當Python遇上二八法則-以電商服飾產業為例
「二八法則」是行銷人朗朗上口的行銷應用法則。但是要如何將此法則應用於實際的行銷操作呢!?
本文我們將實際使用操作python分析電商服飾資料,和大家分享應用過程及結果。

本次的服飾案例商品種類繁雜,本文先和大家分享一下何謂資料之間的「階層關係」?
在大賣場購物時,賣場為了方便客戶尋找商品,會進行區隔分類,並進行排序,如:大賣場有「日用百貨區」、「生活休閒區」、「生鮮區」等區域,而在「日常用品區」區域中又分成「衛浴用品」、「餐廚配備」等類別,其中「衛浴用品」細類別中又可分成「浴巾」、「浴帽」等商品項目。在大賣場的例子中,「階層關係」是「區域(日常用品)」>「類別(衛浴用品)」>「商品項目(浴巾)」。如圖1所示。
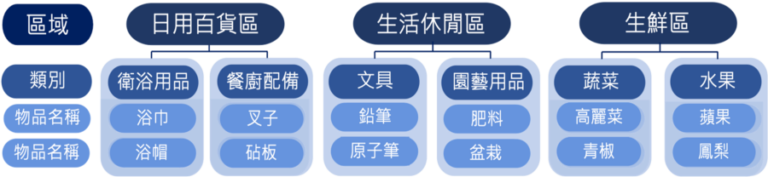
案例情境簡要說明
本次的案到資料之間也具階層關係,大家可以想像一下,第一階層是「溫馨主題」,第一層「溫馨主題系列」之下有第二層「產品種類」,例如有帽T、衣服等;接著第三階層則是「產品名稱」,隸屬於「產品種類」之下,例如叫「溫馨家庭組」、「溫馨送禮組」,所以我們就可以歸類出之間的大小關係,主題 >產品類別>銷售產品名稱。
了解完這層層的資料結構與型態後,我們可以正式進入資料分析!
一、 讀取資料
我們先讀取資料,接下來看資料維度以及查看變數有哪些。具體程式碼與資料細節可以參考本 jupyter notebook
程式碼1:
#讀取資料all_data = pd.read_csv('new_salesdata.csv')產出,如圖2所示:
二、資料分析
在資料讀取進來後,可以開始思考一下,這些資料可以帶給我們什麼洞見呢?
舉例來說:客戶會為了要搭配其他的服裝,所以許多時候在購買該產品周邊服飾時會考慮產品的顏色。若我們能從資料中分析出利潤供獻最高的顏色,在開發新品或與合作夥伴一起搭售新品時,就可以優先考慮最暢銷的前五種顏色!
程式碼2:
# 將不同顏色的利潤分別加總color_data = all_data.groupby('顏色', as_index= False)['利潤'].sum()# 依照大小排序color_data = color_data.sort_values('利潤',ascending = False)color_data.iloc[:5]產出,如圖3所示:
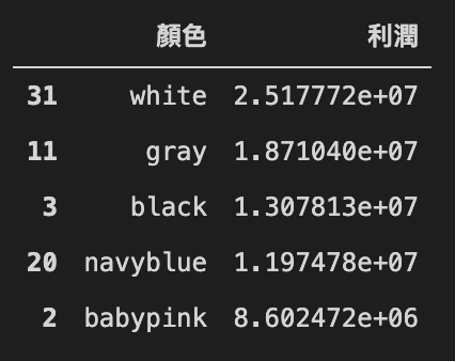
由結果我們可得知最暢銷顏色前五名分別為百搭色白色、灰色、黑色與海軍藍、嬰兒粉,但若做成圖表會更清晰易懂!
程式碼3:
color_fig = px.bar(data_frame = color_data,x = '顏色',y = '利潤',title='2019年各顏色利潤排序長條圖' ,color = '利潤',)plot(color_fig, filename='2019年個顏色利潤.html')
產出,如圖4所示:
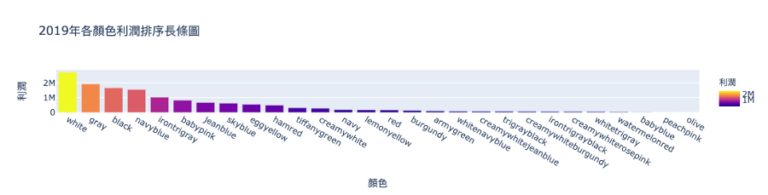
然而,在此資料中,影響利潤最主要的因素是「系列」,利潤貢獻通常是企業在評估產品經營優劣的重要指標,也是提供決策者在是否投注資源的重要參考。若能找出利潤貢獻最高的系列,企業便能投注更多的資源於此系列上。最簡單的利潤計算方式為「單價」-「成本」。因此,我們將單價減掉成本,並創造出一欄「利潤」。
程式碼4:
# 計算利潤all_data['利潤'] = all_data['單價'] - all_data['成本']
產出,如圖5所示:
接著,我們可以利用groupby函式將各「系列」的利潤「分別」總和,結果可以看到每個系列的利潤都被分別計算出來。
程式碼5:
# 將「各系列」的利潤「分別」總和,profit_data = all_data.groupby('系列', as_index = False)['利潤'].sum()產出,如圖6所示:
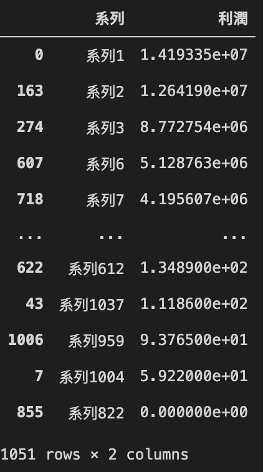
但!根據上述表格,我們很難一眼明瞭哪個系列的利潤最高,所以我們可以使用plotly套件將「系列」與「利潤」做成動態長條圖,一目瞭然全系列的獲益多寡。最後,儲存成html檔以利展示。
