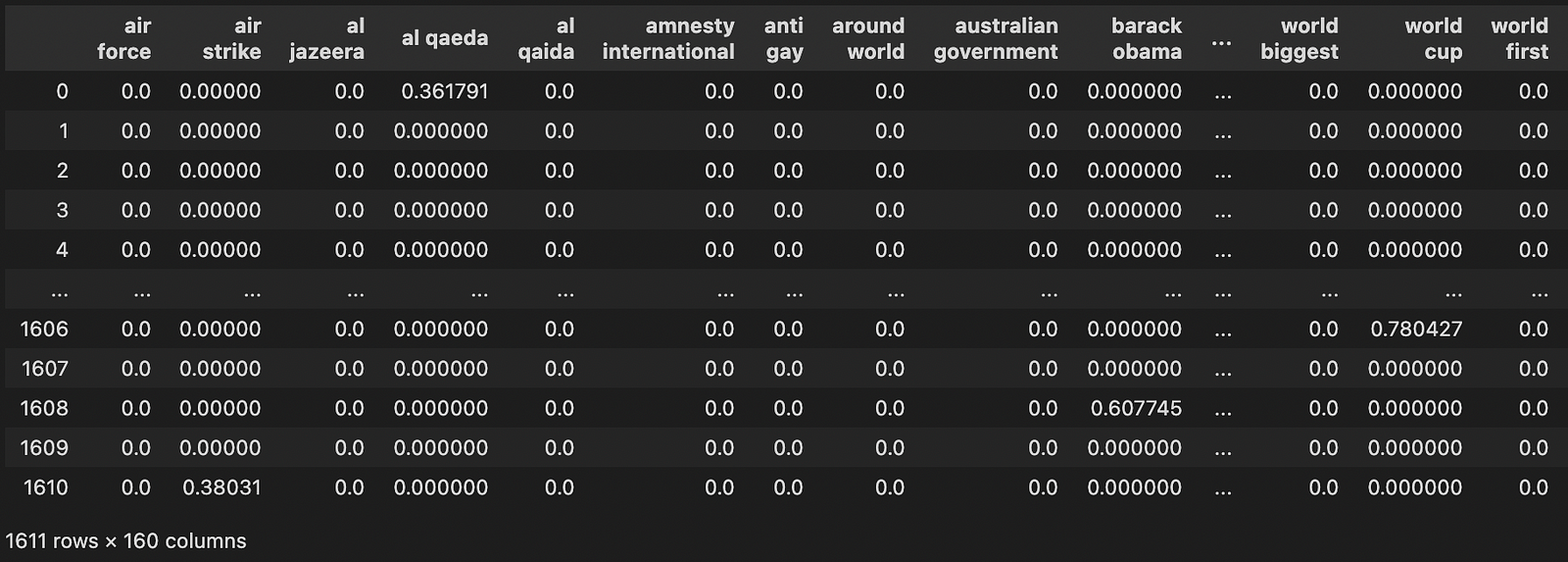
資料處理完成了! 然後呢?
在下一篇的內容中,我們會使用羅吉斯線性迴歸、隨機森林、貝氏分類器三個機器學習模型將本文處理後的資料執行預測性建模。具體步驟將會在第三篇文章詳述,有興趣的朋友千萬不要錯過!
如果本文章讓你獲益良多,別忘記給我們一些 claps!
作者:蔡尚宏(臺灣行銷研究特邀作者)、劉睿哲(臺灣行銷研究特邀作者)、鄭晴文(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究創辦人)
參考資料
Daily News for Stock Market Prediction :
Oxford English Dictionary:
