
情境
在股票市場中,即時的消息對於投資者而言至關重要,為判斷股市漲跌的因素之一。注重消息面的投資者,會時常花費大量時間觀看新聞,以了解有關公司的資訊,或是整體金融市場的趨勢,才能把握住良好的投資機會。然而,全球各家新聞媒體一天發布的新聞總數動輒上百則,若要看完全部的新聞恐會耗費不少時間,因此希望能透過Reddit World News當日前25名熱門的新聞標題,預測道瓊工業指數的股價漲跌及幅度,以掌握大盤的走向,如圖一所示。
由於多半投資者非專職於投資,僅能利用零碎時間關心股市,然而,每日新聞數量眾多,「如何在有限的時間內掌握新聞,並加以預測股市走向進行投資」是當今投資者時常面臨的問題。若能將機器學習應用在預測股市,不僅能節省投資人瀏覽新聞的時間,亦能避免市場在漲時衝動跟風,或是錯過市場跌時的買入時機,免於成為別人收割的韭菜。
整體概況已幫讀者整理好,如圖二所示。

模型建立步驟
在開始進行資料分析前,圖三為我們的模型建立步驟,我們將會依照此順序進行資料處理及建置模型,本文為此系列文的第一篇,首先會簡介資料集的內容與格式,並說明如何處理每日精選的新聞標題,欲知詳情就繼續看下去吧!

資料前處理
對文本進行數據分析時,為了確保資料品質一致,常會花費大量時間進行資料前處理,例如:將資料標準化、去除非文本的部分、檢查拼字等,以提升資料的品質,進而增進模型的準確度,避免垃圾進、垃圾出的情形,因此資料前處理是不可或缺的步驟!
資料說明
原始資料共有3個資料集:
- reddit news:含有新聞發布的日期,及新聞標題,每日共記載25則新聞。如圖四所示。

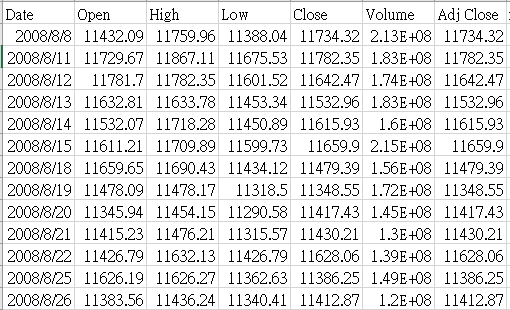
2. DJIA:包含日期,以及道瓊工業指數每日的開盤價、最高價、最低價、收盤價、成交量。如圖五所示。
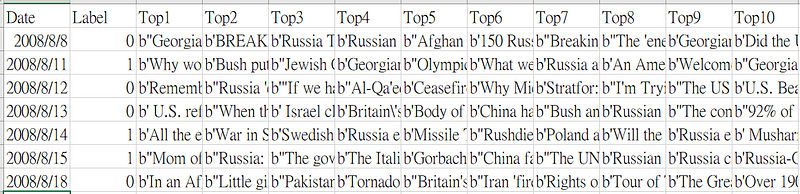
3. 合併資料集:記載日期、當日道瓊工業指數為漲(1)或跌(0),與Reddit news上當日最熱門的25則新聞標題(此指欄位名稱為「Top1」至「Top25」)。如圖六所示。
在了解完各個資料集的結構後,便可開始進行資料前處理,同時,這邊也附上Python的程式碼供大家參考,連結將放置於底下。
程式碼來源:臺灣行銷研究Github
資料前處理
本次資料處理的目標是運用新聞標題預測道瓊工業指數的漲跌,首先得處理新聞標題,將資料標準化,包括以下五個步驟:
- 將所有字母轉為小寫
為了將資料標準化,利於後續模型判讀字詞,我們使用 lower()將字母皆轉為小寫。如圖七所示。

2. 刪除數字、標點符號
由於本篇主要為分析新聞中的英文字詞對股市漲跌的影響,數字及標點符號在此我們先運用 re.sub()刪除,並將英文字母保留。如圖八所示。
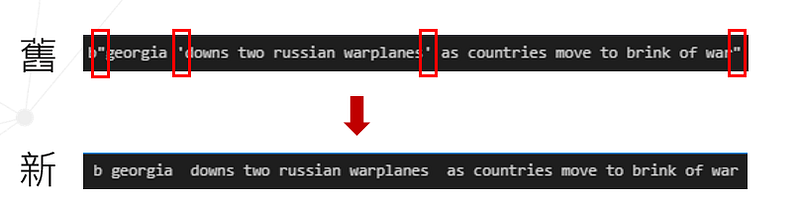
3. 去除英文字母
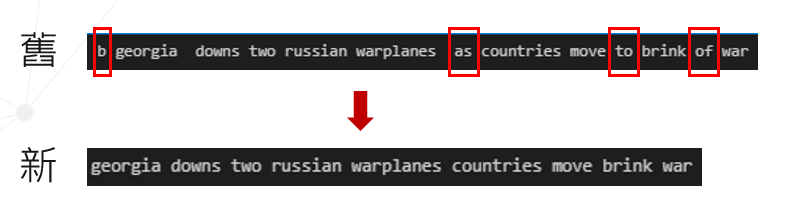
由圖八可觀察出每句新聞標題前方都有”b”,卻無任何意義,故運用 string.ascii_lowercase將英文小寫字母整理出來,再將它們納入停用詞中,並配合第四步驟。
4. 去除停用詞
停用詞指的是a、the、is、in等英文中常見的詞,這些詞語通常對理解整個句子的語義影響較小。我們透過 stopwords.words('english')得出英文中常見的停用詞,再將他們及第三步驟提及的英文字母一併去除。如圖九所示。
5. 詞幹提取與詞形還原
英文的名詞有複數型態,動詞則有過去式或進行式等,為了使單字標準化,利於模型計算單詞出現的次數,我們使用 WordNetLemmatizer()將字詞變回原形。以圖十為例,現在我們欲統計 「move」 在文本中出現的次數,文本中可能會出現「moves、moving、moved」等型態,若未進行詞幹提取與詞行還原,模型便會將上列三者認為是不同的字詞。因此我們得將字詞還原,使模型有效統計每個字詞出現的總次數,以利於後續的預測。

然後呢?
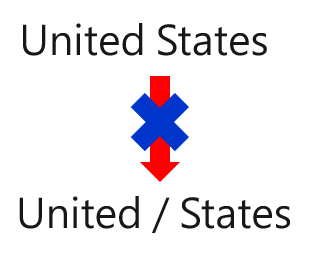
經由上述的資料處理步驟,我們已經完成了預測前的基本資料處理,然而現在字詞都是個別獨立的狀態,可能忽略了片語或是連續出現時有特殊含意,例如:nuclear power、United States(如圖十一所示,United States不可分為United和States兩個獨立的字詞)等,以及縮寫的情況,例如:United Stated簡寫為U.S.,這些部分都是尚未考慮進去的因素,可能會影響到後續使用機器學習模型的成效。因此下一篇文章將會繼續講解進階的資料處理步驟,讓各位讀者瞭解如何透過經典且進階的自然語言處理手法,為每一個文字分配重點權重,為後續機器學習模型預測股價的漲跌鋪好道路!欲知詳情,請待下回分曉~
參考資料
Daily News for Stock Market Prediction : https://www.kaggle.com/aaron7sun/stocknews
作者:蔡尚宏(臺灣行銷研究特邀作者)、劉睿哲(臺灣行銷研究特邀作者)、鄭晴文(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究創辦人)