程式碼6:
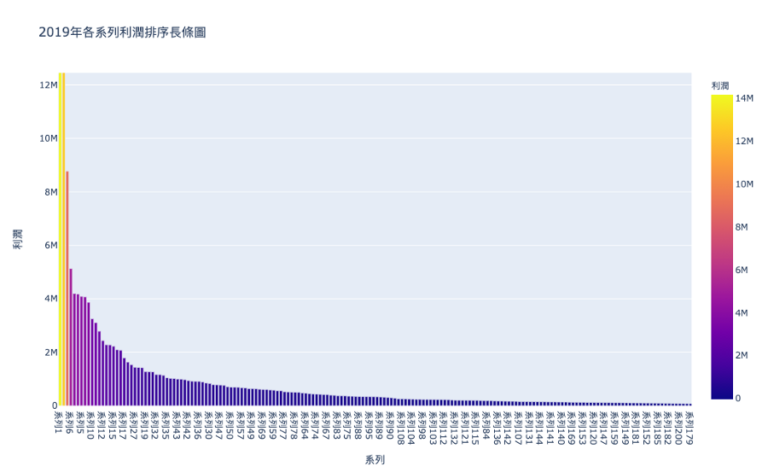
#使用plotly製作「2019年各系列利潤」的長條圖fig = px.bar(data_frame = profit_data,x = '系列',y = '利潤',title='2019年各系列利潤排序長條圖' ,color = '利潤')#儲存此圖為html檔plot(fig, filename='2019年個系列利潤.html')
產出,根據結果顯示,我們可以清楚地看到前面系列產生的利潤遠高於其餘系列,且其餘系列的利潤貢獻非常些微,如圖7所示。
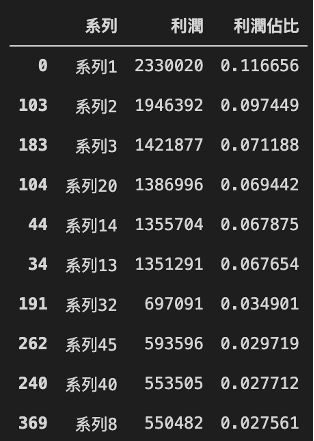
那我們要如何知道哪些系列真正貢獻了利潤呢?我們可以利用.sort_values函式讓「利潤佔比」依序從大排到小,並且找出貢獻了前十名利潤的系列。
程式碼7:
# 計算每個系列的利潤在總利潤的佔比profit_data['利潤佔比'] = profit_data['利潤'] / profit_data['利潤'].sum()# 將「利潤佔比」依照大小排順序profit_data = profit_data.sort_values('利潤佔比', ascending = False)# 找出利潤「前十名」
top10_profit = profit_data.iloc[0:10]產出,如圖8所示:
然而,事實是如此嗎?
除了得知貢獻前十名利潤的系列之外,我們可以驗證所謂的「二八法則」是否正確。在企業營收的結構中,我們常聽到「二八法則」或是「20/80法則」這個詞彙,「二八法則」源自為學者Pareto當時發現義大利 20% 的人口,擁有全國 80% 的財產,進而衍伸到商業應用。商業上的「二八法則」多是百分之八十的利潤由前百分之二十的產品所產生。
驗證一下吧 !!
利利用.cumsum()函式創建一欄「累積利潤佔比」將「利潤佔比」依序累加,且篩選出「累積利潤佔比」前百分之八十的系列。結果可以看出,前67個系列就佔了百分之八十的利潤。
程式碼8:
#「累積利潤佔比」= 「利潤佔比」累加profit_data['累積利潤佔比'] = profit_data['利潤佔比'].cumsum()# 找出「前百分之八十」的利潤主要是由哪些系列貢獻profit_data_cumsum80 = profit_data[ profit_data['累積利潤佔比'] <= .8 ]# profit_data_cumsum80的資料結構profit_data_cumsum80.shape
產出:
(67, 4)
我們可以再進一步分析,這25個系列在全部系列產品中的佔比。結果約為0.06,也就代表6%的商品貢獻了百分之八十的利潤。這樣的分析果對於實務應用可以作為有限資源下,可以建議企業多投注資源或推廣這6%的產品,或是縮減其它商品的預算成本;或是加強這6%相關產品的後續開發,創造更大的市場需求。
程式碼9:
# 找出創造「前百分之八十利潤」的系列佔總系列的比例len(profit_data_cumsum80) / len(profit_data)
產出:
0.06234413965087282
以上就是今日「二八法則」的行銷操作分享~希望對大家會有幫助!
若是喜歡我的文章可以給我拍拍手,給我多一點動力!!
作者:葉庭妤(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究創辦人)
更多實戰案例及情境好文推薦
視覺化財經數據,挖掘資料金礦 — 以美國投資基金公司為例
視覺化財經數據,挖掘資料金礦 - 以美國投資基金公司為例 情境 電影《華爾街之狼》中有一句話「在太陽升起之前,就投資了太陽的股票!」完美詮釋
我的競爭優勢? 視覺化口碑定位雷達圖輕鬆搜出來!(附實現程式碼)
我的競爭優勢? 視覺化口碑定位雷達圖輕鬆搜出來!(附實現程式碼) 企業競爭者的調查方式 vs 網路特性 企業的品牌以及形象,是企業一向非常重
玩轉 Notion AI 一鍵搞定職場兩大常見情境!一鍵搞定(II):知識歸納與文件翻譯
玩轉 Notion AI 一鍵搞定職場兩大常見情境 一鍵搞定(II):知識歸納與文件翻譯 玩轉 Notion AI 一鍵搞定職場兩大常見情境
